

? 論文鏈接:
https://arxiv.org/abs/2503.05689
?項(xiàng)目鏈接:
https://github.com/YvanYin/GoalFlow
概述
自動(dòng)駕駛軌跡規(guī)劃往往采用直接回歸軌跡的方法,這種方式雖在測(cè)試中能取得不錯(cuò)的性能,可直接輸出當(dāng)前場(chǎng)景下最有可能的軌跡或控制,但它難以對(duì)自動(dòng)駕駛場(chǎng)景中常見(jiàn)的多模態(tài)動(dòng)作分布進(jìn)行有效建模。在實(shí)際駕駛場(chǎng)景里,往往不存在唯一的最優(yōu)決策,不同的路況、交通標(biāo)志以及其他道路使用者的行為等,都可能導(dǎo)致車輛存在多種合理的行駛軌跡選擇,而回歸模型在處理這種多模態(tài)特性時(shí)顯得力不從心。為了解決這個(gè)問(wèn)題,我們提出了一種基于goal point的生成式方法GoalFlow,通過(guò)使用goal point這種強(qiáng)引導(dǎo)信息來(lái)引導(dǎo)生成式模型生成安全、高質(zhì)量、多模態(tài)的規(guī)劃軌跡。我們的方法在公開(kāi)數(shù)據(jù)集Navsim綜合分?jǐn)?shù)大幅領(lǐng)先其他方法。同時(shí),通過(guò)Flow Matching對(duì)軌跡分布進(jìn)行建模僅用一步降噪即可實(shí)現(xiàn)優(yōu)秀的推理性能。
GoalFlow解決的問(wèn)題
當(dāng)前生成多模態(tài)候選軌跡的方法主要由兩種方式:一種是在回歸軌跡的基礎(chǔ)上添加不同的引導(dǎo)信息,例如左右轉(zhuǎn)等。另一種是通過(guò)擴(kuò)散模型這種連續(xù)建模的方式通過(guò)不斷加噪和去噪來(lái)生成眾多的軌跡。這兩種方式都很難達(dá)到理想的效果。前者容易發(fā)生軌跡的坍縮,引導(dǎo)出的軌跡非常相似。后者容易生成高度發(fā)散的軌跡,這為挑選軌跡增加了難度。為此,GoalFlow主要思考如何探索其他可行道路來(lái)實(shí)現(xiàn)高質(zhì)量的候選軌跡生成。
如何應(yīng)對(duì)生成式模型軌跡過(guò)于發(fā)散的情況
相比生成眾多發(fā)散的候選軌跡,從中挑選出來(lái)一條最優(yōu)的作為輸出是更加困難的事情。我們希望通過(guò)降低軌跡的發(fā)散程度來(lái)減輕軌跡打分器的壓力。而其中,使用什么樣的信息來(lái)對(duì)軌跡進(jìn)行約束是最重要的。我們發(fā)現(xiàn),相比于dense的圖像或者BEV特征,擴(kuò)散模型更喜歡sparse的信息。于是,我們采用一段軌跡中最重要的點(diǎn)end point作為goal point來(lái)對(duì)軌跡進(jìn)行約束,使得車輛能行駛到goal point。
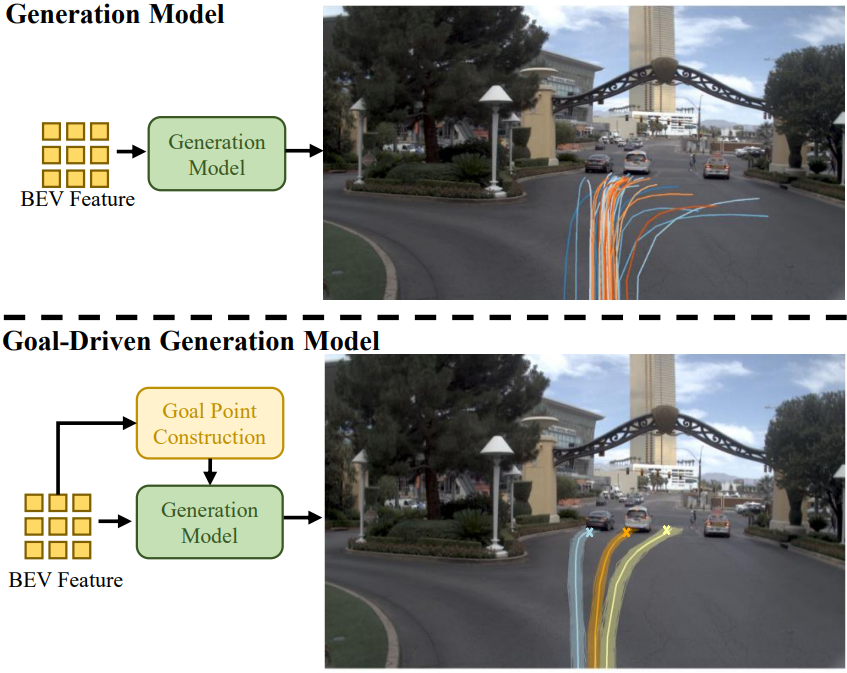
如何構(gòu)造goal point
goal point在自動(dòng)駕駛中并不是個(gè)新事物,業(yè)務(wù)中往往可以使用車道信息來(lái)預(yù)測(cè)goal point或者使用直接將導(dǎo)航作為goal point。但是車道信息往往需要昂貴的高精地圖,而導(dǎo)航往往并不表示車輛在未來(lái)幾秒后的精確信息。其他學(xué)術(shù)上的方法也有map-free的用網(wǎng)格將空間劃分若干單元來(lái)進(jìn)行預(yù)測(cè),這種方式又沒(méi)有充分考慮到goal point自身的分布特性。在調(diào)研眾多方法后,我們根據(jù)VADv2的做法,首先將軌跡的末端點(diǎn)進(jìn)行聚類得到goal point的分布特性后,再?gòu)牟煌嵌葘?duì)goal point進(jìn)行評(píng)估。
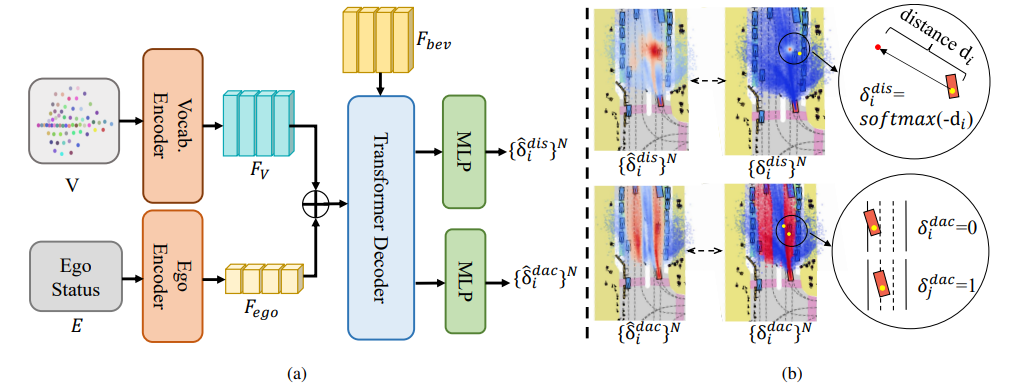
如何平衡生成準(zhǔn)確軌跡和多模態(tài)軌跡
輸入給生成模型的信息包括兩種,一種是goal point來(lái)對(duì)軌跡進(jìn)行約束和引導(dǎo),一種是場(chǎng)景信息的BEV特征。前者對(duì)軌跡的要求是生成指向goal point的軌跡,后者是生成當(dāng)前情況下最有可能的軌跡。為了平衡這兩種需求,我們主要進(jìn)行了訓(xùn)練策略上的不同測(cè)試。具體來(lái)說(shuō),我們會(huì)對(duì)這兩種信息分別進(jìn)行類型編碼,在訓(xùn)練過(guò)程中采用Classifier-Free Guidance策略,隨機(jī)drop掉這兩種特征。訓(xùn)練時(shí)condition輸入包括三類:無(wú)condition,場(chǎng)景信息作為condition以及場(chǎng)景信息和goal point作為condition。
GoalFlow框架
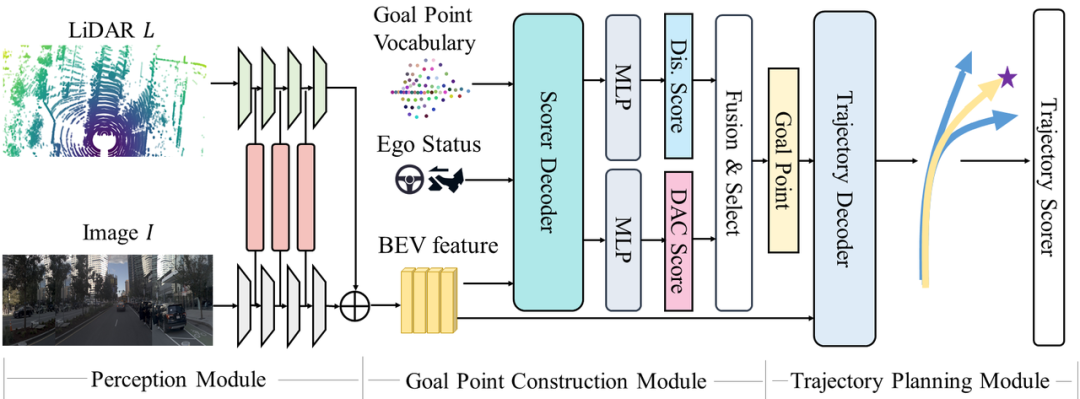
核心思路:引入goal point作為引導(dǎo)信息,通過(guò)建立dense的goal point詞匯表和新穎評(píng)分機(jī)制挑選最優(yōu)goal point,再由goal point和場(chǎng)景信息作為condition,交給Flow Matching生成軌跡。
具體流程:
感知方面上采用transfuser,融合圖像和LiDAR信息,得到BEV feature。
通過(guò)聚類數(shù)據(jù)集中的軌跡末端點(diǎn)得到dense的goal point詞表,作為goal point的候選集。
將goal point和真實(shí)end point的遠(yuǎn)近程度以及goal point是否在車輛可行駛區(qū)域內(nèi)作為評(píng)價(jià)標(biāo)準(zhǔn),從詞表中挑選出當(dāng)前最優(yōu)的goal point。
引入flow matching對(duì)軌跡進(jìn)行連續(xù)建模,將場(chǎng)景信息和goal point作為condition生成軌跡。
實(shí)驗(yàn)結(jié)果
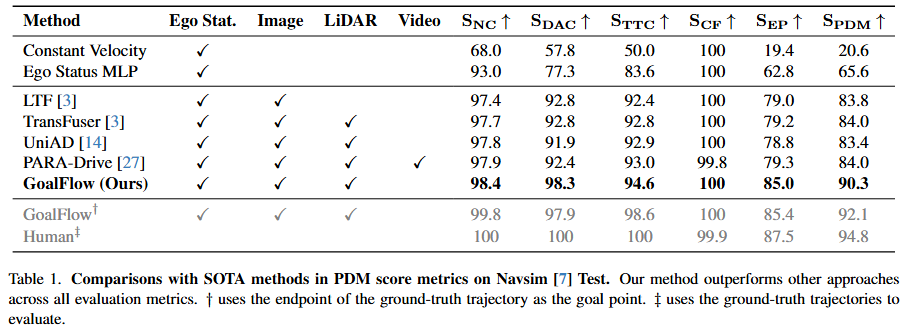
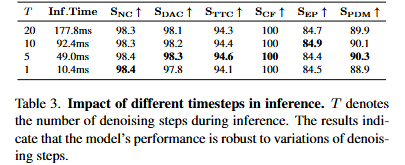
在Navsim數(shù)據(jù)集上,軌跡采用碰撞率,是否在可行駛區(qū)域內(nèi),舒適度等綜合指標(biāo)PDMS來(lái)評(píng)價(jià)。GoalFlow在PDMS上達(dá)到90.3分,遠(yuǎn)超以regression為代表的Transfuser方法(84.0分)和naive的generative model(85.6分)。模擬真實(shí)場(chǎng)景用更精確goal point代替預(yù)測(cè)goal point時(shí),PDMS達(dá)到92.1分,逼近人類駕駛的94.8分。此外,基于flow matching的方法對(duì)推理中denoising步數(shù)具有魯棒性,只需1步推理就能達(dá)到優(yōu)異性能,大大減輕自動(dòng)駕駛硬件負(fù)擔(dān)。
展望與總結(jié)
GoalFlow通過(guò)聚類方法捕捉目標(biāo)點(diǎn) (goal point) 的分布特性,并設(shè)計(jì)了一套目標(biāo)點(diǎn)評(píng)估機(jī)制,為目標(biāo)點(diǎn)進(jìn)行打分。基于這些目標(biāo)點(diǎn),GoalFlow引導(dǎo)生成式方法Flow Matching生成高質(zhì)量軌跡。實(shí)驗(yàn)表明,GoalFlow能夠生成優(yōu)異的軌跡,并提供多樣化的高質(zhì)量軌跡候選,顯著提升了軌跡生成的性能。
未來(lái),我們將進(jìn)一步探索如何優(yōu)化引導(dǎo)信息的利用,尤其是設(shè)計(jì)更高效的網(wǎng)絡(luò)結(jié)構(gòu),以更好地平衡場(chǎng)景信息和目標(biāo)點(diǎn)引導(dǎo)信息對(duì)模型的影響。此外,當(dāng)前工作主要聚焦于坐標(biāo)位置作為引導(dǎo)條件,之后可以進(jìn)一步探索將人類語(yǔ)言指令作為條件輸入,結(jié)合GoalFlow實(shí)現(xiàn)更智能的指令跟隨能力,拓展其在人機(jī)交互和自動(dòng)駕駛等領(lǐng)域的應(yīng)用潛力。
-
模型
+關(guān)注
關(guān)注
1文章
3434瀏覽量
49557 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
788文章
14037瀏覽量
168091
原文標(biāo)題:CVPR 2025|GoalFlow:目標(biāo)點(diǎn)驅(qū)動(dòng),解鎖端到端生成式策略新未來(lái)
文章出處:【微信號(hào):horizonrobotics,微信公眾號(hào):地平線HorizonRobotics】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
未來(lái)已來(lái),多傳感器融合感知是自動(dòng)駕駛破局的關(guān)鍵
如何基于深度神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)一個(gè)端到端的自動(dòng)駕駛模型?
端到端自動(dòng)駕駛到底是什么?
基于矢量化場(chǎng)景表征的端到端自動(dòng)駕駛算法框架

基于端到端的Al自動(dòng)駕駛決策方法
佐思汽研發(fā)布《2024年端到端自動(dòng)駕駛研究報(bào)告》

實(shí)現(xiàn)自動(dòng)駕駛,唯有端到端?

Mobileye端到端自動(dòng)駕駛解決方案的深度解析

Waymo利用谷歌Gemini大模型,研發(fā)端到端自動(dòng)駕駛系統(tǒng)
連接視覺(jué)語(yǔ)言大模型與端到端自動(dòng)駕駛

端到端自動(dòng)駕駛技術(shù)研究與分析
DiffusionDrive首次在端到端自動(dòng)駕駛中引入擴(kuò)散模型

動(dòng)量感知規(guī)劃的端到端自動(dòng)駕駛框架MomAD解析
一種多模態(tài)駕駛場(chǎng)景生成框架UMGen介紹
技術(shù)分享 |多模態(tài)自動(dòng)駕駛混合渲染HRMAD:將NeRF和3DGS進(jìn)行感知驗(yàn)證和端到端AD測(cè)試






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論