

故障現象
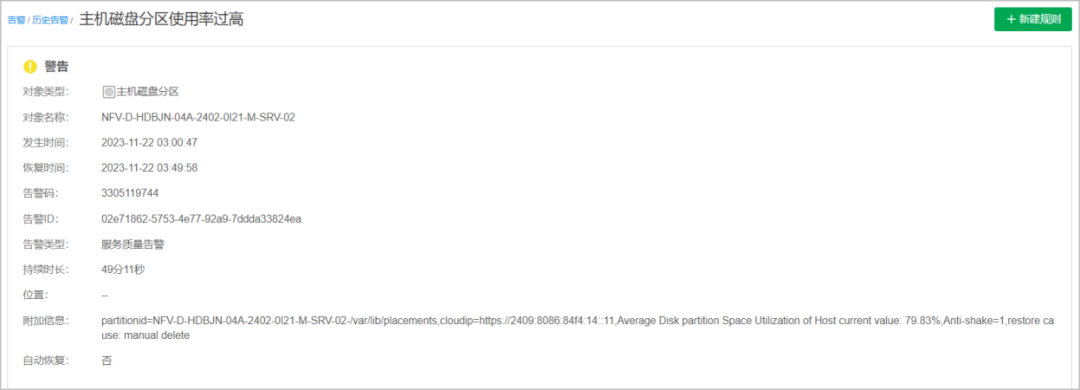
某運營商TECS資源池上報“主機磁盤分區使用率過高”的告警,如下圖所示。
故障分析
查看“主機磁盤分區使用率過高”告警詳情,通過處理當前告警的節點和對應的磁盤分區能夠快速的處理和恢復告警。
告警處理完成后需要進一步排查分區增長的原因,有如下4種情況:
空間分配不足,規劃的分區空間不滿足現場集群和規模的要求。
出現大量crash和異常debug日志短時間沖擊磁盤分區,可能是人為或者進程死循環導致。
日志文件或者定期輪詢文件未生效,導致歷史文件超限。
后端存儲異常或者后端存儲復用,導致磁盤使用率過高。
具體分析過程如下:
1. 根據告警詳細信息,使用SSH方式登錄相應節點。
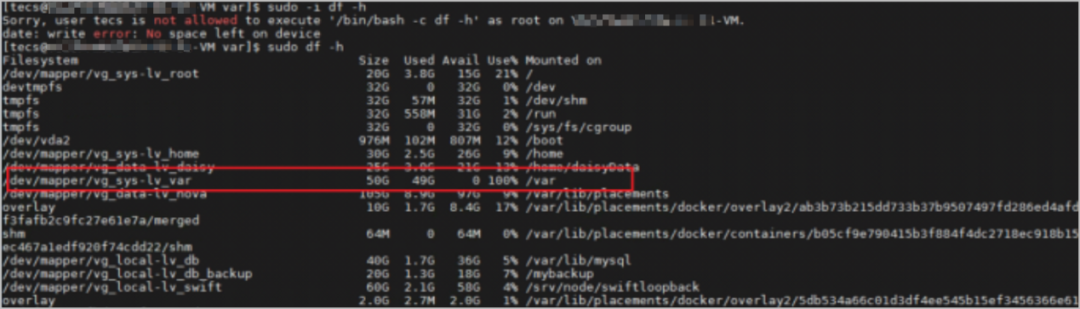
2. 在異常節點中執行df -h命令,檢查輸出和操作系統運行情況,查看是否有系統只讀不可寫等系統內核崩潰情況,如下圖所示。
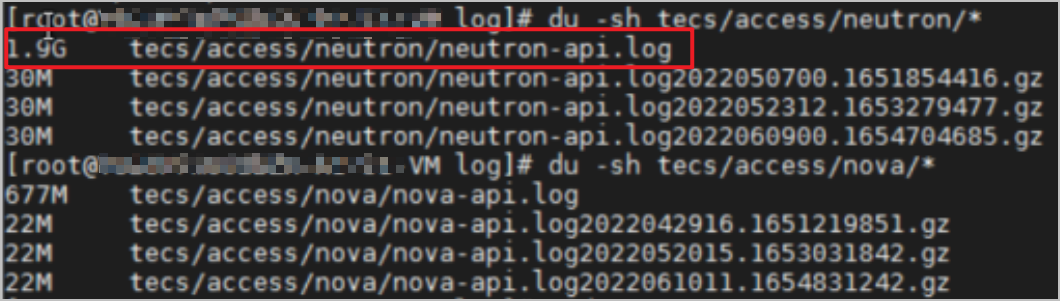
3. 檢查/var目錄下是否有過大問題。通過在每級目錄中執行du -sh * 命令,檢查文件大小,從而排查最大異常問題,按照經驗var下異常大小文件一般是/var/log下的日志,如下圖所示。
4. 檢查日志存儲文件大小,如下圖所示。
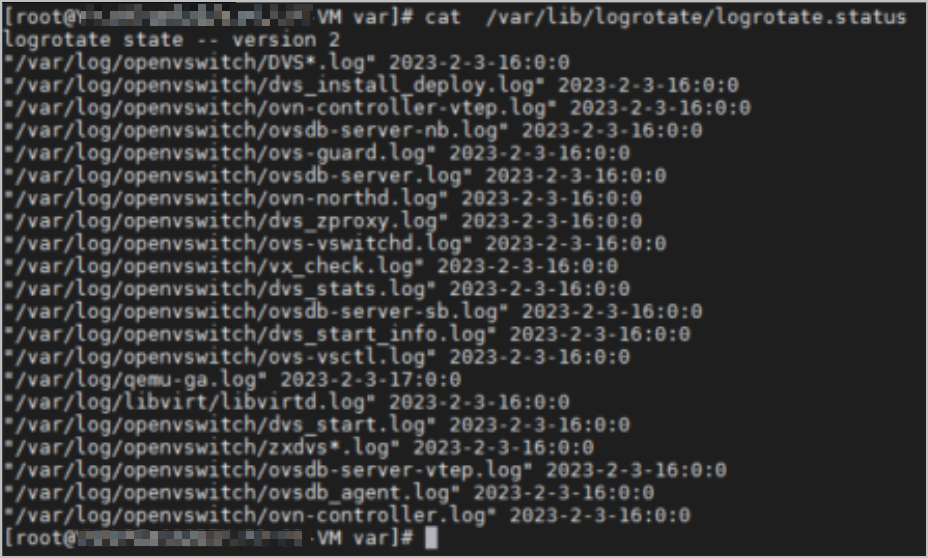
5. 根據檢查結果發現,logrotate機制未生效,日志文件未按照設定參數被壓縮,轉儲不成功,導致日志文件過大,占用磁盤空間。
故障處理
1. 執行如下命令,清理磁盤。
a. 執行> /var/lib/logrotate/logrotate.status命令,清空轉儲記錄。
b. 執行logrotate -d /etc/logrotate.conf命令,手動進行日志轉儲。
c. 執行echo > /var/log/tecs/access/neutron/neutron-api.log命令,寫入空,覆蓋到日志文件內,如下圖所示。

2. 清理完成后重新檢查文件大小和磁盤占用情況,問題解決。
3. 總結:對于磁盤分區使用率高問題,如果使用率達到100%就會導致節點不可用,系統自動備份失敗,數據庫定時備份失敗,無法登錄root用戶,等相關問題,存在很大的隱患,發現問題需要盡快定位對象主機上磁盤占用高的文件,進行處理。
本次是由于logrotate機制未生效,日志文件未按照設定參數被壓縮、轉儲,從而使日志文件不停增大,占用全部磁盤空間導致。
清理文件,觸發轉儲服務后,磁盤占用恢復正常。
建議定期檢查系統磁盤空間占用,預防此類事件發生。
-
主機
+關注
關注
0文章
1024瀏覽量
35611 -
磁盤
+關注
關注
1文章
386瀏覽量
25457 -
命令
+關注
關注
5文章
712瀏覽量
22400
原文標題:TECS OpenStack-資源池主機磁盤分區使用率過高的問題處理
文章出處:【微信號:ztedoc,微信公眾號:中興文檔】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【雨林木風系統下載教程】利用XP系統磁盤分區來提升讀寫...
Linux系統教程之磁盤分區和LVM系統的詳細資料概述
Windows 10 2004版或解決CPU和磁盤使用率過高的問題
微軟Windows 10研究新的方法管理現代磁盤分區
微軟Win10搜索磁盤和CPU使用率過高的問題修復
獲取磁盤分區UUID的方法介紹

linux系統如何進行磁盤分區?
磁盤分區工具parted的使用方法
TECS OpenStack資源池虛機殘留導致網元異常的問題處理
TECS OpenStack資源池時間同步失敗的故障分析

TECS OpenStack資源池虛機寫磁盤時延高告警的問題處理





 工商網監
工商網監

評論