") 機器翻譯系統(tǒng)實現(xiàn)了自然語言處理的又一里程碑突破
機器翻譯系統(tǒng)實現(xiàn)了自然語言處理的又一里程碑突破
微軟昨天宣布其研發(fā)的機器翻譯系統(tǒng)首次在通用新聞的漢譯英上達到了人類專業(yè)水平,實現(xiàn)了自然語言處理的又一里程碑突破。
由微軟亞洲研究院與雷德蒙研究院的研究人員組成的團隊今天宣布,其研發(fā)的機器翻譯系統(tǒng)在通用新聞報道的中譯英測試集上,達到了人類專業(yè)譯者水平。這是首個在新聞報道的翻譯質(zhì)量和準(zhǔn)確率上媲美人類專業(yè)譯者的翻譯系統(tǒng)。
微軟技術(shù)院士,負責(zé)微軟語音、自然語言和機器翻譯工作的黃學(xué)東博士表示,這是自然語言處理領(lǐng)域的一項里程碑式的成就。“這是我們的情懷,是非常有意義的工作,”黃學(xué)東告訴新智元:“消除語言障礙,讓人們能更好地溝通,非常有價值,值得我們多年來不斷為此付出努力。”
黃學(xué)東驕傲地說,2015年微軟率先在圖像識別ImageNet數(shù)據(jù)集達到人類水平,2016年在Switchboard對話語義識別達到人類水平,2017在斯坦福問答數(shù)據(jù)集SQuAD上達到人類水平,今天又在機器翻譯上達到人類水平,一路走來,微軟的進步激動人心,“這是我們共同的成就,我們是站在同行的肩膀上往上走”。
黃學(xué)東表示,微軟語音和NLP組在成立時,便立下了要在兩年后將機器翻譯做到人類專業(yè)水平的目標(biāo)。如今,這一目標(biāo)提前實現(xiàn),“除了計算力的大幅提高,深度學(xué)習(xí)方法的提高,我們還結(jié)合了以前在Switchboard上取得的經(jīng)驗,數(shù)據(jù)也做了很多整理,比如去除低質(zhì)量的訓(xùn)練數(shù)據(jù),等等。”黃學(xué)東說。
“這既是技術(shù)上的突破,也是工程上的突破,是技術(shù)和工程的完美結(jié)合,只有把過程中的每一件事情都做好,才能得到這樣的結(jié)果。”
NLP里程碑式突破:首個媲美人類專業(yè)譯者的機器翻譯系統(tǒng)
這次微軟的翻譯系統(tǒng)是在數(shù)據(jù)集WMT-17的新聞數(shù)據(jù)集newstest2017上取得了上述成果。WMT是機器翻譯領(lǐng)域的國際頂級評測比賽之一。WMT數(shù)據(jù)集也是機器翻譯領(lǐng)域一個公認的主流數(shù)據(jù)集。其中,newstest2017新聞報道測試集由產(chǎn)業(yè)界和學(xué)術(shù)界的合作伙伴共同開發(fā),包括來自新聞評論語料庫的約332K個句子對,來自聯(lián)合國平行語料庫的15.8M個句子對,以及來自CWMT語料庫的9M個句子對。
雖然研究人員只進行了漢譯英的測試,但黃學(xué)東表示,英譯漢結(jié)果也應(yīng)該并無不同。“從技術(shù)上說,漢譯英和英譯漢是相同的,只要有足夠的數(shù)據(jù)。”
為了確保翻譯結(jié)果準(zhǔn)確且達到人類的翻譯水平,微軟研究團隊還邀請了雙語語言顧問,將微軟的翻譯結(jié)果與兩個獨立的人工翻譯結(jié)果進行了比較評估(全部盲測)。黃學(xué)東告訴新智元:“當(dāng)機器翻譯質(zhì)量很差的時候,使用BLEU評分還行,但是當(dāng)機器翻譯質(zhì)量提高以后,就需要靠人類來評價。”
具體說,當(dāng)100分是標(biāo)準(zhǔn)滿分時,微軟的系統(tǒng)得分69.9,專業(yè)譯者68.6,而眾包翻譯得分為67.6。
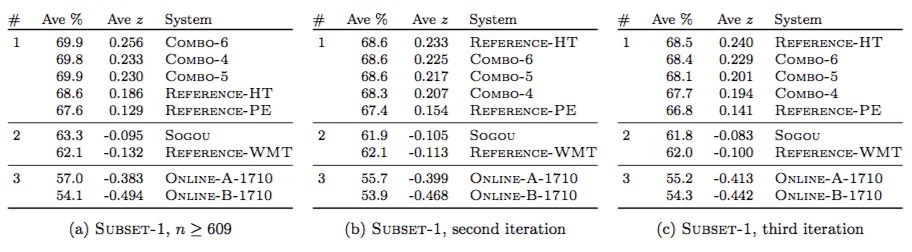
人類專家的評估結(jié)果(部分):其中,Reference-HT為純?nèi)斯しg;Reference-PE為使用Google Translate加人工后期編輯的翻譯;Reference-WMT是WMT原始翻譯,包含錯誤;Online-A-1710是2017年10月16日收集的Microsoft翻譯商用系統(tǒng)(production system);Online-B-1710是2017年10月16日收集的谷歌翻譯商用系統(tǒng);Sogou是搜狗NMT翻譯系統(tǒng),這是在2017年WMT中英機器翻譯競賽的冠軍。
機器翻譯提前7年超越業(yè)余譯者,人工智能再下一城
機器翻譯是科研人員攻堅了數(shù)十年的研究領(lǐng)域,曾經(jīng)很多人都認為機器翻譯根本不可能達到人類翻譯的水平。
2017年中旬,牛津大學(xué)面向機器學(xué)習(xí)研究人員做了一次大規(guī)模調(diào)查,調(diào)查的內(nèi)容是他們對 AI 進展的看法。這些研究人員預(yù)測,未來10年,AI 將在許多活動中超過人類,具體預(yù)測見下表:
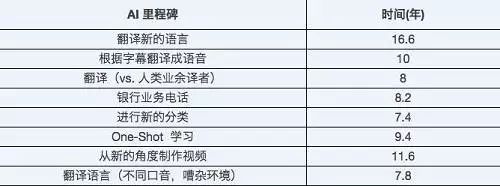
微軟的這次突破,將機器翻譯超越人類業(yè)余譯者的時間,提前了整整7年,遠遠超出了眾多ML研究人員的預(yù)想。
雖然此次突破意義非凡,但微軟研究人員也提醒大家,這并不代表人類已經(jīng)完全解決了機器翻譯的問題,只能說明我們離終極目標(biāo)又更近了一步。微軟亞洲研究院副院長、自然語言計算組負責(zé)人周明表示,在WMT17測試集上的翻譯結(jié)果達到人類水平很鼓舞人心,但仍有很多挑戰(zhàn)需要解決,比如在實時的新聞報道上測試系統(tǒng)等。
微軟機器翻譯團隊研究經(jīng)理Arul Menezes表示,團隊想要證明的是:當(dāng)一種語言對(比如中-英)擁有較多的訓(xùn)練數(shù)據(jù),且測試集中包含的是常見的大眾類新聞詞匯時,那么在人工智能技術(shù)的加持下,機器翻譯系統(tǒng)的表現(xiàn)可以與人類媲美。
突破當(dāng)前神經(jīng)機器翻譯范式局限,性能再上一個數(shù)量級
為了能夠取得中-英翻譯的里程碑式突破,來自微軟亞洲研究院和雷德蒙研究院的三個研究組,進行了跨越中美時區(qū)、跨越研究領(lǐng)域的聯(lián)合創(chuàng)新。
在這篇有24位作者的論文《機器翻譯:中英新聞翻譯方面達到與人類媲美的水平》(Achieving Human Parity on Automatic Chinese to English News Translation )中,微軟研究團隊描述了他們?yōu)樾侣劃h英翻譯任務(wù)在規(guī)模數(shù)據(jù)集上實現(xiàn)人類水平所作的努力。
在論文中,作者表示他們解決了當(dāng)前NMT范式的一些局限。 他們的研究主要貢獻包括:
利用翻譯問題的對偶性(duality),使模型能夠從源語言到目標(biāo)語言(Source to Target)和從目標(biāo)語言到源語言(Target to Source)這兩個方向的翻譯中學(xué)習(xí)。同時,這讓我們能同時從有監(jiān)督和無監(jiān)督的源數(shù)據(jù)和目標(biāo)數(shù)據(jù)中學(xué)習(xí)。具體而言,我們利用通用的對偶學(xué)習(xí)(dual learning)方法,并引入聯(lián)合訓(xùn)練(Joint Training)算法,通過在一個統(tǒng)一的框架中反復(fù)提高從源語言到目標(biāo)語言翻譯和從目標(biāo)語言到源語言翻譯的模型,從而增強單語源和目標(biāo)數(shù)據(jù)的效果。
NMT系統(tǒng)從左到右自動回歸解碼,這意味著在按順序生成輸出期間,之前的錯誤將被放大,并可能誤導(dǎo)后續(xù)生成的結(jié)果。這只能部分通過波束搜索(beam search)進行補救。我們提出了兩種方法來緩解這個問題:推敲網(wǎng)絡(luò)(Deliberation Networks),這是一種基于雙路解碼來優(yōu)化翻譯的方法;以及在兩個Kullback-Leibler(KL)散度正則化項上的新訓(xùn)練目標(biāo),鼓勵從左到右和從右到左的解碼結(jié)果變得一致。
由于NMT非常容易受到嘈雜訓(xùn)練數(shù)據(jù)、數(shù)據(jù)中的罕見事件以及總體訓(xùn)練數(shù)據(jù)質(zhì)量的影響,論文還討論了數(shù)據(jù)選擇和過濾的方法,包括跨語言句子表示。
最后,我們發(fā)現(xiàn)我們的系統(tǒng)是完全互補的,因此可以從系統(tǒng)組合中獲益很多,最終實現(xiàn)了機器翻譯達到人類水平的目標(biāo)。
四大技術(shù)加持,神經(jīng)機器翻譯將成今后機器翻譯絕對主流
其中,微軟亞洲研究院機器學(xué)習(xí)組將他們的最新研究成果——對偶學(xué)習(xí)(Dual Learning)和推敲網(wǎng)絡(luò)(Deliberation Networks)應(yīng)用在了此次取得突破的機器翻譯系統(tǒng)中。其中,對偶學(xué)習(xí)利用的是人工智能任務(wù)的天然對稱性。當(dāng)我們把訓(xùn)練集中的一個中文句子翻譯成英文之后,系統(tǒng)會將相應(yīng)的英文結(jié)果再翻譯回中文,并與原始的中文句子進行比對,進而從這個比對結(jié)果中學(xué)習(xí)有用的反饋信息,對機器翻譯模型進行修正。
微軟亞洲研究院副院長、機器學(xué)習(xí)組負責(zé)人劉鐵巖
而推敲網(wǎng)絡(luò)則類似于人們寫文章時不斷推敲、修改的過程。通過多輪翻譯,不斷地檢查、完善翻譯的結(jié)果,從而使翻譯的質(zhì)量得到大幅提升。“我們在深度學(xué)習(xí)和自然語言這兩者中間找到了一個平衡點,我們想通過對機器翻譯的研究,從自然語言的角度對機器學(xué)習(xí)做進一步的理解,找到一些直覺,再通過這個直覺反過來影響機器學(xué)習(xí)研究的路線,走出盲目嘗試的狀態(tài)。”微軟亞洲研究院副院長、機器學(xué)習(xí)組負責(zé)人劉鐵巖說。
那研究人員從推敲網(wǎng)絡(luò)中獲得的直覺是什么呢?他們發(fā)現(xiàn),人在做翻譯的時候,在看見或聽完源語言后,腦子里會形成一個觀點,這其實就是編碼的過程。但是,我們真正把這句話當(dāng)成目標(biāo)語言講出來,實際上是三思而后行的。我們不會一個字一個字往出蹦,我們會先醞釀一下要怎么講,如果是文字翻譯,還可能不斷地修改,讓語句更加通順或者優(yōu)美。
“我們常常說,人會做推敲的事情,是‘僧敲月下門’還是‘僧推月下門’,要琢磨琢磨,上下文關(guān)系用哪個字更好,如何在一個機器學(xué)習(xí)的模型中將這種推敲過程體現(xiàn)出來,就是推敲網(wǎng)絡(luò)所要去嘗試的一個點。”劉鐵巖告訴新智元。
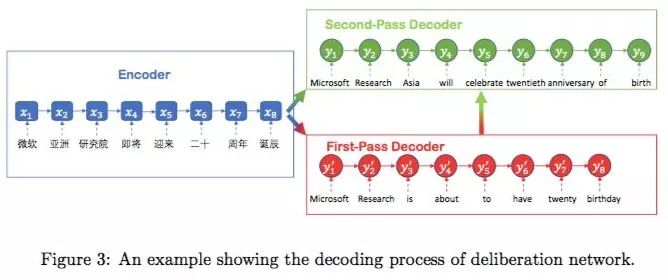
推敲,也就是在解碼器,或者說在文本生成的過程多做點文章,把人的一些直覺放進去。“在我們的DeliberationNet里面,解碼器是有多層的,解碼器先做一遍,可能翻譯得不太好,但從頭到尾翻譯完了,這句翻譯會再扔給下一個解碼器再做一遍,這個過程可以不斷反復(fù),不停地去修改之前翻譯的完整結(jié)果,這其實就在做推敲。我們發(fā)現(xiàn),這樣推敲后的結(jié)果比只過一次要好很多,多過一次時間代價會增多,但是結(jié)果會更好。”
微軟亞洲研究院副院長、自然語言計算組負責(zé)人周明
周明帶領(lǐng)的自然語言計算組多年來一直致力于攻克機器翻譯,這一自然語言處理領(lǐng)域最具挑戰(zhàn)性的研究任務(wù)。周明表示,“由于翻譯沒有唯一的標(biāo)準(zhǔn)答案,它更像是一種藝術(shù),因此需要更加復(fù)雜的算法和系統(tǒng)去應(yīng)對。”
基于之前的研究積累,自然語言計算組在此次的系統(tǒng)模型中增加了另外兩項新技術(shù):聯(lián)合訓(xùn)練(Joint Training)和一致性規(guī)范(Agreement Regularization),以提高翻譯的準(zhǔn)確性。聯(lián)合訓(xùn)練可以理解為用迭代的方式去改進翻譯系統(tǒng),用中英翻譯的句子對去補充反向翻譯系統(tǒng)的訓(xùn)練數(shù)據(jù)集,同樣的過程也可以反向進行。一致性規(guī)范則讓翻譯可以從左到右進行,也可以從右到左進行,最終讓兩個過程生成一致的翻譯結(jié)果。
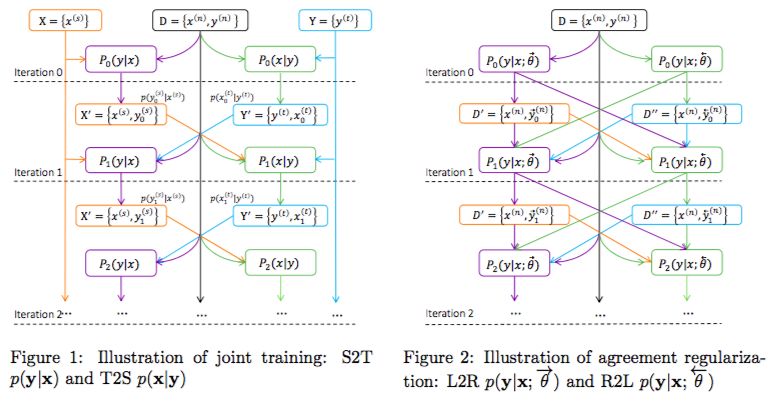
左邊是聯(lián)合訓(xùn)練:從源語言到目標(biāo)語言翻譯(Source to Target)P(y|x) 與從目標(biāo)語言到源語言翻譯(Target to Source)P(x|y);右邊是一致性規(guī)范
這次使用的技術(shù),從對偶學(xué)習(xí)(Dual Learning)、推敲網(wǎng)絡(luò)(Deliberation Network)到一致性規(guī)范(Agreement Regularization),都屬于神經(jīng)機器翻譯(NMT)方法。而黃學(xué)東也認為,今后的機器翻譯領(lǐng)域,NMT也將成為絕對主流。“相比統(tǒng)計機器翻譯,神經(jīng)機器翻譯有一個很大的提高,而這次我們新的系統(tǒng),相比普通的神經(jīng)機器翻譯,又有一個很大的提高。”
黃學(xué)東說:“我們這次的系統(tǒng)是把很多不同的機器翻譯系統(tǒng)組合到一起,這些系統(tǒng)每一個都能獨立工作,輸出結(jié)果,最終,我們再將這些結(jié)果綜合起來,輸出一個最好的結(jié)果。”
深度學(xué)習(xí)NLP掌握著實現(xiàn)強人工智能的鑰匙
對于語音識別等其它人工智能任務(wù)來說,判斷系統(tǒng)的表現(xiàn)是否可與人類媲美相當(dāng)簡單,因為理想結(jié)果對人和機器來說完全相同,研究人員也將這種任務(wù)稱為模式識別任務(wù)。
然而,機器翻譯卻是另一種類型的人工智能任務(wù),即使是兩位專業(yè)的翻譯人員對于完全相同的句子也會有略微不同的翻譯,而且兩個人的翻譯都不是錯的。那是因為表達同一個句子的“正確的”方法不止一種。 周明表示:“這也是為什么機器翻譯比純粹的模式識別任務(wù)復(fù)雜得多,人們可能用不同的詞語來表達完全相同的意思,但未必能準(zhǔn)確判斷哪一個更好。”
復(fù)雜性讓機器翻譯成為一個極有挑戰(zhàn)性的問題,但也是一個極有意義的問題。劉鐵巖認為,我們不知道哪一天機器翻譯系統(tǒng)才能在翻譯任何語言、任何類型的文本時,都能在“信、達、雅”等多個維度上達到專業(yè)翻譯人員的水準(zhǔn)。不過,他對技術(shù)的進展表示樂觀,因為每年微軟的研究團隊以及整個學(xué)術(shù)界都會發(fā)明大量的新技術(shù)、新模型和新算法,“我們可以預(yù)測的是,新技術(shù)的應(yīng)用一定會讓機器翻譯的結(jié)果日臻完善。”
研究團隊還表示,他們計劃將此次技術(shù)突破推廣到其他語言上面,同時應(yīng)用到微軟的商用多語言翻譯系統(tǒng)產(chǎn)品中。
黃學(xué)東認為,神經(jīng)機器翻譯,或者說深度學(xué)習(xí),最激動人心的地方在于,它能夠?qū)W會自然語言內(nèi)部的embedded feature,把語言的結(jié)構(gòu),語義結(jié)構(gòu)和語義的表示學(xué)習(xí)出來,再反饋到系統(tǒng),從而實現(xiàn)自然語言理解的突破。
“機器學(xué)習(xí)需要很多數(shù)據(jù),NLP沒有很多標(biāo)注的數(shù)據(jù),把表示學(xué)習(xí)出來,還能推廣到其他系統(tǒng)。”黃學(xué)東說:“NLP掌握著今后實現(xiàn)強人工智能的鑰匙。”
-
AI
+關(guān)注
關(guān)注
87文章
30728瀏覽量
268892 -
機器翻譯
+關(guān)注
關(guān)注
0文章
139瀏覽量
14880 -
自然語言
+關(guān)注
關(guān)注
1文章
287瀏覽量
13347
原文標(biāo)題:【AI再創(chuàng)紀(jì)錄】機器翻譯提前7年達到人類專業(yè)翻譯水平!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
破萬億!中國芯片出口迎來里程碑






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論