

近期,DeepSeek 已成為各行業(yè)關(guān)注的焦點(diǎn)。其卓越的語(yǔ)言理解和生成能力使其能夠精準(zhǔn)處理各種復(fù)雜的自然語(yǔ)言任務(wù),無(wú)論是文本生成、語(yǔ)義理解還是智能對(duì)話,都能輕松應(yīng)對(duì)。隨著 DeepSeek 的迅速走紅,眾多廠商紛紛加入這一技術(shù)浪潮,積極接入這一強(qiáng)大的語(yǔ)言模型。從互聯(lián)網(wǎng)科技巨頭到傳統(tǒng)制造業(yè)企業(yè),從金融行業(yè)到教育領(lǐng)域,DeepSeek 的應(yīng)用范圍不斷擴(kuò)大,成為推動(dòng)企業(yè)數(shù)字化轉(zhuǎn)型和智能化升級(jí)的重要力量。
在此趨勢(shì)下,越來(lái)越多的企業(yè)開始選擇私有化部署 DeepSeek,以更好地滿足自身業(yè)務(wù)需求。私有化部署不僅能夠滿足企業(yè)對(duì)數(shù)據(jù)安全和隱私保護(hù)的嚴(yán)格要求,還能根據(jù)企業(yè)的特定業(yè)務(wù)進(jìn)行定制化優(yōu)化。然而,在企業(yè)熱衷于私有化部署 DeepSeek 的過(guò)程中,有一個(gè)關(guān)鍵細(xì)節(jié)容易被忽視,那就是網(wǎng)絡(luò)配置。網(wǎng)絡(luò)作為連接訓(xùn)練和推理集群節(jié)點(diǎn)的關(guān)鍵要素,其穩(wěn)定性、速度和效率直接關(guān)系到集群的整體性能。無(wú)論是訓(xùn)練階段節(jié)點(diǎn)間的頻繁參數(shù)同步,還是推理過(guò)程中模型數(shù)據(jù)的快速交互,良好的網(wǎng)絡(luò)環(huán)境都是確保集群通信順暢、高效的必要條件。如果網(wǎng)絡(luò)配置不當(dāng),即使投入了強(qiáng)大的算力資源,也可能導(dǎo)致集群通信性能下降,進(jìn)而影響 DeepSeek 的正常運(yùn)行和業(yè)務(wù)的順利開展。
為此,星融元憑借其在開放網(wǎng)絡(luò)領(lǐng)域的深厚積累,為客戶提供了一套完整的網(wǎng)絡(luò)解決方案。該方案包括 25G-800G 規(guī)格的 RoCE 交換機(jī)及 EasyRoCE Toolkit 等實(shí)用工具,精準(zhǔn)對(duì)接 AI 與大模型領(lǐng)域的網(wǎng)絡(luò)需求,助力客戶在 AI 浪潮中搶占先機(jī),攜手共鑄行業(yè)優(yōu)勢(shì)地位。
網(wǎng)絡(luò)連接方式的升級(jí)
大模型訓(xùn)練過(guò)程中數(shù)據(jù)并行、張量并行、流水線并行是主要的流量來(lái)源,同一服務(wù)器不同GPU、不同服務(wù)器不同GPU之間都需要高效準(zhǔn)確的數(shù)據(jù)傳輸,因此,GPU卡(而非服務(wù)器)為單位的通信模式形成了服務(wù)器多網(wǎng)卡多出口的連接方式,與傳統(tǒng)數(shù)據(jù)中心單一出口連接方式不同。
并行計(jì)算涉及多個(gè)計(jì)算節(jié)點(diǎn)(如CPU、GPU等)協(xié)同工作,以加速大規(guī)模計(jì)算任務(wù)。集合通信庫(kù)是實(shí)現(xiàn)這種協(xié)同工作的關(guān)鍵組件,集合通信庫(kù)提供了高層次的API、屏障(barrier)、集體通信原語(yǔ)(如廣播、歸約等)等同步機(jī)制,用于協(xié)調(diào)節(jié)點(diǎn)之間的執(zhí)行用于在節(jié)點(diǎn)之間傳輸數(shù)據(jù),確保數(shù)據(jù)的快速和可靠傳遞。
NVIDIA NCCL是NVIDIA提供的開源通信庫(kù),是目前大廠主流使用的集合通信庫(kù)。在實(shí)際應(yīng)用中,NCCL和MPI常常結(jié)合使用。MPI負(fù)責(zé)節(jié)點(diǎn)之間的通信,而NCCL負(fù)責(zé)GPU之間的通信,通過(guò)兩者的協(xié)同工作,實(shí)現(xiàn)高效的并行計(jì)算。
NCCL自2.12版本起引入了 PXN 功能,即 PCI × NVLink。取代了原先需要通過(guò)CPU的QPI調(diào)用和CPU進(jìn)行buffer交互。PXN 利用節(jié)點(diǎn)內(nèi) GPU 之間的 NVIDIA NVSwitch 連接,首先將數(shù)據(jù)移動(dòng)到與目的地位于同一軌道上的 GPU 上,然后將其發(fā)送到目的地而無(wú)需跨軌道傳輸,從而實(shí)現(xiàn)消息聚合和網(wǎng)絡(luò)流量?jī)?yōu)化。
- NVLINK :英偉達(dá)(NVIDIA)開發(fā)并推出的一種總線及其通信協(xié)議。NVLINK 采用點(diǎn)對(duì)點(diǎn)結(jié)構(gòu)、串行傳輸,用于中央處理器(CPU)與圖形處理器(GPU)之間的連接,也可用于多個(gè)圖形處理器(GPU)之間的相互連接。
- NVSWITCH :是一種高速互連技術(shù),同時(shí)作為一塊獨(dú)立的 NVLINK 芯片,其提供了高達(dá) 18 路 NVLINK 的接口,可以在多個(gè) GPU 之間實(shí)現(xiàn)高速數(shù)據(jù)傳輸
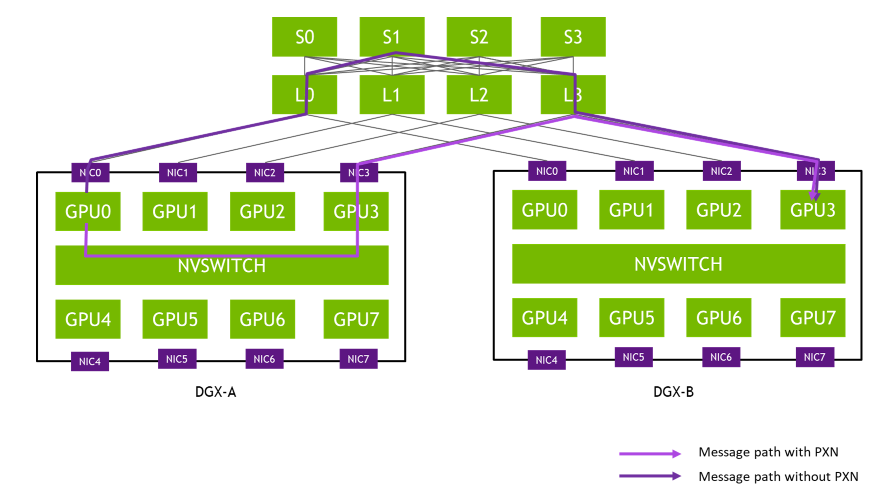
軌道優(yōu)化拓?fù)浼词沁m應(yīng)這一通信特征,將不同服務(wù)器上位于相同位置(軌道)的NIC連接到同一臺(tái)交換機(jī)上。
由于每個(gè)服務(wù)器有8張連接計(jì)算平面的網(wǎng)卡,整個(gè)計(jì)算網(wǎng)絡(luò)被從物理上劃分為8個(gè)獨(dú)立并行的軌道(Rail)。由此,智算業(yè)務(wù)產(chǎn)生的并行通信需求(All Reduce、All-to-All 等)可以用多個(gè)軌道并行地傳輸,并且其中大部分流量都聚合在軌道內(nèi)(只經(jīng)過(guò)一跳),只有小部分流量才會(huì)跨軌道(經(jīng)過(guò)兩跳),大幅減輕了大規(guī)模集合網(wǎng)絡(luò)通信壓力。
軌道優(yōu)化聚合了同一對(duì) NIC 之間傳遞的消息,得以最大限度地提高有效消息速率和網(wǎng)絡(luò)帶寬。反觀NCCL 2.12 之前,同樣的端到端通信將經(jīng)過(guò)三跳交換機(jī)(上圖的L0、S1 和 L3),這可能會(huì)導(dǎo)致鏈路爭(zhēng)用并被其他流量拖慢。
服務(wù)器/交換機(jī)側(cè)的路由配置
首先是需要明確GPU卡的連接方式。如果是N卡,你可以使用nvidia-smi topo -m的命令直接查看。但綜合考慮成本因素,要想在更為通用的智算環(huán)境下達(dá)到GPU通信最優(yōu),最好的辦法還是在采購(gòu)和建設(shè)初期就根據(jù)業(yè)務(wù)模型特點(diǎn)和通信方式預(yù)先規(guī)劃好機(jī)內(nèi)互聯(lián)(GPU-GPU、GPU-NIC)和機(jī)間互聯(lián)(GPU-NIC-GPU),避免過(guò)早出現(xiàn)通信瓶頸,導(dǎo)致昂貴算力資源的浪費(fèi)。
智算環(huán)境下以GPU卡(而非服務(wù)器)為單位的通信模式形成了服務(wù)器多網(wǎng)卡多出口環(huán)境的路由策略,通常會(huì)有8張網(wǎng)卡用于接入?yún)?shù)/計(jì)算網(wǎng),每張網(wǎng)卡位于各自的軌道平面上。為避免回包通信失敗,服務(wù)器上的網(wǎng)卡配置需要利用Linux多路由表和策略路由機(jī)制進(jìn)行路由規(guī)劃,這與傳統(tǒng)云網(wǎng)的配置方式完全不同。
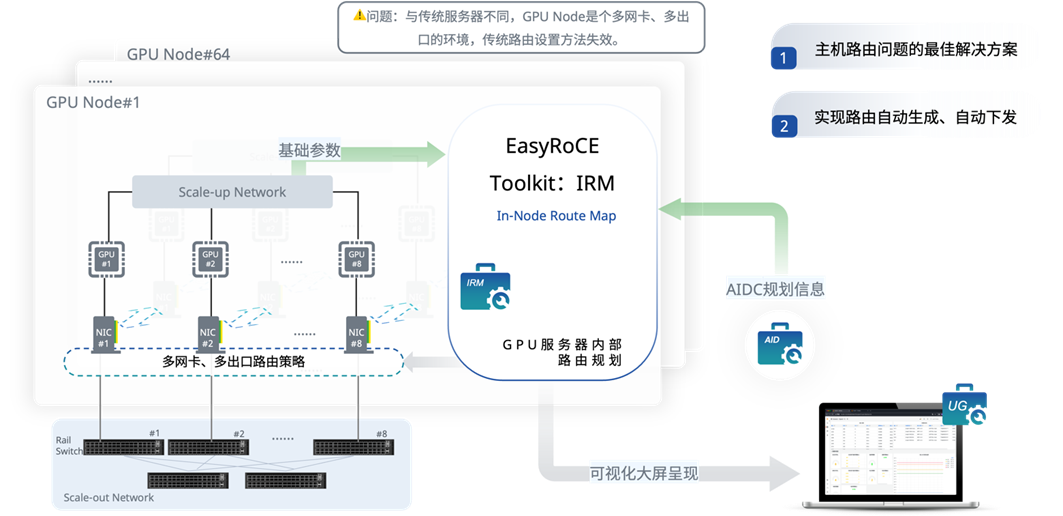
第一步是按照組網(wǎng)規(guī)劃和網(wǎng)段規(guī)劃,進(jìn)行IP地址規(guī)劃和Rail平面劃分。在我們的EasyRoCE Toolkit 下的AID工具(AI Infrastructure Descriptor,AI基礎(chǔ)設(shè)施藍(lán)圖規(guī)劃)中,Notes字段用于標(biāo)注Rail編號(hào),即0代表Rail平面0、1代表Rail平面1,以此類推。

截取自星融元 EasyRoCE AID 工具
確認(rèn)好了上述信息,到這里其實(shí)可以開始手動(dòng)配置了,但你也可以使用另一個(gè)EasyRoCE的IRM工具(In-node Route Map,GPU內(nèi)部路由規(guī)劃器)。IRM 從AID 生成的配置文件中獲取適合當(dāng)前集群環(huán)境的路由規(guī)劃信息,并且自動(dòng)化地對(duì)集群中的所有GPU服務(wù)器進(jìn)行IP和策略路由配置。
CLos架構(gòu)下,各交換節(jié)點(diǎn)分布式運(yùn)行和自我決策轉(zhuǎn)發(fā)路徑容易導(dǎo)致無(wú)法完全感知全局信息,在多層組網(wǎng)下流量若發(fā)生Hash極化(經(jīng)過(guò)2次或2次以上Hash后出現(xiàn)的負(fù)載分擔(dān)不均)將拖慢集群性能。
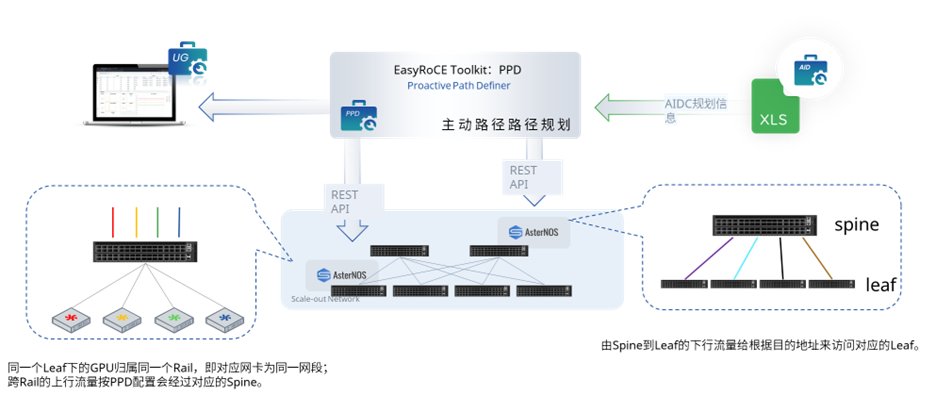
為解決滿足AI集群規(guī)模化部署的通信需求,一般來(lái)說(shuō)我們會(huì)通過(guò)規(guī)范流量路徑來(lái)解決性能和規(guī)模方面的痛點(diǎn)(例如負(fù)載均衡、租戶隔離等),按照如下轉(zhuǎn)發(fā)邏輯去配置RoCE交換機(jī):
- 跨 Spine上行流量進(jìn)入Leaf后根據(jù)源IP和是否為跨Spine遠(yuǎn)端流量,執(zhí)行策略路由轉(zhuǎn)發(fā)給Spine,每網(wǎng)卡對(duì)應(yīng)一個(gè)接口:
- 在上下行流量1:1無(wú)收斂的情況下,Leaf的每個(gè)下行端口綁定一個(gè)上行端口;
- 在n:1的情況下,上下行端口以倍數(shù)關(guān)系(向上取整)形成n:1映射。
- 跨Spine上行流量在Spine上按照標(biāo)準(zhǔn)L3邏輯轉(zhuǎn)發(fā),在軌道組網(wǎng)中多數(shù)流量?jī)H在軌道內(nèi)傳輸,跨軌道傳輸流量較小,網(wǎng)絡(luò)方案暫不考慮Spine上擁塞的情況(由GPU Server集合通信處理)。
- 跨 Spine下行流量進(jìn)入Leaf后根據(jù) default 路由表指導(dǎo)轉(zhuǎn)發(fā)。
當(dāng)然,這里也可以使用EasyRoCE Toolkit 下的PPD工具(主動(dòng)路徑規(guī)劃,Proactive Path Definer)自動(dòng)生成以上配置。以下為PPD工具運(yùn)行過(guò)程。
正在生成配置文件
100%[#########################]
Configuring leaf1's port
leaf1的端口配置完成
Generating leaf1's ai network config
The ai network config finished.
正在生成配置文件
100%[#########################]
Configuring leaf2's port
leaf2的端口配置完成
Generating leaf2's ai network config
The ai network config finished.
正在生成配置文件
100%[#########################]
Configuring leaf3's port
leaf3的端口配置完成
Generating leaf3's ai network config
The ai network config finished.
正在生成配置文件
100%[#########################]
Configuring leaf4's port
leaf4的端口配置完成
Generating leaf4's ai network config
The ai network config finished.
正在生成配置文件
100%[#########################]
show running config
是否需要查看生成的配置(Y|N):
是否需要查看生成的配置(Y|N):
是否需要查看生成的配置(Y|N):PPD可以獨(dú)立運(yùn)行在服務(wù)器上,也可以代碼形式被集成到第三方管理軟件中,利用AID工具來(lái)生成最終配置腳本,將配置呈現(xiàn)在統(tǒng)一監(jiān)控面板(例如Prometheus+Grafana)進(jìn)行瀏覽和核對(duì)。
對(duì)網(wǎng)絡(luò)設(shè)備的要求
星融元CX-N系列交換機(jī)正是為智算中心AI訓(xùn)練場(chǎng)景而生的超低時(shí)延以太網(wǎng)交換機(jī)——在保持極致性能的同時(shí),實(shí)現(xiàn)可編程、可升級(jí)的能力,與計(jì)算設(shè)備形成協(xié)同,共同打造10萬(wàn)級(jí)別的計(jì)算節(jié)點(diǎn)互聯(lián),將數(shù)據(jù)中心重構(gòu)為可與超級(jí)計(jì)算機(jī)媲美的AI超級(jí)工廠。

- 最大支持64個(gè)800G以太網(wǎng)接口,共51.2T交換容量。
- 超低時(shí)延 ,在800G端口上實(shí)現(xiàn)業(yè)界最強(qiáng)的560ns cut-through時(shí)延。
- 全端口標(biāo)配支持RoCEv2 ,支持Rail-only,全連接Clos以及200G/400G混合組網(wǎng),靈活適應(yīng)不同的算力中心建設(shè)方案
- 200+ MB大容量高速片上包緩存 ,顯著減小集體通信時(shí)RoCE流量的存儲(chǔ)轉(zhuǎn)發(fā)時(shí)延。
- Intel至強(qiáng)CPU + 大容量可擴(kuò)展內(nèi)存,運(yùn)行持續(xù)進(jìn)化的企業(yè)級(jí)SONiC ——AsterNOS網(wǎng)絡(luò)操作系統(tǒng),并通過(guò)DMA直接訪問(wèn)包緩存,對(duì)網(wǎng)絡(luò)流量進(jìn)行實(shí)時(shí)加工。
- INNOFLEX可編程轉(zhuǎn)發(fā)引擎 ,可以根據(jù)業(yè)務(wù)需求和網(wǎng)絡(luò)狀態(tài)實(shí)時(shí)調(diào)整轉(zhuǎn)發(fā)流程,最大程度避免網(wǎng)絡(luò)擁塞和故障而造成的丟包。
- F LASHLIGHT精細(xì)化流量分析引擎 ,實(shí)時(shí)測(cè)量每個(gè)包的延遲和往返時(shí)間等,經(jīng)過(guò)CPU的智能分析,實(shí)現(xiàn)自適應(yīng)路由和擁塞控制。
- 10納秒級(jí)別的PTP/SyncE時(shí)間同步,保證所有GPU同步計(jì)算。
- 開放API ,通過(guò)REST API開放全部功能給AI數(shù)據(jù)中心管理系統(tǒng),與計(jì)算設(shè)備相互協(xié)同,實(shí)現(xiàn)GPU集群的自動(dòng)化部署。
詳細(xì)信息請(qǐng)前往星融元官網(wǎng)https://asterfusion.com/product/cx-n/
參考鏈接:
https://blog.csdn.net/qq_41904778/article/details/145930361
https://blog.csdn.net/qq_40214669/article/details/143307857
https://developer.nvidia.com/blog/doubling-all2all-performance-with-nvidia-collective-communication-library-2-12/
https://mp.weixin.qq.com/s/yQn56hh56FE1XDGrrKme7Q
https://mp.weixin.qq.com/s/vZL-4Cpb1BFyH1CpVw3IJQ
審核編輯 黃宇
-
以太網(wǎng)
+關(guān)注
關(guān)注
40文章
5605瀏覽量
175112 -
交換機(jī)
+關(guān)注
關(guān)注
21文章
2728瀏覽量
101542 -
網(wǎng)絡(luò)
+關(guān)注
關(guān)注
14文章
7783瀏覽量
90528 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3927瀏覽量
93263 -
DeepSeek
+關(guān)注
關(guān)注
1文章
785瀏覽量
1479
發(fā)布評(píng)論請(qǐng)先 登錄
DeepSeek在昇騰上的模型部署的常見問(wèn)題及解決方案
DeepSeek企業(yè)級(jí)部署RakSmart裸機(jī)云環(huán)境準(zhǔn)備指南
【幸狐Omni3576邊緣計(jì)算套件試用體驗(yàn)】DeepSeek 部署及測(cè)試
采購(gòu)GUTOR UPS備品備件,隱藏的“雷區(qū)” 你了解嗎?
DeepSeek企業(yè)級(jí)部署服務(wù)器資源計(jì)算 以raksmart裸機(jī)云服務(wù)器為例
DeepSeek企業(yè)級(jí)部署實(shí)戰(zhàn)指南:以Raksmart企業(yè)服務(wù)器為例
HarmonyOS NEXT開發(fā)實(shí)戰(zhàn):DevEco Studio中DeepSeek的使用
RK3588開發(fā)板上部署DeepSeek-R1大模型的完整指南
添越智創(chuàng)基于 RK3588 開發(fā)板部署測(cè)試 DeepSeek 模型全攻略
ATK-DLRK3588開發(fā)板deepseek-r1-1.5b/7b部署指南
了解DeepSeek-V3 和 DeepSeek-R1兩個(gè)大模型的不同定位和應(yīng)用選擇
【實(shí)測(cè)】用全志A733平板搭建一個(gè)端側(cè)Deepseek算力平臺(tái)
DeepSeek-R1本地部署指南,開啟你的AI探索之旅






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論