

在評估 GPU 性能時,通常首先考察三個指標:圖形工作負載的紋理率(GPixel/s)、浮點運算次數(FLOPS)以及它們能處理計算和AI工作負載的每秒 8-bit tera 運算次數(TOPS)。這些關鍵數據,結合面積數據、功耗估算和通用功能集,幫助 SoC 設計師比較不同系統配置的性能。
然而,這些指標僅提供了理論性能,并不總是能夠很好地反映實際性能。沒有任何 GPU 能夠始終以100%的利用率運行,因此下一步是探索GPU在實際應用中的特定工作負載性能,通常以每秒幀數(FPS)來衡量,并考慮整體GPU利用率。像Manhattan和Aztec這樣的基準測試為實際圖形性能提供了一個有用的指南(盡管它們本身并不能完全代表典型的應用程序)。
通常在這個階段,不同的GPU架構會產生令人驚訝的結果。那些更擅長將理論性能轉化為實際性能的架構會脫穎而出,提供遠高于其標稱TFLOPS預期的幀率(FPS)。
為什么FPS/TFLOPS很重要?通常來說,具有更高TFLOPS的GPU需要更大的硅片面積和更高的功耗。如果一個較小的GPU能夠提供與理論上更強大的GPU相同的實際性能,設計師就需要選擇:要么以更低的成本提供相同的性能,要么保持成本不變但將額外的性能或效率交給最終用戶。基于此,理解GPU的性能效率是了解GPU在終端設備中表現的重要部分。Imagination 的 PowerVR 架構經過數十年的優化,已成為市場上性能最為高效的嵌入式 GPU IP。本文將概述關鍵的硬件和軟件優化,幫助 Imagination 的 GPU 實現比競爭對手的嵌入式產品高出兩倍的 FPS/TFLOPS 性能。
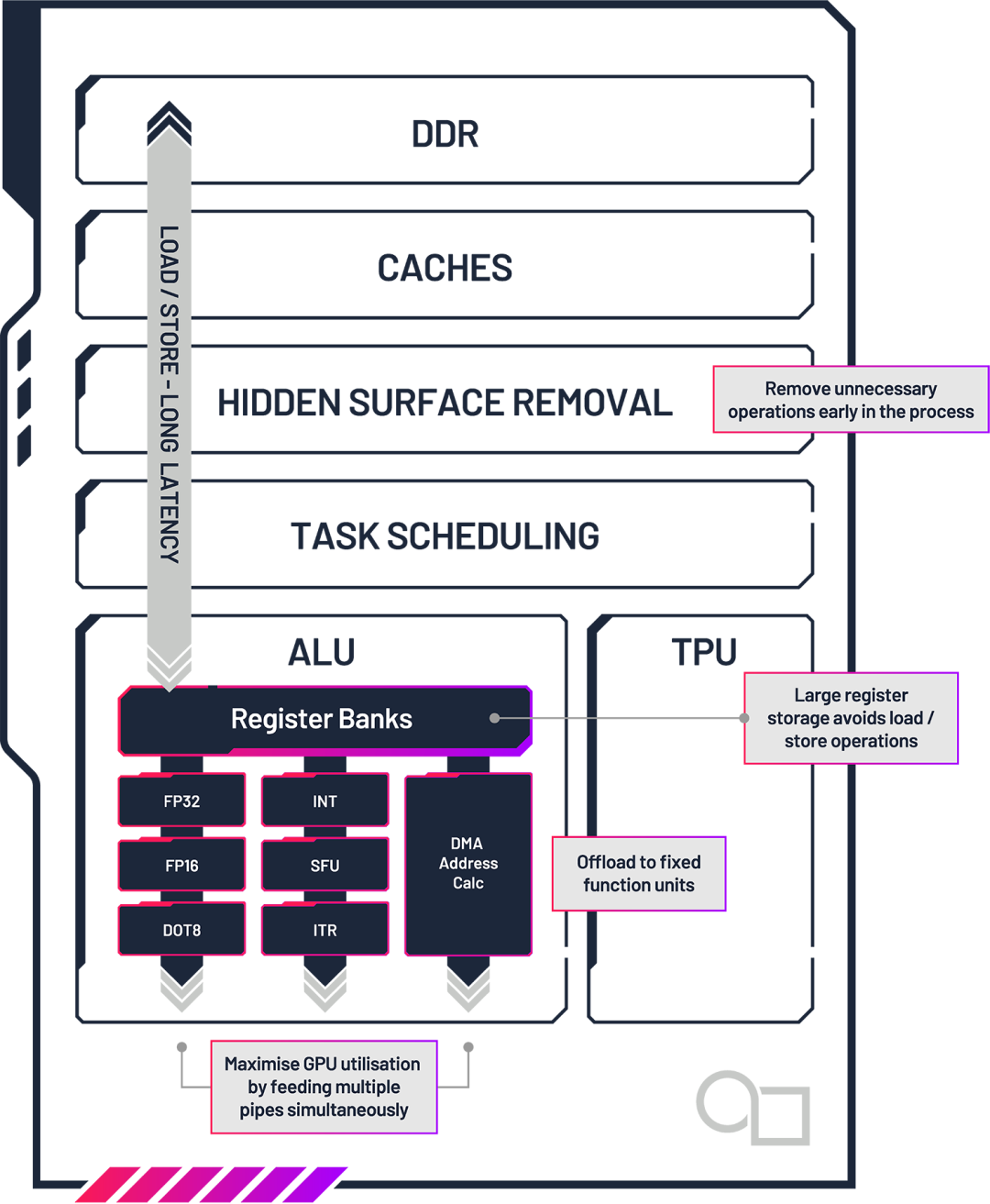
1. 大容量、響應迅速的寄存器存儲
Imagination GPU 的每個算術邏輯單元(ALU)內都有非常大的寄存器存儲,一般為 512KB,通常是競爭對手嵌入式 GPU 設計的兩倍。這使得工作負載可以避免從主GPU內存進行長時間的加載/存儲操作,這些操作可能會延遲處理工作,從而對GPU利用率和效率產生負面影響。ALU中的寄存器體設計得允許同時訪問多個寄存器。這意味著在每個周期中,ALU內的多個單元都可以執行任務。例如,FP32操作可以與復雜操作并行處理,而無需排隊等待內存訪問。大多數其他嵌入式GPU架構在寄存器訪問方面存在限制,這會導致數據需要額外的周期來獲取,從而造成處理停滯。
Imagination GPU設計可同時處理多個工作負載。這意味著當需要進行加載/存儲時,可以通過替代操作填補處理暫停,從而有效避免延遲問題。
2.專用模塊卸載主ALU工作
Imagination 的ALU包含多個固定功能塊,使 GPU 能夠將冗長的任務(如地址計算)從主ALU 卸載,從而使它們可以自由處理一般工作負載。相比之下,大多數其他嵌入式 GPU 提供商通過 INT32 ALU模擬地址計算和復雜任務,降低了整體 GPU 性能效率。
3. 整體 GPU 架構效率
由于其延遲渲染技術,PowerVR架構自問世以來一直是GPU效率的領導者。在流水線的早期階段,Imagination GPU 會全面分析每一幀,確定哪些片段是可見的,并僅處理用戶可以看到的部分。通過盡早移除不必要的操作,Imagination GPU降低了功耗并提高了性能效率。其他嵌入式GPU架構仍然處理比必要更多的片段,浪費寶貴的計算資源和帶寬,從而需要更多功耗。
4. 軟件最大化GPU利用率雖然我們主要從圖形角度討論性能效率,但上述內容同樣適用于計算和 AI 應用。為了進一步提高 AI 工作負載的性能效率,Imagination 提供了一套高度優化的計算庫(imgNN、imgBLAS、imgFFT),用于常見的運算操作,使程序員能夠最大化 GPU 利用率。
所有這些特性的結果不言而喻。在下圖的所有圖形工作負載中,Imagination GPU 的 FPS/TFLOPS超過了同等面積的嵌入式競爭對手設計。在某些情況下,性能效率是其他GPU的兩倍。
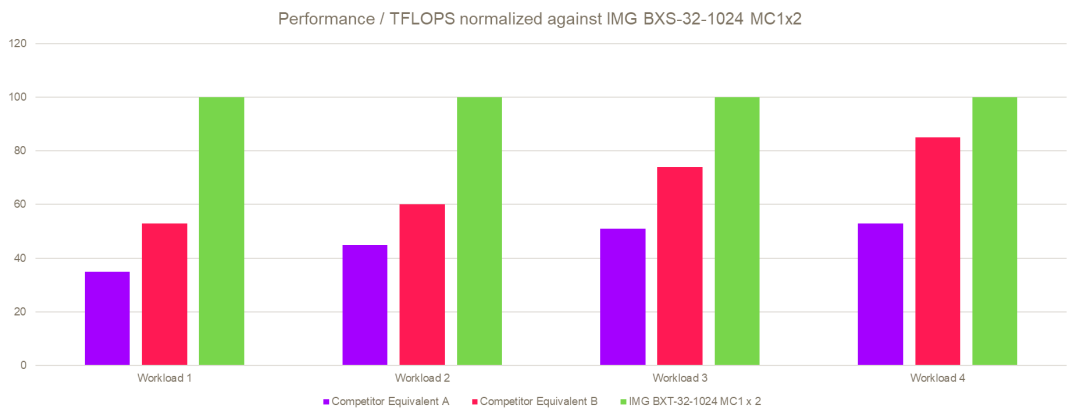
圖注:基于Imagination內部數據。所有競爭設備以低時鐘頻率運行,以避免主機 CPU 和系統瓶頸,以便更純粹地了解競爭 GPU 的能力。
GPU性能在所有細分市場上都在蓬勃發展,不僅用于圖形體驗,在 AI 時代,還將其用作靈活的并行計算處理器。硬件設計師有兩種選擇來提供這種額外的性能:一種是簡單地構建一個具有更高理論TFLOPS的GPU;另一種選擇是選擇一個理論TFLOPS較低但高性能效率的 GPU。
聲明:本文為原創文章,轉載需注明作者、出處及原文鏈接。
原文鏈接:https://blog.imaginationtech.com/why-gpu-performance-efficiency-beats-peak-performance
-
嵌入式
+關注
關注
5105文章
19288瀏覽量
310171 -
gpu
+關注
關注
28文章
4832瀏覽量
129794
發布評論請先 登錄
相關推薦
NVIDIA下一代7nm GPU效率比Turing高兩倍
優化任何GPU工作負載的峰值性能分析方法





 工商網監
工商網監

評論