


問(wèn):為什么 CPU 的浮點(diǎn)運(yùn)算能力比 GPU 差,為什么不提高 CPU 的浮點(diǎn)運(yùn)算能力?
「速度區(qū)別主要是來(lái)自于架構(gòu)上的區(qū)別」是一個(gè)表面化的解釋。對(duì),架構(gòu)是不同。但是這種不同是目前各個(gè)廠家選擇的現(xiàn)狀,還是由于本質(zhì)的原因決定的?CPU 能不能增加核?GPU 那張圖為什么不需要 cache?
首先,CPU 能不能像 GPU 那樣去掉 cache?不行。GPU 能去掉 cache 關(guān)鍵在于兩個(gè)因素:數(shù)據(jù)的特殊性(高度對(duì)齊,pipeline 處理,不符合局部化假設(shè),很少回寫(xiě)數(shù)據(jù))、高速度的總線。對(duì)于后一個(gè)問(wèn)題,CPU 受制于落后的數(shù)據(jù)總線標(biāo)準(zhǔn),理論上這是可以改觀的。對(duì)于前一個(gè)問(wèn)題,從理論上就很難解決。因?yàn)?CPU 要提供通用性,就不能限制處理數(shù)據(jù)的種類。這也是 GPGPU 永遠(yuǎn)無(wú)法取代 CPU 的原因。
其次,CPU 能不能增加很多核?不行。首先 cache 占掉了面積。其次,CPU 為了維護(hù) cache 的一致性,要增加每個(gè)核的復(fù)雜度。還有,為了更好的利用 cache 和處理非對(duì)齊以及需要大量回寫(xiě)的數(shù)據(jù),CPU 需要復(fù)雜的優(yōu)化(分支預(yù)測(cè)、out-of-order 執(zhí)行、以及部分模擬 GPU 的 vectorization 指令和長(zhǎng)流水線)。所以一個(gè) CPU 核的復(fù)雜度要比 GPU 高的多,進(jìn)而成本就更高(并不是說(shuō)蝕刻的成本高,而是復(fù)雜度降低了成片率,所以最終成本會(huì)高)。所以 CPU 不能像 GPU 那樣增加核。
至于控制能力,GPU 的現(xiàn)狀是差于 CPU,但是并不是本質(zhì)問(wèn)題。而像遞歸這樣的控制,并不適合高度對(duì)齊和 pipeline 處理的數(shù)據(jù),本質(zhì)上還是數(shù)據(jù)問(wèn)題。
-
cpu
+關(guān)注
關(guān)注
68文章
11076瀏覽量
216998 -
gpu
+關(guān)注
關(guān)注
28文章
4943瀏覽量
131203
原文標(biāo)題:為什么 CPU 的浮點(diǎn)運(yùn)算能力比 GPU 差,為什么不提高 CPU 的浮點(diǎn)運(yùn)算能力?
文章出處:【微信號(hào):Imgtec,微信公眾號(hào):Imagination Tech】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【中科昊芯Core_DSC280025C開(kāi)發(fā)板試用體驗(yàn)】+1.開(kāi)箱之浮點(diǎn)計(jì)算對(duì)比
MemryX 推出浮點(diǎn)運(yùn)算 AI 芯片,引領(lǐng)精準(zhǔn)運(yùn)算新時(shí)代
搭載32位RXv2 CPU內(nèi)核以及增強(qiáng)型DSP和FPU的RX230系列低功耗、高性能微控制器數(shù)據(jù)手冊(cè)

?為什么GPU性能效率比峰值性能更關(guān)鍵

設(shè)計(jì)了一個(gè)基于浮點(diǎn)數(shù)運(yùn)算的協(xié)處理器,使用C語(yǔ)言編程時(shí)沒(méi)法輸入float型數(shù)據(jù),請(qǐng)問(wèn)有哪些部分需要修改?
2024年GPU出貨量增長(zhǎng)顯著,超越CPU
西門子TIA Portal如何比較兩個(gè)浮點(diǎn)數(shù)相等
【RA-Eco-RA4E2-64PIN-V1.0開(kāi)發(fā)板試用】RA4E2的DSP浮點(diǎn)性能的軟件浮點(diǎn)測(cè)試和硬件浮點(diǎn)測(cè)試對(duì)比
FPGA中的浮點(diǎn)四則運(yùn)算是什么
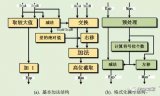
FPGA中浮點(diǎn)四則運(yùn)算的實(shí)現(xiàn)過(guò)程





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論