

3月19日凌晨,NVIDIA 創(chuàng)始人兼首席執(zhí)行官黃仁勛在2025年GTC開發(fā)者大會(huì)上發(fā)表了主題演講,演講覆蓋了AI科技演進(jìn)以及計(jì)算需求,同時(shí)公布了英偉達(dá)的Blackwell架構(gòu)最新一代產(chǎn)品、未來幾代產(chǎn)品的計(jì)劃出貨時(shí)間,以及英偉達(dá)在人形機(jī)器人領(lǐng)域的最新進(jìn)展。

圖源:英偉達(dá)官方視頻,下同
演講期間,黃仁勛再次提到AI技術(shù)的進(jìn)化路徑,從 Perception 感知AI到 Generative生成式AI,再到現(xiàn)階段發(fā)展火熱Agentic代理型AI,最終實(shí)現(xiàn)具備傳感與執(zhí)行功能的Physical 物理型AI。黃仁勛認(rèn)為AI的終極形態(tài)Physical AI將徹底改變世界。
以下是演講的核心內(nèi)容與關(guān)鍵發(fā)布:
一、硬件革新:Blackwell架構(gòu)及未來路線圖
Blackwell Ultra芯片
采用臺(tái)積電4NP工藝,單卡FP4算力達(dá)15 PetaFLOPS,HBM3e顯存容量提升至288GB,推理速度較前代Hopper提升11倍8。
機(jī)架級(jí)解決方案GB300 NVL72集成72顆GPU,支持液冷技術(shù),推理性能達(dá)每秒1000 tokens(H100的10倍)。性能提升源于NVLink 72高速互聯(lián)技術(shù),將多GPU組合成“巨型GPU”,突破算力瓶頸。
未來架構(gòu)規(guī)劃
Rubin架構(gòu)(2026年發(fā)布):采用NVLink 144互聯(lián)技術(shù),HBM4內(nèi)存帶寬提升2倍,2027年Ultra版性能將達(dá)Blackwell的14倍。
Feynman架構(gòu)(2028年):以物理學(xué)家費(fèi)曼命名,目標(biāo)實(shí)現(xiàn)算力成本指數(shù)級(jí)下降。
二、軟件生態(tài)與工具升級(jí)
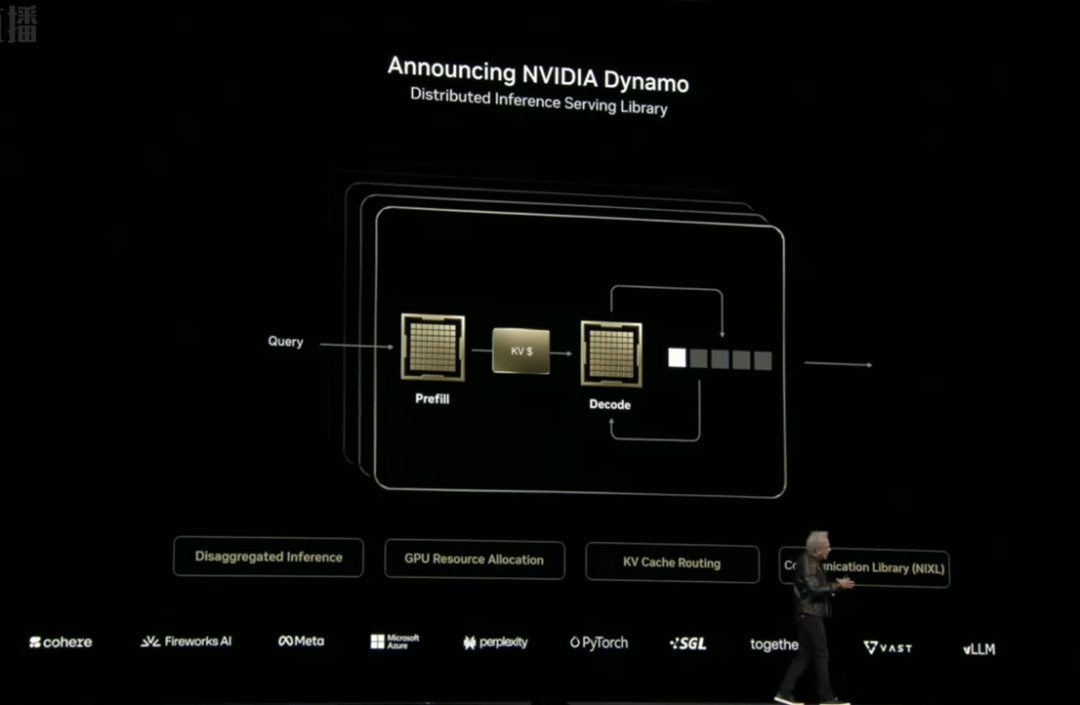
Dynamo推理操作系統(tǒng)
開源動(dòng)態(tài)調(diào)度系統(tǒng),優(yōu)化GPU資源分配,使Hopper平臺(tái)運(yùn)行Llama模型的吞吐量提升30倍,并支持KV緩存管理。在DeepSeek-R1模型測(cè)試中,單GPU生成token數(shù)量提升30倍以上。
CUDA生態(tài)擴(kuò)展
CUDA-X庫新增工具:Newton物理引擎(與DeepMind、迪士尼合作):提升機(jī)器人訓(xùn)練效率10倍。
cuOpt數(shù)學(xué)規(guī)劃工具:加速千倍,已與Gurobi、IBM合作。
開發(fā)者生態(tài):全球開發(fā)者突破600萬,加速庫增至900+,覆蓋量子計(jì)算、生物醫(yī)學(xué)等領(lǐng)域。
三、AI發(fā)展階段論與物理AI的推進(jìn)
AI三階段演進(jìn)路徑
感知人工智能(Perception AI):大約10年前啟動(dòng),專注于語音識(shí)別和其他簡(jiǎn)單任務(wù)。
生成式人工智能(Generative AI):過去5年的重點(diǎn),涉及通過預(yù)測(cè)模式進(jìn)行文本和圖像創(chuàng)建。
代理人工智能(Agentic AI):人工智能以數(shù)字方式交互并自主執(zhí)行任務(wù)的當(dāng)前階段,以推理模型為特征。
物理 AI(Physical AI):AI 的未來,為人形機(jī)器人和現(xiàn)實(shí)世界的應(yīng)用提供動(dòng)力。
物理AI落地實(shí)踐
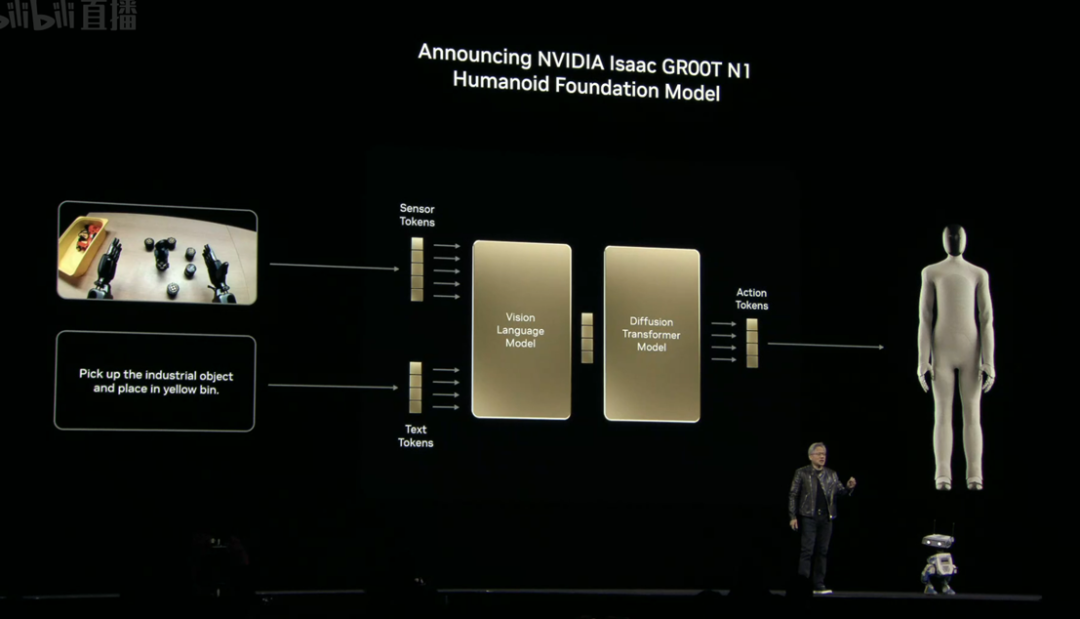
開源人形機(jī)器人基礎(chǔ)模型Isaac GR00T N1:支持雙系統(tǒng)認(rèn)知(慢思考規(guī)劃+快思考執(zhí)行),可遷移至工業(yè)制造場(chǎng)景。
與通用汽車合作構(gòu)建全棧自動(dòng)駕駛系統(tǒng):覆蓋數(shù)字孿生仿真與車載AI安全架構(gòu)HALOS。
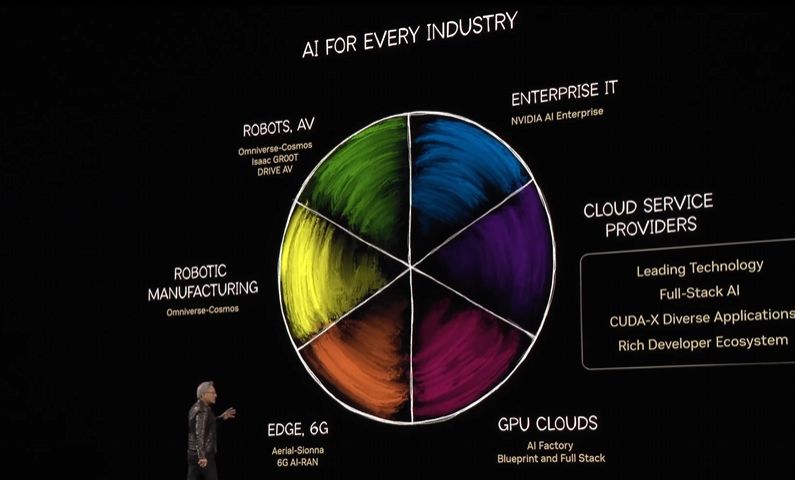
四、行業(yè)應(yīng)用與合作案例
企業(yè)級(jí)AI解決方案
DGX Spark:售價(jià)3000美元的桌面級(jí)工作站,支持本地化模型微調(diào)。
語義存儲(chǔ)系統(tǒng):與Box合作,支持自然語言數(shù)據(jù)檢索。
邊緣與通信技術(shù)
聯(lián)合思科、T-Mobile構(gòu)建AI-RAN(AI無線網(wǎng)絡(luò)),優(yōu)化5G信號(hào)處理與能耗。
硅光子技術(shù)突破:全球首個(gè)1.6T共封裝光學(xué)(CPO),減少數(shù)據(jù)中心光模塊功耗90%。
硬件創(chuàng)新:Blackwell架構(gòu)引領(lǐng)算力飛躍
黃仁勛宣布Blackwell架構(gòu)已全面投產(chǎn),其性能和能效相比前代Hopper架構(gòu)都有顯著提升。基于臺(tái)積電4NP工藝的Blackwell Ultra芯片(B300系列)正式發(fā)布,單卡FP4算力達(dá)15 PetaFLOPS,HBM3E顯存容量提升至288GB,推理速度較前代Hopper提升11倍。Blackwell Ultra包括NVIDIA GB300 NVL72機(jī)架級(jí)解決方案和NVIDIA HGXT B300 NVL16系統(tǒng)。GB300 NVL72與上一代NVIDIA GB200 NL72相比,AI的性能提升5倍。GB300 NVL72連接了72個(gè)Blackwell Ultra GPU與36個(gè)基于Arm Neoverse的Grace CPU;NVIDIA HGX B300 NVL16與上一代相比,在大型語言模型上具有11倍推理速度、4倍內(nèi)存,可以為AI推理等復(fù)雜的工作負(fù)載提供突破性的性能。機(jī)架級(jí)解決方案GB300 NVL72集成72顆GPU,支持液冷技術(shù),推理性能達(dá)每秒1000 tokens,已獲亞馬遜AWS、微軟Azure等四大云廠商360萬片訂單。此外,英偉達(dá)還公布了下一代GPU架構(gòu)Vera Rubin和Feynman的路線圖,Vera Rubin架構(gòu)計(jì)劃于2026年推出,采用NVLink 144互聯(lián)技術(shù),HBM4內(nèi)存帶寬提升2倍;2028年發(fā)布的Feynman架構(gòu),目標(biāo)實(shí)現(xiàn)算力成本指數(shù)級(jí)下降。

軟件生態(tài)Dynamo與CUDA-X驅(qū)動(dòng)開發(fā)效率
英偉達(dá)推出了開源推理軟件Dynamo,它可將Hopper平臺(tái)運(yùn)行Llama模型的吞吐量提升30倍,支持動(dòng)態(tài)分配GPU資源,優(yōu)化KV緩存管理。在DeepSeek-R1模型測(cè)試中,Dynamo使GB200 NVL72集群的單GPU生成token數(shù)量提升30倍以上。CUDA-X庫新增Newton物理引擎,與DeepMind、迪士尼合作開發(fā),機(jī)器人訓(xùn)練效率提升10倍;cuOpt數(shù)學(xué)規(guī)劃工具加速千倍。全球開發(fā)者突破600萬,加速庫數(shù)量增至900+,覆蓋量子計(jì)算、生物醫(yī)學(xué)等前沿領(lǐng)域。
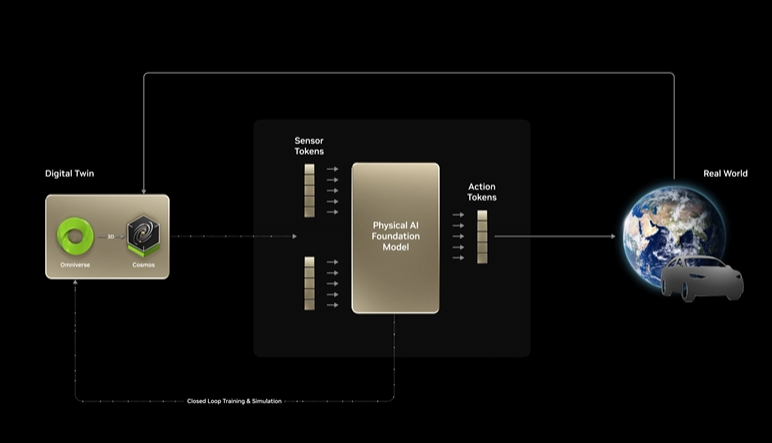
從自主型人工智能推理革命走向物理人工智能
黃仁勛闡述了AI發(fā)展的三階段演進(jìn)路徑:從感知AI(Perception AI)的計(jì)算機(jī)視覺和語音識(shí)別,到生成式AI(Generative AI)的多模態(tài)內(nèi)容生成,再到當(dāng)下熱門的代理式AI(Agentic AI),其具備主動(dòng)性,能感知并理解語境,制定并執(zhí)行計(jì)劃。未來則是物理AI(Physical AI)的時(shí)代,理解物理世界、三維世界的AI將推動(dòng)機(jī)器人、自動(dòng)駕駛等領(lǐng)域的發(fā)展。
演講期間,英偉達(dá)推出了開源人形機(jī)器人基礎(chǔ)模型Isaac GR00T N1,支持雙系統(tǒng)認(rèn)知,可遷移至工業(yè)制造場(chǎng)景。同時(shí),英偉達(dá)與通用汽車合作構(gòu)建全棧自動(dòng)駕駛系統(tǒng),覆蓋數(shù)字孿生仿真與車載AI安全架構(gòu)HALOS。
推動(dòng)CUDA生態(tài)進(jìn)化
英偉達(dá)在AI for Science領(lǐng)域的布局持續(xù)加深,開發(fā)人員現(xiàn)在可以利用CUDA-X與最新的superchip架構(gòu)實(shí)現(xiàn)CPU和GPU資源之間更緊密的自動(dòng)集成與協(xié)調(diào),與使用傳統(tǒng)加速計(jì)算架構(gòu)相比,其工程計(jì)算工具的速度提高11倍,計(jì)算量提高5倍。CUDA-X目前已經(jīng)在天文學(xué)、粒子物理學(xué)、量子物理學(xué)、汽車、航空航天和半導(dǎo)體設(shè)計(jì)等一系列新的工程學(xué)科帶來了加速計(jì)算。
AI工廠時(shí)代到來
黃仁勛特別強(qiáng)調(diào)了AI工廠的概念,Dynamo被比作新時(shí)代的VMware,能夠自動(dòng)編排如何讓AI在推理時(shí)代跑得更好。英偉達(dá)還推出了AI電腦DGX Spark和DGX Station,采用Blackwell芯片,助力企業(yè)構(gòu)建更高效的AI基礎(chǔ)設(shè)施。
小結(jié)
黃仁勛的演講全面展示了英偉達(dá)在AI領(lǐng)域的技術(shù)實(shí)力和戰(zhàn)略布局,從硬件的持續(xù)創(chuàng)新到軟件生態(tài)的完善,再到對(duì)AI發(fā)展階段的深刻洞察,英偉達(dá)正致力于推動(dòng)AI技術(shù)從從自主型人工智能推理革命走向物理人工智能終局。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5142瀏覽量
104749 -
AI
+關(guān)注
關(guān)注
87文章
32740瀏覽量
272148 -
人工智能
+關(guān)注
關(guān)注
1801文章
48185瀏覽量
242735
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
NVIDIA GTC 2025精華一文讀完 黃仁勛在GTC上的主題演講

看點(diǎn):黃仁勛再談DeepSeek 西門子將裁員5600人 字節(jié)高層再談AI方向
黃仁勛親筆簽名,阿丘科技斬獲年度優(yōu)秀創(chuàng)業(yè)公司

CES 2025:黃仁勛展望AI助手融入未來的愿景
2025年CES展:英偉達(dá)CEO黃仁勛將發(fā)表演講并可能進(jìn)行HBM對(duì)談
NVIDIA CEO黃仁勛對(duì)話香港科技大學(xué)畢業(yè)生
NVIDIA CEO黃仁勛在SC24發(fā)表演講
黃仁勛:AI未來關(guān)鍵在于推理,芯片成本驟降成核心要素
NVIDIA CEO黃仁勛在 SIGGRAPH 2024 主題演講中或將首次亮相消費(fèi)級(jí)GPU Blackwell

黃仁勛:新一輪科技浪潮將是物理AI機(jī)器人的崛起
黃仁勛:人工智能和加速計(jì)算的交匯將重新定義未來
英偉達(dá)CEO黃仁勛展望AI與機(jī)器人新時(shí)代
“加速一切”,NVIDIA CEO 黃仁勛在 COMPUTEX 開幕前發(fā)表主題演講






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論