 復盤2024,大模型的商業化主線是什么?
復盤2024,大模型的商業化主線是什么?

過去一年,AI是全球資本市場的投資主線,而商業化,則是AI大模型的主線任務。
一句話總結2024年大模型的商業化進展,或許是冰火兩重天。一方面,我們看到了許多成功的AI付費用例,小到9.9一套的AIGC寵物寫真,200美元的ChatGPT Pro月費,大到百萬一臺的大模型一體機,C端/B端市場行情看起來一片火熱。
但從整體營收情況來看,海內外模廠仍然承壓。2024年,多個海外AI創企和部分AI六小虎成員,都傳出過停止預訓練、尋求賣身等消息。類Sora模型、類o1模型都屬于高算力消耗、少商業用例、高付費門檻,不少模廠在積極跟進新技術路線的同時,商業化危機也一直如影隨形。
冷熱交替使AI領域新聞不斷,也帶來了前所未有的喧囂。我們就趁著年尾來整體復盤一下,通過三個行業故事,回看2024年大模型商業化主線究竟是什么?

GPT-5最終還是缺席了2024,但也無人在意。或許技術人員還是在意的,但用戶和企業確實對第一時間追趕OpenAI最新模型,不再興致高昂了。這種氛圍,跟年初大家迫切希望跟進對標Sora的心情,形成了較大的反差。

而模型界的新神,變成了國內創企DeepSeek。有的海外機構專門將DeepSeek的中文報道翻譯成英文,來更多了解這家中國公司。而這家AI企業,以超高性價比著稱,別稱“AI界拼多多”。2024 年 5 月,DeepSeek V2發布,將計算量和推理成本降到極致,成為國內token價格戰的導火索;年底發布的DeepSeek V3,據說模型性能超越GPT-4o,在Chatbot Arena大模型排行榜上排名第7,是前十名唯一的開源模型,且僅用了600萬美元。
可以說,2024年,API市場的關注重點,從TOP模型變成了智價比。

2024年,大家對AI訂閱費的接受度越來越高,最能證明這一點的是越來越貴,也越來越多的AI訂閱會員被推向了市場。
比如,OpenAI在12月發布會上推出的ChatGPT Pro,每月收費200美元,仍然吸引了不少科技博主愿意買單。AI編程平臺Devin,更是將月付費門檻拉升到了500美元。
也許你會說,程序員本身就是高工資,愿意為AI付費很正常,但普羅大眾為AI應用買單的也不少。
一位國民級中文APP的負責人向我們提到:都說國人現在不愛消費了,但我一直沒有感覺到,我們的產品在AI化后,付費率有幾十倍的增長。其中,面向家長的智能繪本,面向職場人生產力的AI PPT生成、報告精讀、腦圖生成等效率工具,都是付費的高頻場景。
為AI一擲千金的同時,用戶也不再把雞蛋放在同一個籃子里(OpenAI、谷歌主導的TOP模型),開始圍繞場景搭配產品方案的“組合拳”。
比如一個程序員在開發場景中,可能會同時購買Cursor、sonnet、Claude、anthrope等多個平臺的月費會員,搭配起來使用。一個媒體人在創作場景中,會同時指揮kimi、文心一言、豆包和DeepL等多名“AI員工”,我本人還會用騰訊元寶來精讀論文,生成腦圖。
總結一下訂閱用戶的心態就是,不是頭部模型用不起,而是多個模型更有智價比。

2024年,我采訪一個數據公司,對方告訴我:2023年為了第一時間擁抱AI,那時候正是啥都最貴的時候,買卡花了很多錢,然后開始找模型廠商做訓練,又花了很多錢,今年堅決不升級(大模型)了,就用著以前的。
一位AI應用創業者,為了使用o1 pro模型充值了ChatGPT Pro的會員,結果發現并不比o1或4o優秀得很明顯,于是決定不會再續費了。
還有一個AI創企,用GPT4-Turbo測了一下非代碼場景調用,結果出乎意料地燒錢,公司根本扛不住這個訓練費用,又沒有找到合適的商業模式,無法把成本轉嫁給客戶,趕緊切換回了更低版本的GPT3.5,只有實在跨不過去的坎,才會考慮GPT4。

“低版本模型的能力再弱,通過各種組合拳帶來額外latency,也好過新版本模型一次性latency。”更何況,很多場景先進模型一次性也搞不定。
第一批入局大模型的企業用戶,折騰了一年之后,2024年更為看重成本與收益的平衡,不再盲目為更大的參數規模、更高的計算開銷而買單。2024年才入局的企業,對AI的態度自然就更加謹慎、注重風險控制,更希望以最小的投入獲得最大的智力回報。
所以,在ToB政企市場,大模型價值的縮水速度開始放緩了。一個新模型推出之后,舊模型不會被輕易翻篇或完全顛覆,可以通過工程化等手段繼續在業務中使用。這種變化,意味著大模型算法作為一種軟件技術,不會很快過時,作為一種企業的數字資產,有了更長的有效使用周期,也就有了更高智價比。

從上述三個故事,不難得出一個結論:智價比,是大模型2024的商業化主線。為什么這么說?
模型層面,商用不再“規模至上”。
Scaling Law規模法則疑似撞墻的說法開始流行,新模型的性能提升與計算消耗不成比例,投入回報比日漸拉胯,學術界和產業界的質疑聲增多了。同時,其他技術路線的探索,開始有了成果。
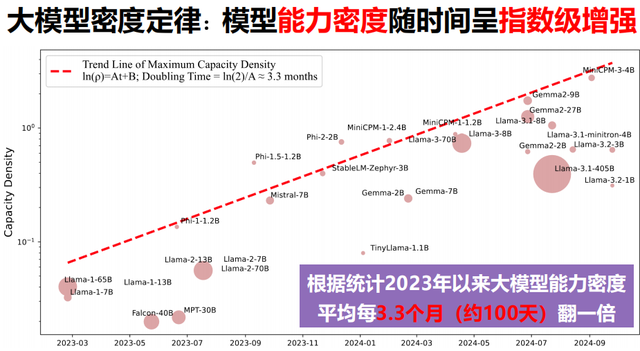
比如DeepSeek對模型架構進行了全方位創新,推理成本下降的同時也能確保模型性能;面壁智能提出了“能力密度”(Capacity Density)概念,用更少的資源實現更強的能力,來實現AI技術的可持續發展;OpenAI也拿出了經過強化微調的o1-mini模型,比標準版o1的推理速度更快、計算消耗更低。
除了模型規模,智價比、易用性、服務水平、生態支持度等其他維度,開始被商業用戶納入度量。
市場層面,從“交付大模型”到“交付智能”。
三個故事中,API看榜單也看智價比,訂閱制用組合拳來達到最佳效果,項目制追求整體收益平衡,無不說明大模型商業化已經走過了“交付大模型”的第一階段,進入到“交付智能”的第二階段,用戶和企業不再為了嘗鮮而用模型,而是在越來越多的具體的任務場景中,讓AI大模型發揮出實際效益。因此,對大模型的選擇與付費意愿也開始出現分化。
比如簡單的任務場景,用更低版本、免費的模型+提示詞,就能很好地完成;而復雜的任務,可能GPT-5來了都不能解決問題,那么智價比+工程化組合拳更值得投入。
尤其是一些大型政企,如果大模型還沒落地就價值縮水了,是不利于資產評估的,所以要么與硬件整合起來一起,變成“賣盒子”的商業模式,要么延長模型的有效使用周期,提高智價比。
正如Anthropic的首席產品官Mike Krieger所強調的:“你不僅僅是在交付產品,你在交付智能。”如果說大模型是算力土壤上的一棵植物,智能就是果實,商業用戶購買的其實是果實。
商業用戶的付費決策,不單純取決于植物是不是果園里最高最靚的,而是由購買便捷度、配送物流、時效性、適口性等綜合決定的。舉個例子,ChatGPT剛問世時,二手市場代注冊賬號、海外信用卡都成了一門生意,這種格外費勁的使用方式,隨著國產大模型的充盈,很快就銷聲匿跡了。從綜合體驗上來看,“智價比”更能反映大模型的核心價值。
智價比,可以說是2024大模型商業化的主線。

從“交付大模型”到“交付智能”,2024年也是大模型廠商的分水嶺。
能夠更好、更充分交付智能效果的大模型,獲得了更顯著的發展機會。其中,云底座支撐的大模型家族,憑借從底層算力到開發套件到AI應用及商業生態的全鏈路支持,發展尤其強勁,比如百度智能云+文心一言、華為云+盤古大模型、火山引擎+豆包大模型、阿里云+通義千問、騰訊云+混元大模型。

而AI創企中,模型性能與成本比例更優的智譜AI、DeepSeek,發展勢頭更加強勁。而不打價格戰的零一萬物,在競對面前缺乏智價比,又無法通過底層技術創新避免“流血式降價”,C端/B端難以打開局面,經營上就遭遇了波折。

2024年,是“交付智能”的智價比元年,那么在2025年,我們還能期待大模型市場的哪些變化呢?
第一,大模型“果林”的穩定生長。這體現在智能邊界在擴大,低性能有增長,高性能沒有大退步,格局進入穩定態。先進模型和低版本模型、大廠TOP模型和中小廠“拳頭模型”會在不同的任務場景中各美其美,都能獲得一定的商業化陽光和雨露,組合生長。這對于大眾小廠來說,可能都是競爭壓力減小的好消息。
第二,多模態大模型的“榕樹”崛起。2024年,為了應對不同場景,模廠都推出了十分復雜的大模型家族,比如OpenAI的GPT系列、4o系列、o系列,讓人傻傻分不清楚,不同任務需要切換多個模型一起協作才能完成。單一模型的能力邊界小,阻礙了AI提高生產力。因此,更高智價比的方案,肯定是走向多模態模型,讓用戶可以專注在一個模型上,就能完成文本、圖像、音視頻等輸入和輸出,成為讓用戶棲居的一顆“榕樹”,更可能在云廠商肥沃的算力土壤上生長出來。
第三,超級個體(小微AI創企和個人開發者)的進一步豐盈。進入智價比階段,個體從平臺上得到的智力加持會增大,門檻成本會降低。所以不難預測,以超級個體組成的小微AI創業企業和開發者,將會成為涌入AI應用創新的一股潮流,帶來的將是個性化AI定制軟件和AIGC內容創作的極大爆發。這些超級個體如同蜂鳥,會將智能的種子采擷、散播到更多行業領域,尤其是長尾場景。
從這個角度看,智價比更高的國產AI生態,有望以更低成本推動 AI 技術普惠和行業智能化發展,解鎖大模型商業化的速度也會比想象中更快。
經歷過2024的智價比元年,大模型正在迎來草長鶯飛的2025。

審核編輯 黃宇
-
AI
+關注
關注
87文章
31293瀏覽量
269644 -
大模型
+關注
關注
2文章
2514瀏覽量
2929
發布評論請先 登錄
相關推薦
免費時代到來!價格戰帶領AI大模型走出商業化困局?
“全球 Robotaxi 第一股” 文遠知行:榮登 2024 中國無人駕駛商業化先鋒 TOP10


星閃技術2024年商業化落地成果顯著
百川智能發布一站式大模型商業化解決方案
揚帆出海!穩石氫能AEM電解槽出貨智利,開啟全球商業化新篇章!

蘿卜快跑爆火的背后,美格智能如何助力無人車商業化?
蘿卜快跑爆火的背后,美格智能如何助力無人車商業化?

大模型應用商業化落地關鍵:給企業帶來真實的業務價值

聯想上海交大聯合發布全球首款商業化高亮不銹鎂合金材料
文遠知行與聯想車計算戰略合作,推進自動駕駛商業化落地
數勢科技攜手書亦燒仙草,引領大模型商業化落地






 工商網監
工商網監
評論