

AI工作負載正顯著推動接口IP市場的創新。AI模型參數量呈指數級增長,大約每4至6個月翻一番,這與摩爾定律所描繪的硬件發展速度(周期長達18個月)形成了鮮明對比。此差距要求硬件創新來支持人工智能(AI)工作負載,并且需要更強的計算能力、更豐富的資源和更高帶寬的互連技術。
更重要的是,硬件性能已經超越了標準掩膜尺寸的限制。由于計算單元和相關內存越來越多,CPU和GPU設計正在不斷突破掩膜尺寸。AI加速器和GPU現在需要一種全新的超高效網絡基礎設施,突破單個芯片的性能限制,同時實現低延遲、高密度連接的芯片間通信,優化能效。
本文從技術角度深入探討了橫向、縱向擴展為何成為HPC和AI芯片開發商的關鍵需求,以及超以太網和UALink等新標準如何應對高帶寬、低延遲連接和高效資源管理的挑戰。
新標準的崛起
在AI工作負載需求的推動下,芯片到芯片架構的橫向、縱向擴展至關重要。從單芯片過渡到Multi-Die系統,并融合HBM和UCIe等并行接口已成為必然趨勢。這些解決方案支持同構和異構計算架構,借助PCIe和CXL的傳統連接進一步擴展內存,并利用以太網實現更廣泛的網絡架構。
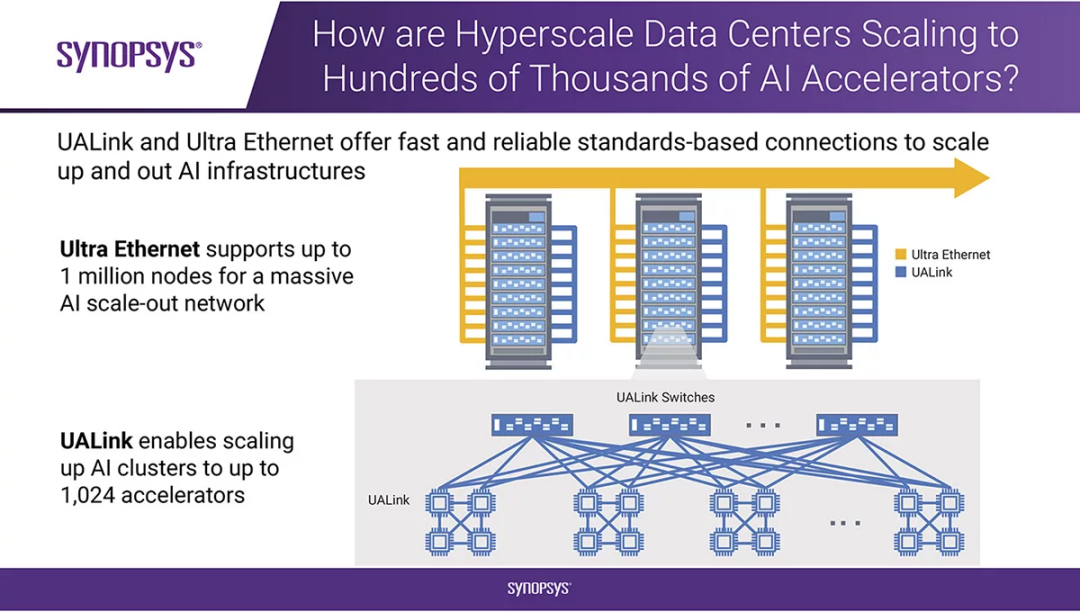
▲點擊查看詳細信息
為了滿足AI擴展需求,兩項新標準應運而生:
適用于橫向擴展的超以太網
適用于縱向擴展的UALink
超以太網是一種開放、可互操作的高性能架構,專為AI而設計,得到了交換機、網絡、半導體和系統供應等領域的知名企業以及超大規模用戶的支持。另一方面,UALink則通過特定的內存共享功能,使加速器能夠直接運行,得到了半導體行業重要參與者的廣泛認可。
超以太網:橫向擴展AI工作負載
隨著AI和HPC流量的增長,使用RoCE或專有解決方案的傳統網絡逐漸顯露出其局限性。這包括嚴格的按序數據包傳送、基于流的低效負載平衡,以及數據包丟失時在RDMA操作中繁瑣的重新傳輸。而這些對于AI操作來說成本非常高昂。超以太網聯盟(UEC)技術通過提供更高效、可擴展且強大的網絡解決方案來解決這些問題,能夠針對性地滿足AI和HPC工作負載的高性能需求。
超以太網的工作原理
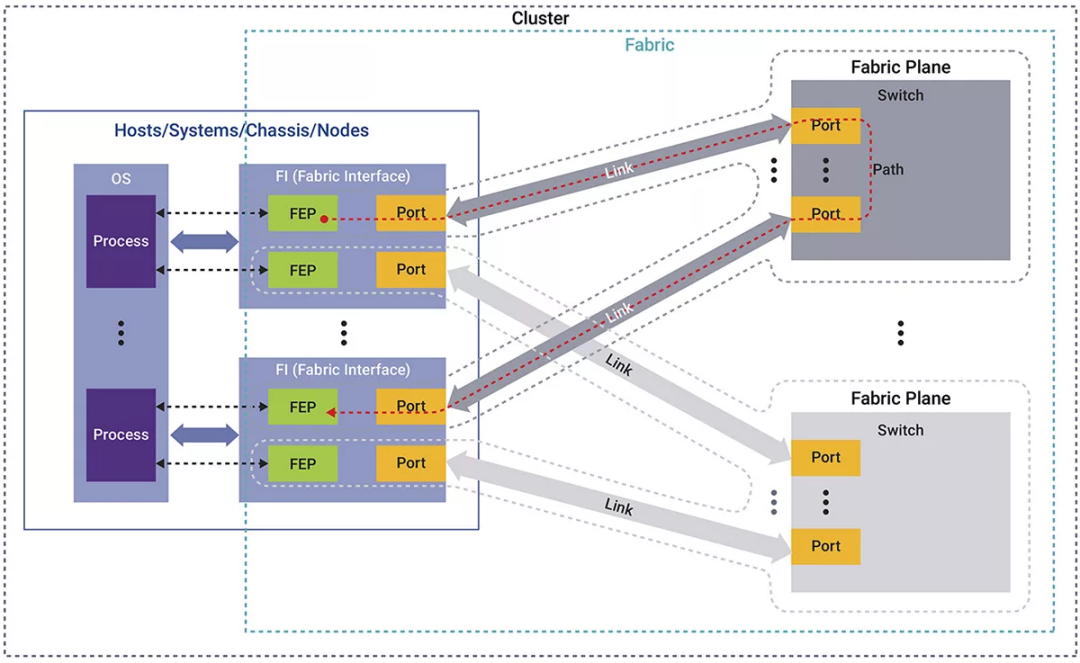
▲點擊查看詳細信息
圖1:超以太網集群圖
超以太網系統由多個集群組成,每個集群都包含節點和基礎設施。節點通過結構接口(網卡)連接到網絡,該接口可以承載多個邏輯結構端點(FEP)。網絡分為多個平面,每個平面包含多個通過交換機互連的FEP。
集群主要采用兩種模式來處理不同的任務。
并行作業模式:系統運行任務直至完成,并允許多個節點同時進行通信。對于需要大量并行處理的高性能計算任務來說,這是理想的作業模式。
客戶端/服務器模式:系統專為存儲任務而設置。在這種情況下,服務器持續處理來自多個客戶端的請求,并在特定的節點對之間進行通信,非常適合用于可靠且一致的數據訪問和管理工作。
超以太網的關鍵技術特點
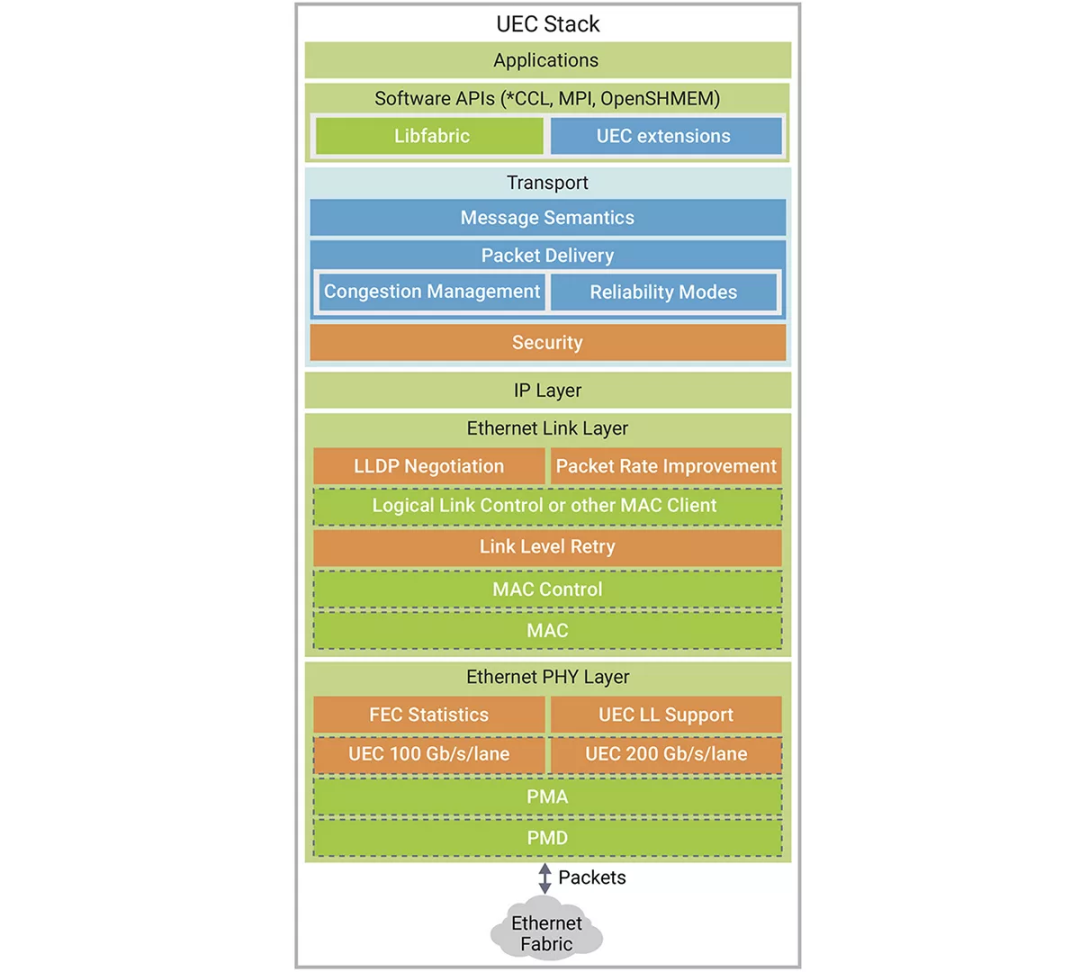
▲點擊查看詳細信息
圖2:超以太網使用專為AI和HPC應用而設計的下一代傳輸協議重新定義了以太網。(圖片來源:超以太網聯盟)
1. 物理層:與IEEE 802.3標準以太網兼容,具有基于FEC(前向糾錯)碼字的可選性能監控功能。UCR(不可糾正碼字率)和MTBPE(平均數據包錯誤間隔時間)等指標有助于深入分析傳輸性能以及可靠性表現。
2. 鏈路層:引入LLR(鏈路層重傳)協議,可實現無損傳輸,而無需依賴優先級流量控制(PFC)機制。這可確保更快的錯誤恢復,避免不必要的端到端重傳,并減少尾部延遲。
3. 數據包速率改進(PRI):通過壓縮以太網和IP報頭提高數據包速率,解決由傳統功能和冗余協議字段導致的效率低下問題。
4.鏈路協商協議:通過協商功能擴展LLDP,以檢測并啟用LLR和PRI等受支持功能。
5.傳輸層:旨在解決傳統RDMA網絡的局限性,支持選擇性重傳、無序傳送、數據包噴射和高級擁塞控制機制。提供多種傳輸模式,包括可靠有序交付(ROD)、可靠無序交付(RUD)和不可靠無序交付(UUD)。
6.擁塞控制:實現了incast管理、加速速率調整、基于遙測的控制和通過數據包噴射進行自適應路由等功能,以盡可能地減少尾部延遲并增強網絡性能。
7.安全:在傳輸層整合基于作業的安全性,利用IPSec和PSP功能進一步減少加密開銷并支持硬件卸載。
UALink:縱向擴展AI工作負載
AI模型的規模越來越大,相關市場對算力和內存資源的需求顯著增加。傳統的互連技術并非專為AI工作負載網絡設計,難以滿足其需求。UALink作為一種可擴展結構,可在數十到數百個專用AI加速器之間建立基于標準的超高帶寬連接網絡。這一技術的出現標志著市場的重大進步,縱向擴展網絡從臨時配置轉向更標準化的網絡,支持更高基數的系統,并配備專用的UALink交換機。
UALink的工作原理
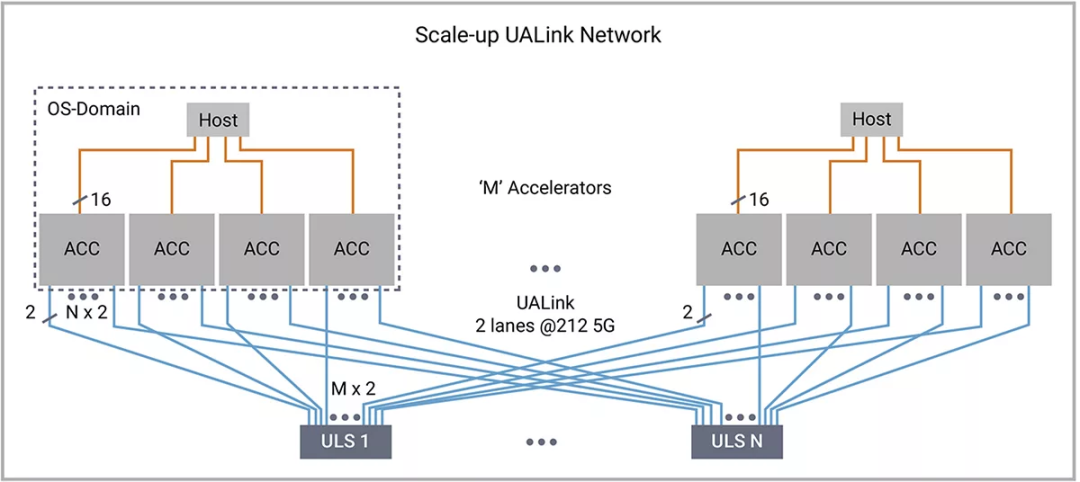
▲點擊查看詳細信息
圖3:UALink為縱向擴展網絡和AI加速器交換機營造了開放的生態系統。摘自:MICRO-2024 HiPChips研討會
UALink創建了一個高速、低延遲的網絡,可以連接一個Pod內的多個加速器(例如GPU)。這讓每個加速器能夠直接訪問其他加速器的內存,整個Pod可以像單個巨大的GPU一樣運行。這使得每個GPU可以直接訪問和修改同一擴展網絡內其他任何GPU的內存。從軟件角度來看,這組相互連接的GPU看起來就像一整個大型GPU。
UALink的工作原理超加速器鏈路(UALink)的關鍵技術特點
1.高帶寬:UALink每通道的速度高達200 Gbps,有助于在加速器之間高效傳輸數據。
2.輕量級協議:該協議設計輕量,可減少開銷并確保高效通信。
3.效率:亞微秒級延遲提高了推理性能,并支持在不劃分工作負載的情況下擴展到八個GPU以上。
4. 開放標準:UALink是一個開放的行業標準,可改善互操作性,減少供應商鎖定。
5. 內存共享:特定的內存共享功能讓加速器可以有效地訪問共享內存資源,支持數百個GPU之間的加載、存儲和原子操作,減少端到端延遲并降低功耗。
6.同步功能:UALink包含同步功能,有助于確保多個加速器之間的一致性,促進高效運行。
7. 與UEC相輔相成:可以與超以太網聯盟成員的前沿技術良好協作,實現更廣泛的可擴展性。
利用業界首發的超以太網和UALink IP解決方案實現大規模AI集群
新思科技搶先推出業內首款UALink和超以太網IP解決方案,致力于連接海量AI加速器集群。

▲點擊查看詳細信息
新思科技超以太網IP解決方案的速度高達1.6Tb/s,可支持多達一百萬個端點。此外,新思科技UALink IP每通道的速度高達200Gb/s,可連接一千多個加速器。這些解決方案針對AI的橫向、縱向擴展進行了優化,提供了AI通信所必需的高帶寬和輕量級協議。
結語
隨著AI領域的不斷擴大,采用標準化接口對于推動創新、降低復雜性和提高整體系統性能至關重要。AI基礎結構的未來在于這些能夠促進行業增長、提高效率的協作性開放標準解決方案。新思科技正處于AI和HPC設計創新的前沿,提供廣泛的高速接口IP組合。新思科技為PCIe 7.0、1.6T以太網、CXL、HBM、UCIe以及最新的超以太網和UALink提供完整且安全的IP解決方案,從而推動AI和HPC在性能、可擴展性、效率和互操作性等方面達到新的高度,幫助客戶實現一次性流片成功。
-
以太網
+關注
關注
40文章
5501瀏覽量
173488 -
交換機
+關注
關注
21文章
2683瀏覽量
100604 -
AI
+關注
關注
87文章
32823瀏覽量
272262 -
新思科技
+關注
關注
5文章
832瀏覽量
50650 -
HPC
+關注
關注
0文章
331瀏覽量
23990
原文標題:業內首款UALink和超以太網IP解決方案,重塑高性能AI網絡
文章出處:【微信號:Synopsys_CN,微信公眾號:新思科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
新思科技推出業界首款連接大規模AI加速器集群的超以太網和UALink IP 解決方案
設計坊第三期:靈活的工業以太網解決方案
自動化行業中的全廠自動化中的以太網/IP
基于以太網接口的TCP/IP 實驗
工業以太網方案選擇指南
Linux以太網解決方案的介紹
萬兆以太網和IP SAN的融合
新思科技收購MorethanIP,進一步擴展DesignWare以太網IP產品組合

新思科技推出業界首個1.6T高速以太網解決方案
數據中心市場的關鍵以太網解決方案





 工商網監
工商網監

評論