 一種多模態駕駛場景生成框架UMGen介紹
一種多模態駕駛場景生成框架UMGen介紹
? 論文地址:
https://arxiv.org/abs/2503.14945
?項目主頁:
https://yanhaowu.github.io/UMGen/
概述
端到端自動駕駛技術的快速發展對閉環仿真器提出了迫切需求,而生成式模型為其提供了一種有效的技術架構。然而,現有的駕駛場景生成方法大多側重于圖像模態,忽略了其他關鍵模態的建模,如地圖信息、智能交通參與者等,從而限制了其在真實駕駛場景中的適用性。
為此,我們提出了一種多模態駕駛場景生成框架——UMGen,該框架能夠全面預測和生成駕駛場景中的核心元素,包括自車運動、靜態環境、智能交通參與者以及圖像信息。具體而言,UMGen將場景生成建模為Next-Scene Prediction任務,利用幀間并行自回歸與幀內多模態自回歸技術,使得一個統一模型即可生成以自車為中心、模態協同一致的駕駛場景序列。UMGen生成的每個場景均包含自車、地圖、交通參與者、圖像等多種模態信息,并可靈活擴展至更多模態,以適應不同應用需求。
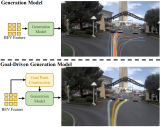
UMGen不僅能夠靈活生成多樣化的駕駛場景,還支持基于用戶設定生成特定駕駛情境,例如控制自車執行左轉、右轉,或模擬他車cut-in等復雜交互行為。憑借這一交互式生成能力,UMGen可為自動駕駛系統的訓練提供稀缺樣本,從而提升模型的泛化能力。同時,它還可用于構建閉環仿真環境,對端到端自動駕駛系統進行全面測試與優化,甚至支持自博弈式訓練,進一步增強系統的智能決策能力。
UMGen生成的多模態場景,視頻中的每一個模態(自車動作,地圖,交通參與者,圖像)都由模型自行想象生成
方法
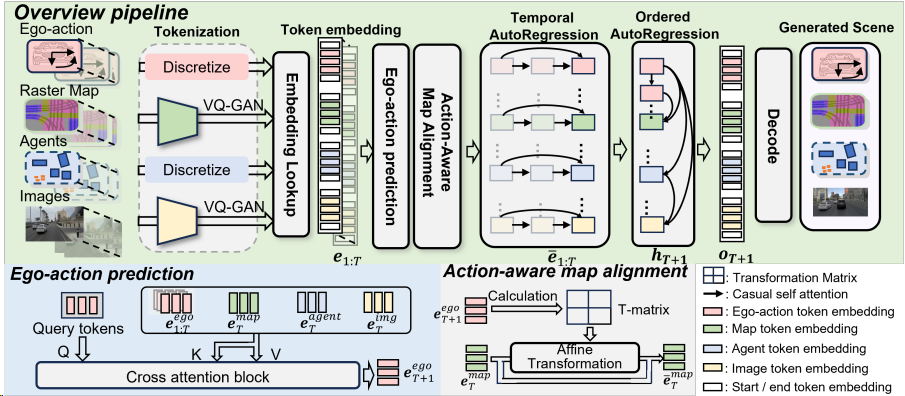
Pipeline of UMGen
UMGen從給定的初始場景序列開始,逐場景、自回歸地生成多模態駕駛場景。我們首先根據歷史信息預測自車要采取的動作,然后根據這一動作預測觀察到的地圖變化,以及其他交通參與者的行動,最后將這些信息映射到圖像中。為實現這一目標,我們將每個時刻的場景元素(包括自車動作、地圖、交通參與者以及攝像頭圖像)轉換為有序的token序列,從而將生成任務轉化為Next-token Prediction任務。一個很直觀的想法是將來自不同幀、不同模態的token直接拼接在一起,然后使用一個decoder-only的transformer進行預測。但是這樣做,token數量會隨著場景長度的增加而迅速增加,使得算力需求變得無法接受。
為了解決這一問題,我們提出了一種兩階段序列預測方法,將整體任務劃分為幀間預測和幀內預測兩個階段。在幀間預測階段,我們設計了時序自回歸模塊 (TAR) ,該模塊通過因果注意力機制對幀間的時序演化進行建模,確保每個token僅依賴于其歷史狀態,從而捕捉時間維度上的動態變化。在幀內預測階段,我們引入了有序自回歸模塊 (OAR) ,該模塊通過指定幀內模態生成的順序(自車動作→地圖元素→交通參與者→攝像頭圖像,如下視頻所示),建立場景內不同模態之間的關聯,從而保證模態間的一致性。TAR和OAR模塊協同工作,不僅有效捕捉了跨模態的時序依賴關系,還顯著降低了計算復雜度,為高效生成多模態駕駛場景提供了技術保障。同時,為了增強自車動作與地圖變化之間的模態一致性,我們還提出了AMA模塊,根據自車動作計算affine transformation矩陣對地圖特征進行變換,充分利用地圖這種靜態元素的時序先驗提升預測精度。
UMGen生成過程可視化
實驗及可視化
UMGen在nuPlan數據集上進行訓練,并通過可視化和定量實驗證明其具備自由幻想多模態駕駛場景的能力,以及按照用戶需求生成特定駕駛場景的能力。此外,我們還展示了UMGen在閉環仿真中的應用潛力:通過將自定義的自車動作注入UMGen中替換生成的自車動作,UMGen實時生成了相對應的下一時刻場景。
以下對部分實驗結果進行展示。
自由幻想生成駕駛場景序列
由UMGen自主推理生成場景,用戶不對UMGen提供任何額外的控制信號。
A. 生成長時序多模態駕駛場景
B. 生成多樣駕駛場景
自車受控下的場景生成
用戶控制自車動作以生成指定行為模式下的多模態場景。
A. 在路口控制自車直行或者右轉
B. 控制自車停車等待或者變道超車
用戶指定的場景生成
在此模式下,用戶可通過控制指定交通參與者的動作以創造場景。
在該場景中,通過設定黑色汽車的橫向速度,我們創造了一個"他車突然變道插入"的危險場景,并控制自車剎車或者變道完成規避。
利用Diffusion Model進一步提升圖像
質量
受到近期Diffusion模型的啟發,我們訓練了一個基于transformer的Diffusion模型。通過將UMGen生成的token作為condition,我們實現了更高質量的圖像生成。
小圖為原始生成圖像,大圖為Diffusion模型生成圖像
總結
UMGen在統一框架內實現了多模態駕駛場景的生成,每個場景包含自車動作、地圖、交通參與者以及對應的圖像信息。其交互式生成的能力,展現了廣泛的應用潛力, 如作為閉環仿真器的核心組件以及corner case數據生成器等。在未來的研究中,將更多模態數據(如激光雷達點云)納入生成框架中,將是一個值得探索的方向,這有望進一步提升場景生成的豐富性和實用性。
-
模型
+關注
關注
1文章
3438瀏覽量
49595 -
自動駕駛
+關注
關注
788文章
14048瀏覽量
168193
原文標題:CVPR 2025 | UMGen:多模態駕駛場景生成統一框架
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于多模態語義SLAM框架
松靈新品丨全球首款多模態?ROS開發平臺LIMO來了,將聯合古月居打造精品課程 精選資料分享
多文化場景下的多模態情感識別
多模態生物特征識別系統框架
一種無監督下利用多模態文檔結構信息幫助圖片-句子匹配的采樣方法
任意文本、視覺、音頻混合生成,多模態有了強大的基礎引擎CoDi-2

大模型+多模態的3種實現方法

人工智能領域多模態的概念和應用場景
什么是多模態?多模態的難題是什么?

字節跳動發布OmniHuman 多模態框架
端到端自動駕駛多模態軌跡生成方法GoalFlow解析





 工商網監
工商網監
評論