 谷歌開發了一種名為NSynth Super的合成器,利用機器出新聲音
谷歌開發了一種名為NSynth Super的合成器,利用機器出新聲音
世界上的樂器種類繁多,但這還不夠。谷歌開發了一種名為NSynth Super的合成器,利用機器學習能夠造出獨一無二的新聲音。今天谷歌將這一工具的代碼開源,看看這個奇妙的“玩具”到底能變出什么花樣吧。
什么是NSynth Super?
NSynth Super是谷歌研究項目Magenta正在進行的實驗中的一部分,該項目的目的是探索機器學習如何幫助藝術家一新方式創作藝術和音樂。
科技在創造新聲音方面一直發揮著重要作用——從聲音的扭曲到合成電音。今天,機器學習和神經網絡的進步為聲音的創作提供了新可能。
在過去研究的基礎上,Magenta創造了NSynth(神經合成器)。這是一種機器學習算法,利用深度神經網絡學習聲音的特征,然后根據這些特征創造出完全新的聲音。
相比于簡單的將聲音組合起來,NSynth利用原聲音的音色重新合成了全新的聲音,所以你可以聽到一半是笛子一半是西塔琴的聲音。
自從NSynth發布后,Magenta就不斷嘗試開發不同的音樂交互工具,想讓NSynth算法更容易上手。作為探索的一部分,Magenta與谷歌創意實驗室(Google Creative Lab)合作,創造出了NSynth Super。這是一款開源的實驗性工具,音樂家能通過里面默認的4種原始聲音生成全新的聲音。現在這款產品的原型正在音樂人圈子里進行小范圍的實驗,評估他們使用的感受。
NSynth Super是如何工作的?
在這個實驗中,音樂家們在錄音室里錄制了跨15個音的16種原始聲音源,然后將其輸入到NSynth算法中,用算法生成新的聲音。然后將生成的超過10萬種新的聲音加載到產品原型中。
每個旋鈕代表四種不同的源聲音,音樂家能通過控制旋鈕選擇不同音色,然后手指在觸摸屏上滑動,將這四種聲音結合起來。
NSynth Super可以通過任何MIDI源播放,例如DAW,音序器或者鍵盤。
NSynth算法是如何工作的?
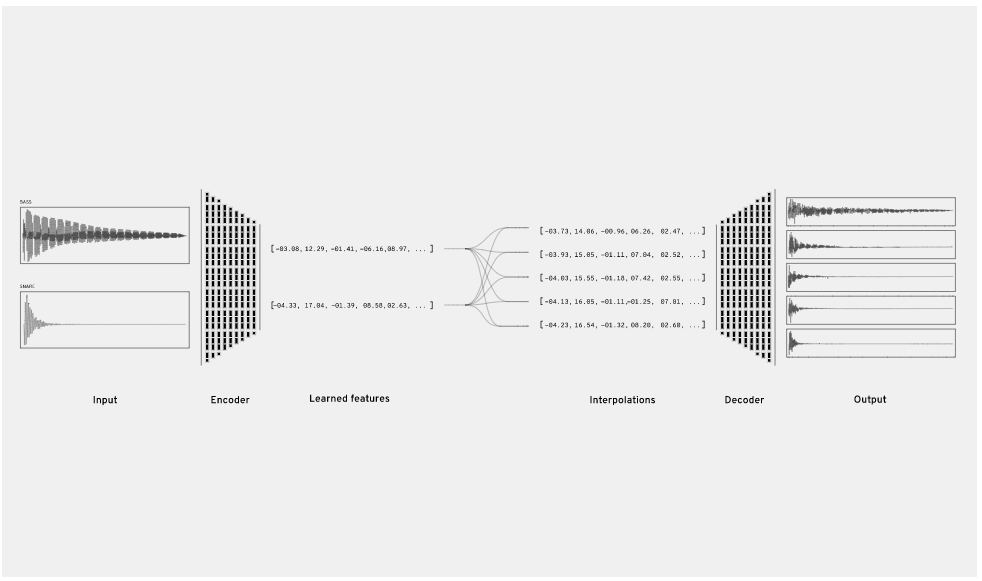
根據個人水平、風格不同,NSynth利用深度神經網絡生成不同的聲音。NSynth直接從數據中學習,可以讓藝術家直接控制音色和節湊,并能夠手動探索創造新的聲音。
NSynth是一種算法,可以結合現有聲音的特征來生成新的聲音。為此,該算法將不同的聲音作為輸入。
使用自動編碼器,它可以從每個輸入中提取16個時間特征。然后將這些特征線性插入創建新的嵌入(每個聲音的數學表示)。然后將這些新的嵌入解碼成新的聲音,這些聲音具有兩個輸入的聲音質量。
完整地介紹可以參見Magenta的博客,數據集合算法可以在原論文中找到。
如何才能得到NSynth Super?
觸摸屏可發現新聲音
音色選擇鈕
音色調整鈕
和Magenta其他項目一樣,NSynth Super建立在開源庫之上,例如TensorFlow和openFrameworks,目的是讓更多的藝術家、編程者和研究者體驗這一創造性的過程。NSynth Super的開源版本包含所有開源代碼、簡圖和設計模板,都可以在GitHub上下載。
-
合成器
+關注
關注
0文章
273瀏覽量
25386 -
谷歌
+關注
關注
27文章
6172瀏覽量
105629
原文標題:用機器學習創造獨特聲音,谷歌開源NSynth Super
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
完整的直接數字頻率合成器 AD9850 的分立、低相位噪聲、125MHz 晶振解決方案
FlexDDS-NG直接數字信號合成器(DDS)/波形發生器
組合兩個 LMX2820 合成器輸出,以改善相位噪聲應用說明






 工商網監
工商網監
評論