

DeepSeek-R1 模型在 4 張 NVIDIA RTX 5880 Ada 顯卡配置下,面對短文本生成、長文本生成、總結概括三大實戰場景,會碰撞出怎樣的性能火花?參數規模差異懸殊的 70B 與 32B 兩大模型,在 BF16 精度下的表現又相差幾何?本篇四卡環境實測報告,將為用戶提供實用的數據支持和性能參考。
1測試環境
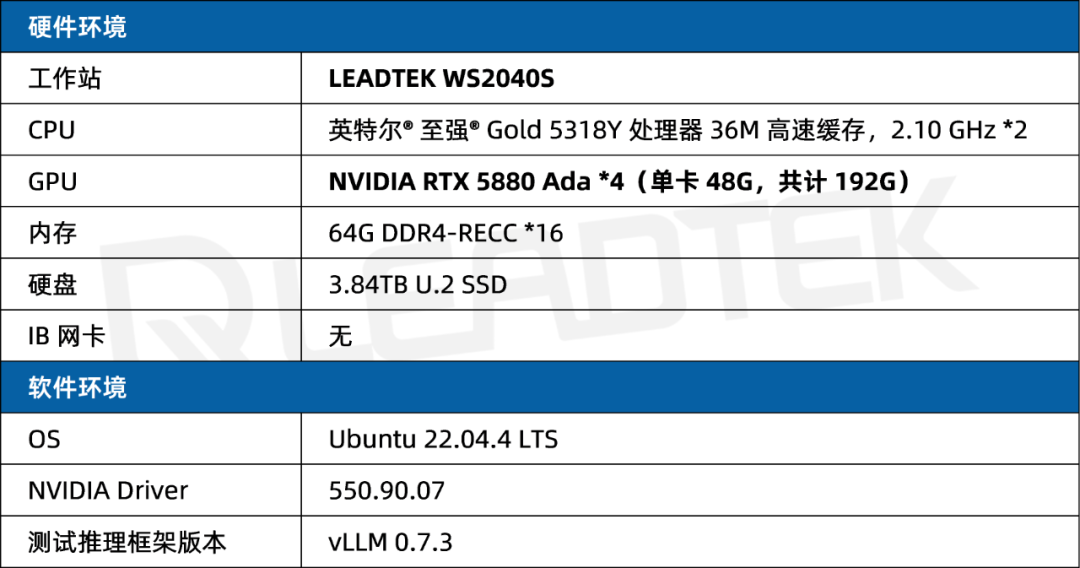
2測試指標
首次 token 生成時間(Time to First Token, TTFT(s))越低,模型響應速度越快;每個輸出 token 的生成時間(Time Per Output Token, TPOT(s))越低,模型生成文本的速度越快。
輸出 Token 吞吐量(Output Token Per Sec, TPS):反映系統每秒能夠生成的輸出 token 數量,是評估系統響應速度的關鍵指標。多并發情況下,使用單個請求的平均吞吐量作為參考指標。
首次 Token 生成時間(Time to First Token, TTFT(s)):指從發出請求到接收到第一個輸出 token 所需的時間,這對實時交互要求較高的應用尤為重要。多并發情況下,平均首次 token 時間 (s) 作為參考指標。
單 Token 生成時間(Time Per Output Token,TPOT(s)):系統生成每個輸出 token 所需的時間,直接影響了整個請求的完成速度。多并發情況下,使用平均每個輸出 token 的時間 (s) 作為參考指標。這里多并發時跟單個請求的 TPOT 不一樣,多并發 TPOT 計算不包括生成第一個 token 的時間。
并發數(Concurrency):指的是系統同時處理的任務數量。適當的并發設置可以在保證響應速度的同時最大化資源利用率,但過高的并發數可能導致請求打包過多,從而增加單個請求的處理時間,影響用戶體驗。
3測試場景
在實際業務部署中,輸入/輸出 token 的數量直接影響服務性能與資源利用率。本次測試針對三個不同應用場景設計了具體的輸入 token 和輸出 token 配置,以評估模型在不同任務中的表現。具體如下:

4測試結果
4.1 短文本生成場景
使用 DeepSeek-R1-70B(BF16),單請求吞吐量約 19.9 tokens/s,并發 100 時降至約 9.9 tokens/s(約為單請求的 50%)。最佳工作區間為低并發場景(1-50 并發)。
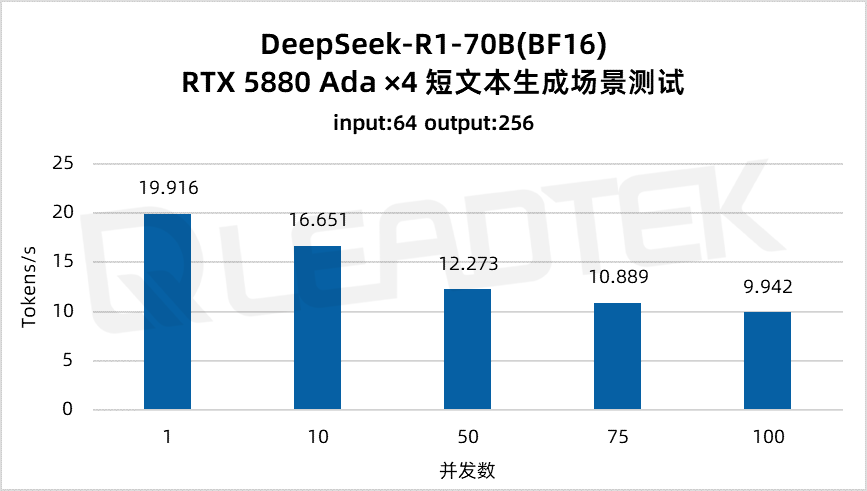
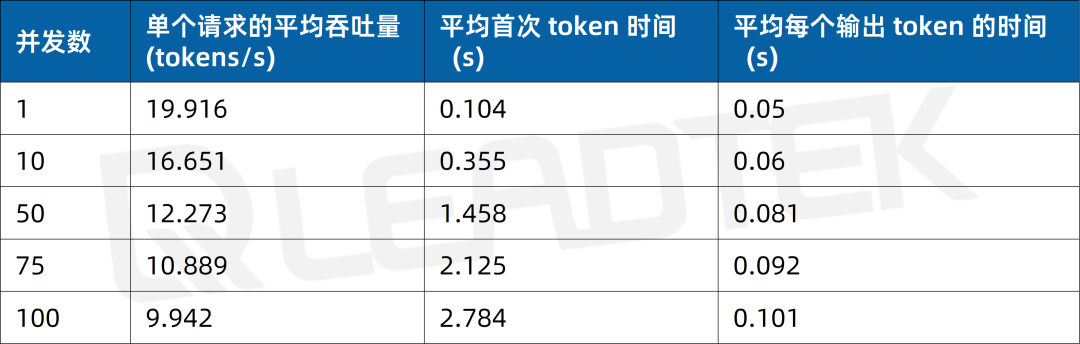
▲ DeepSeek-R1-70B(BF16) 測試結果圖表
2025 麗臺(上海)信息科技有限公司
本文所有測試結果均由麗臺科技實測得出,如果您有任何疑問或需要使用此測試結果,請聯系麗臺科技(下同)
使用 DeepSeek-R1-32B(BF16),單請求吞吐量達約 39.5 tokens/s,并發 100 時仍保持約 18.1 tokens/s,能夠滿足高并發場景(100 并發)。
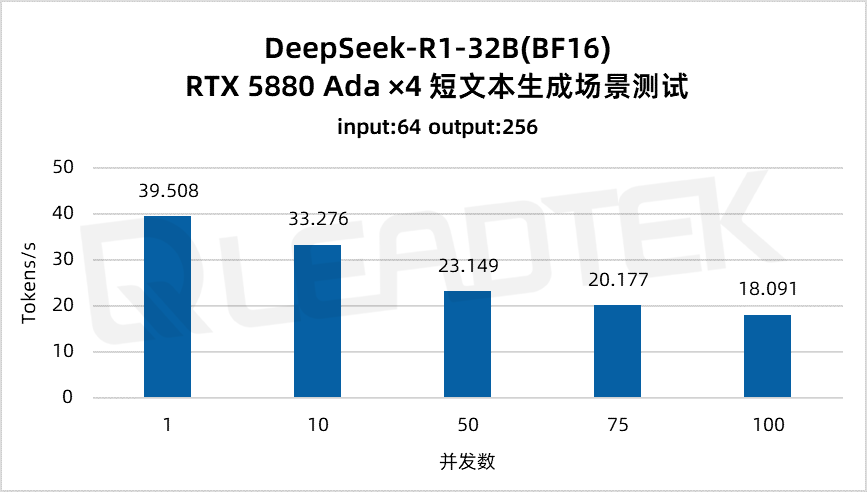
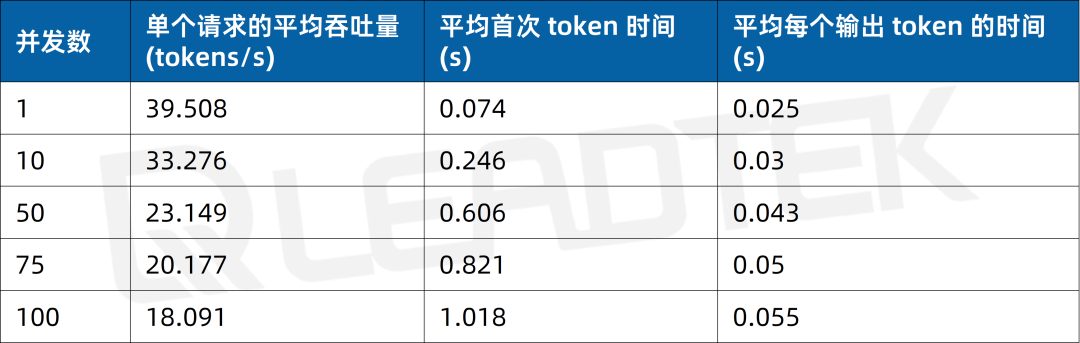
▲ DeepSeek-R1-32B(BF16) 測試結果圖表
4.2 長文本生成場景
使用 DeepSeek-R1-70B(BF16),單請求吞吐量約 20 tokens/s,并發 100 時降至約 8.8 tokens/。最佳工作區間為低并發場景(1-50 并發)。
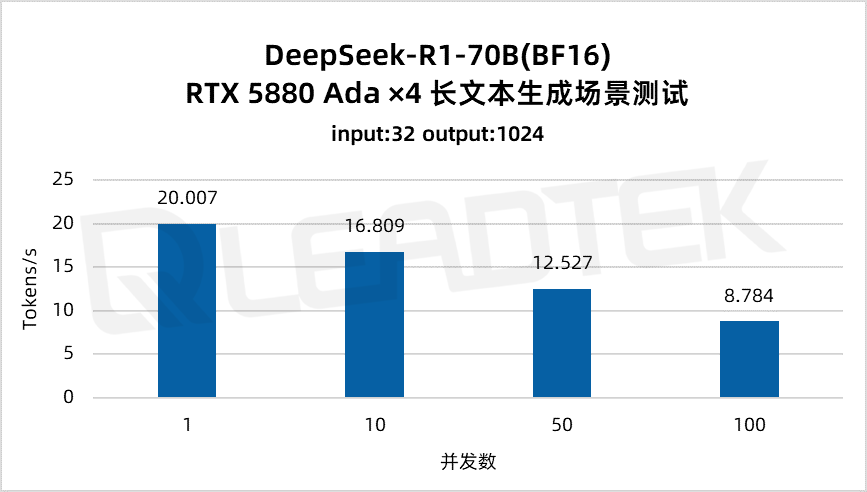
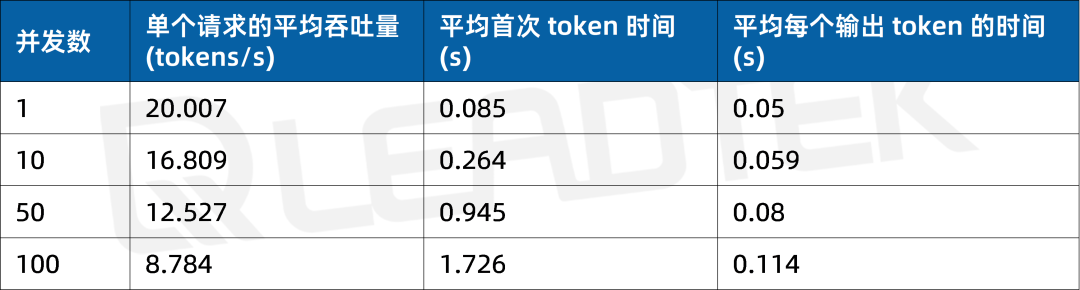
▲ DeepSeek-R1-70B(BF16) 測試結果圖表
使用 DeepSeek-R1-32B(BF16),單請求吞吐量達約 39.7 tokens/s,并發 250 時仍保持約 10.6 tokens/s,能夠滿足較高并發場景(250 并發)。
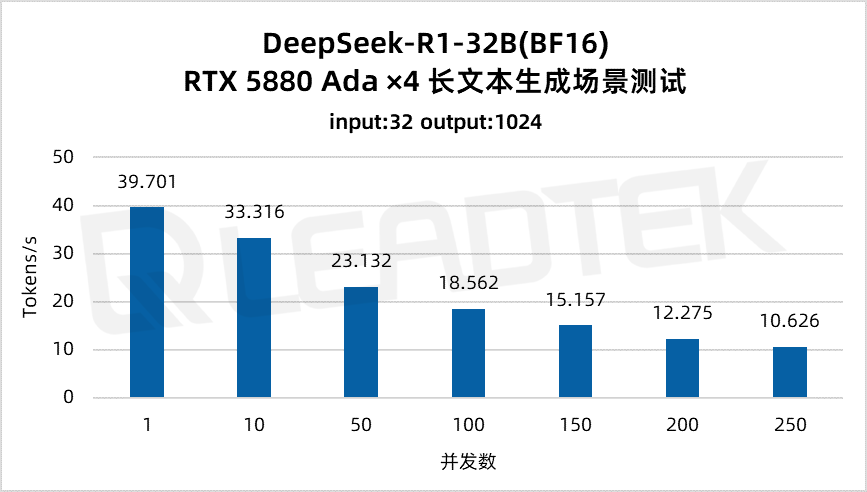
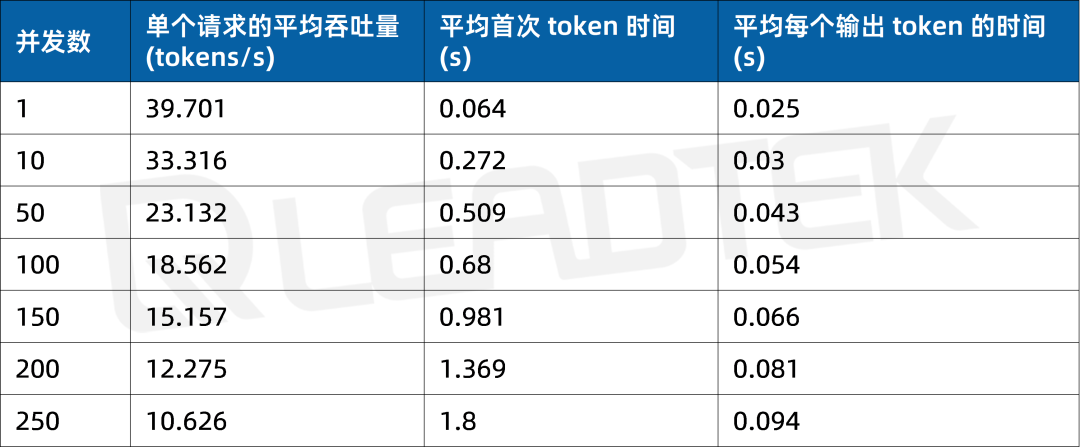
▲ DeepSeek-R1-32B(BF16) 測試結果圖表
4.3 總結概括場景
使用 DeepSeek-R1-70B(BF16),單請求吞吐量約 18.7 tokens/s,并發 10 時降至約 10.9 tokens/。最佳工作區間為低并發場景(10 并發)。
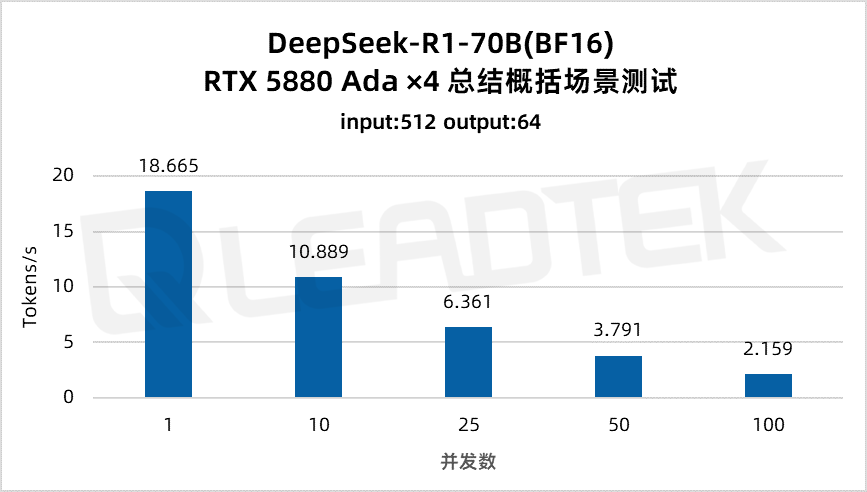
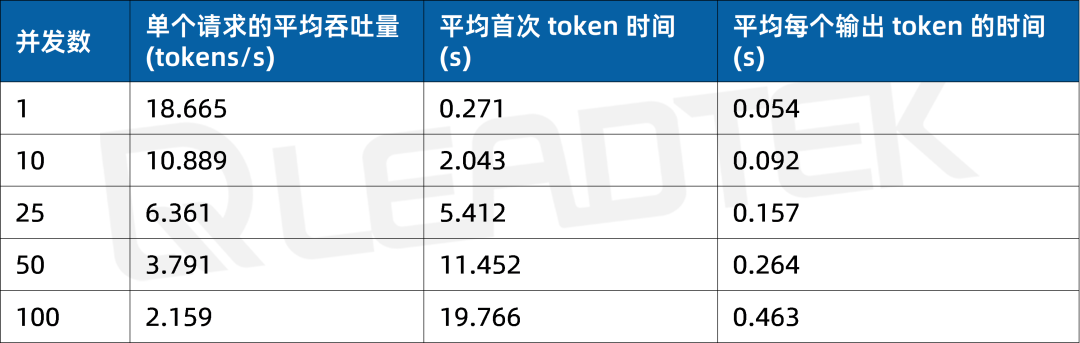
▲ DeepSeek-R1-70B(BF16) 測試結果圖表
使用 DeepSeek-R1-32B(BF16),單請求吞吐量達約 37 tokens/s,并發 25 時仍保持約 15.3 tokens/s,能夠滿足中等并發場景(25 并發)。
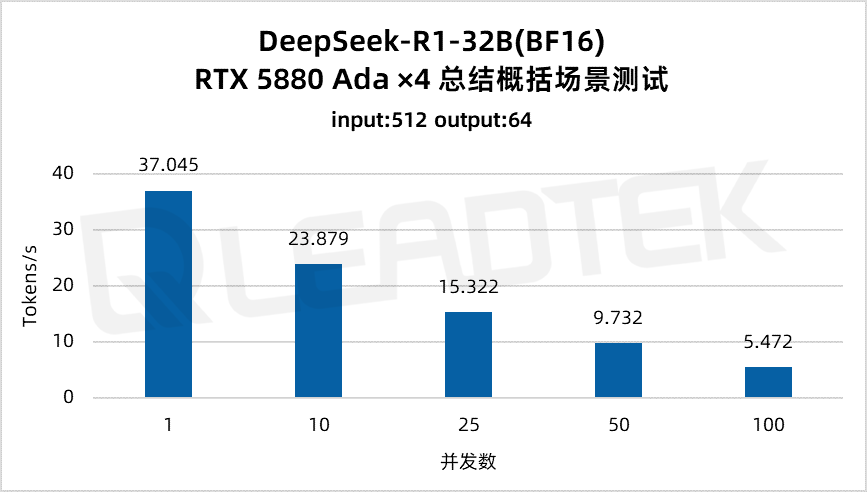
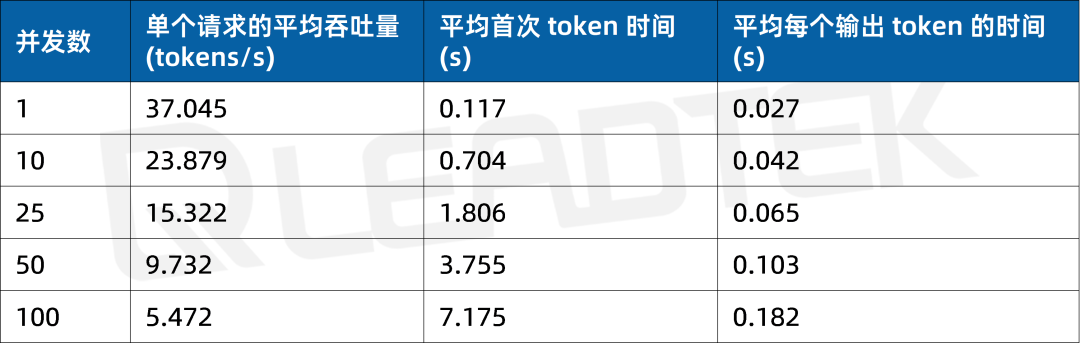
▲ DeepSeek-R1-32B(BF16) 測試結果圖表
5總結
5.1 測試模型性能
DeepSeek-R1-70B(BF16) 模型表現:
短文本生成:支持 75 并發量,單請求平均吞吐量>10.9 tokens/s
長文本生成:支持 50 并發量,單請求平均吞吐量>12.5 tokens/s
總結概括:支持 10 并發量,單請求平均吞吐量>10.9 tokens/s
DeepSeek-R1-32B(BF16) 模型表現:
短文本生成:支持 100 并發量,單請求平均吞吐量>18.1 tokens/s
長文本生成:支持 250 并發量,單請求平均吞吐量>10.6 tokens/s
總結概括:支持 25 并發量,單請求平均吞吐量>15.3 tokens/s
5.2 部署建議
基于 4 卡 RTX 5880 Ada GPU 的硬件配置下:
推薦優先部署 DeepSeek-R1-32B(BF16) 模型,其在高并發場景下展現出更優的吞吐性能與響應效率;
當業務場景對模型輸出質量有更高要求,且系統并發壓力較低時,建議選用 DeepSeek-R1-70B(BF16) 模型。
5.3 測試說明
本次基準測試在統一硬件環境下完成,未采用任何專項優化策略。
-
NVIDIA
+關注
關注
14文章
5160瀏覽量
104844 -
顯卡
+關注
關注
16文章
2490瀏覽量
68721 -
模型
+關注
關注
1文章
3434瀏覽量
49559 -
DeepSeek
+關注
關注
1文章
690瀏覽量
546
原文標題:4 卡戰 70B/32B!RTX 5880 Ada 跑 DeepSeek-R1 結果如何?
文章出處:【微信號:Leadtek,微信公眾號:麗臺科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何使用OpenVINO運行DeepSeek-R1蒸餾模型

在龍芯3a6000上部署DeepSeek 和 Gemma2大模型
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
RK3588開發板上部署DeepSeek-R1大模型的完整指南
NVIDIA RTX 5000 Ada顯卡性能實測報告

RTX 5880 Ada Generation GPU與RTX? A6000 GPU對比

芯動力神速適配DeepSeek-R1大模型,AI芯片設計邁入“快車道”!

deepin UOS AI接入DeepSeek-R1模型
DeepSeek-R1本地部署指南,開啟你的AI探索之旅

廣和通支持DeepSeek-R1蒸餾模型
Deepseek R1大模型離線部署教程

超星未來驚蟄R1芯片適配DeepSeek-R1模型

行芯完成DeepSeek-R1大模型本地化部署
在英特爾哪吒開發套件上部署DeepSeek-R1的實現方式






 工商網監
工商網監

評論