


使用機器學習的應用程序通常需要高計算能力。這些計算通常發生在顯卡的GPU上。Raspberry Pi并不專門設計用于運行計算密集型應用程序。但Google Coral USB加速器能在此提供幫助!借助此設備,我們可以在視頻中實現實時計算,如對象識別。
在本教程中,我們將探討如何在Raspberry Pi上集成和使用Google Coral。然后,我們將利用Raspberry Pi攝像頭中的視頻流創建實時對象檢測。
所需硬件部件
我在本教程中使用了以下硬件部件。許多組件在之前的教程中已經使用過。
Raspberry Pi*
Edge TPU:Google Coral USB加速器
官方Raspberry Pi攝像頭模塊 或 USB網絡攝像頭
用于識別的簡單對象(辦公用品、水果等)
最佳選擇:一個為Raspberry Pi和USB加速器配備散熱器的外殼(也可3D打印)。
Google Coral USB加速器比Raspberry Pi4小,應通過USB 3.0端口連接。

Google Coral USB加速器用于什么?
Google Coral USB加速器包含一個專門為神經網絡計算而設計的處理器。這個處理器被稱為Edge-TPU(Tensor Processing Unit)。
以下視頻對神經網絡進行了很好的解釋,包括它們到底是什么,以及為什么你經常在閱讀機器學習相關內容時會看到它們:
因此,主要任務之一是解決這些神經網絡(以矩陣的形式),而Edge TPU特別擅長于此。Google提供了特殊的庫,以便我們可以利用Coral USB加速器的特性。
在Raspberry Pi上安裝Google Coral Edge TPU
為了使用Coral Edge TPU的處理能力,我們需要安裝一些軟件包。為此,我們主要遵循TPU網站的步驟。使用 USB 加速器入門:https://coral.ai/docs/accelerator/get-started/使用 SSH 和 Putty 遠程訪問樹莓派:https://tutorials-raspberrypi.com/raspberry-pi-remote-access-by-using-ssh-and-putty/打開終端(或通過SSH連接),然后輸入以下命令:
echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.listcurl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -sudo apt-get update
之后,我們可以安裝Edge TPU運行時:
sudo apt-get install libedgetpu1-std
注意:如果你想安裝一個“更快”的運行時(意味著:頻率更高),請使用以下命令:sudo apt-get install libedgetpu1-max。但是,請記住,不能同時安裝這兩個版本。此外,高頻版本會使工作溫度升高,因此你應僅在具備足夠好的散熱條件時使用它。
安裝完成后,你可以將USB加速器連接到Raspberry Pi(最好連接到藍色的USB 3.0端口)。如果在安裝之前已經連接,請暫時斷開并重新連接。
現在,我們安裝Python軟件包。為此,以下命令已足夠:
sudo apt-get install python3-pycoral --yes
安裝TensorFlow Lite
我們還需要TensorFlow Lite。首先,我們檢查版本:
我的結果如下:
Name: tflite-runtimeVersion: 2.5.0Summary: TensorFlow Lite is for mobile and embedded devices.Home-page: https://www.tensorflow.org/lite/Author: Google, LLCAuthor-email: packages@tensorflow.orgLicense: Apache 2.0Location: /usr/lib/python3/dist-packagesRequires:Required-by: pycoral
如果你尚未安裝TensorFlow,可以按以下方式操作,然后再次運行命令:
echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.listcurl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -sudo apt-get updatesudo apt-get install python3-tflite-runtime
使用Google Coral和Raspberry Pi攝像頭在視頻中進行對象識別
接下來,我們希望在視頻流中實時激活對象檢測。計算將在Edge TPU上運行。為了顯示圖像,我們有幾個選項。我們可以使用例如PyGame、PiCamera或OpenCV等軟件包。我更喜歡OpenCV,因為它允許我們使用計算機視覺領域的更多功能。
首先,我們通過CSI連接Raspberry Pi攝像頭,或通過USB連接網絡攝像頭。大多數網絡攝像頭會自動被檢測到
讓我們從一個示例項目開始。再次打開終端:
mkdir google-coral && cd google-coralgit clone https://github.com/google-coral/examples-camera --depth 1
下一步,我們加載預訓練模型。您也可以選擇使用自己訓練的模型。然而,在我們這個簡單的例子中,我們只加載了MobileNet SSD300模型:,它已經可以識別許多物體。
MobileNet SSD300模型:https://resources.wolframcloud.com/NeuralNetRepository/resources/SSD-MobileNet-V2-Trained-on-MS-COCO-Data
cd examples-camerash download_models.sh
這個過程需要幾分鐘。之后,我們切換到OpenCV文件夾并安裝依賴項(如果你想使用另一個示例,這里有這個選項)。
cd opencvbash install_requirements.sh
現在我們可以啟動示例應用程序了。為此,你需要一個桌面環境。如果你不是直接在Raspberry Pi上工作,我建議使用遠程桌面連接。
如何建立 Raspberry Pi 遠程桌面連接:https://tutorials-raspberrypi.com/raspberry-pi-remote-desktop-connection/
python3 detect.py
這會打開一個新的窗口,顯示視頻流。在視頻流中,檢測到的物體會用矩形標記出來。你還可以看到計算出的物體被檢測到的概率(以百分比表示)(即根據算法,這個物體被識別為特定物體的可能性有多大)。
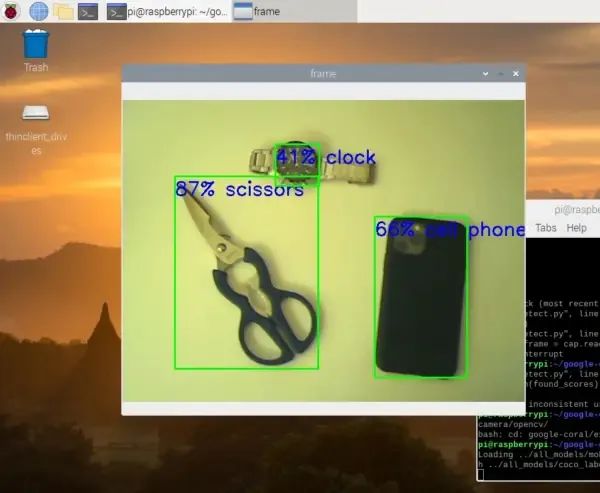
現在讓我們仔細查看代碼,以了解發生了什么:
# Copyright 2019 Google LLC## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at## https://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License. """A demo that runs object detection on camera frames using OpenCV. TEST_DATA=../all_models Run face detection model:python3 detect.py \ --model ${TEST_DATA}/mobilenet_ssd_v2_face_quant_postprocess_edgetpu.tflite Run coco model:python3 detect.py \ --model ${TEST_DATA}/mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite \ --labels ${TEST_DATA}/coco_labels.txt """import argparseimport cv2import os from pycoral.adapters.common import input_sizefrom pycoral.adapters.detect import get_objectsfrom pycoral.utils.dataset import read_label_filefrom pycoral.utils.edgetpu import make_interpreterfrom pycoral.utils.edgetpu import run_inference def main(): default_model_dir = '../all_models' default_model = 'mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite' default_labels = 'coco_labels.txt' parser = argparse.ArgumentParser() parser.add_argument('--model', help='.tflite model path', default=os.path.join(default_model_dir,default_model)) parser.add_argument('--labels', help='label file path', default=os.path.join(default_model_dir, default_labels)) parser.add_argument('--top_k', type=int, default=3, help='number of categories with highest score to display') parser.add_argument('--camera_idx', type=int, help='Index of which video source to use. ', default = 0) parser.add_argument('--threshold', type=float, default=0.1, help='classifier score threshold') args = parser.parse_args() print('Loading {} with {} labels.'.format(args.model, args.labels)) interpreter = make_interpreter(args.model) interpreter.allocate_tensors() labels = read_label_file(args.labels) inference_size = input_size(interpreter) cap = cv2.VideoCapture(args.camera_idx) while cap.isOpened(): ret, frame = cap.read() if not ret: break cv2_im = frame cv2_im_rgb = cv2.cvtColor(cv2_im, cv2.COLOR_BGR2RGB) cv2_im_rgb = cv2.resize(cv2_im_rgb, inference_size) run_inference(interpreter, cv2_im_rgb.tobytes()) objs = get_objects(interpreter, args.threshold)[:args.top_k] cv2_im = append_objs_to_img(cv2_im, inference_size, objs, labels) cv2.imshow('frame', cv2_im) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows() def append_objs_to_img(cv2_im, inference_size, objs, labels): height, width, channels = cv2_im.shape scale_x, scale_y = width / inference_size[0], height / inference_size[1] for obj in objs: bbox = obj.bbox.scale(scale_x, scale_y) x0, y0 = int(bbox.xmin), int(bbox.ymin) x1, y1 = int(bbox.xmax), int(bbox.ymax) percent = int(100 * obj.score) label = '{}% {}'.format(percent, labels.get(obj.id, obj.id)) cv2_im = cv2.rectangle(cv2_im, (x0, y0), (x1, y1), (0, 255, 0), 2) cv2_im = cv2.putText(cv2_im, label, (x0, y0+30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 2) return cv2_im if __name__ == '__main__': main()
- 首先,包含了所需的PyCoral庫。
- 在主函數中,定義了可以從命令行傳遞的參數(如指定模型等)。
- 加載模型及其標簽,并根據模型確定尺寸(此處為300×300)。
- 然后打開視頻流(cap = cv2.VideoCapture(args.camera_idx))。
接下來是核心部分:
objs = get_objects(interpreter, args.threshold)[:args.top_k]
- 此過程中會確定“分類分數”最高的3個元素(且分數需高于閾值)。
- 隨后,在圖像上標記每個檢測到的物體。
響應特定對象
如果我們想在檢測到某個特定對象(例如一個人)時立即觸發一個動作,現在應該怎么做呢?
為此,我們首先來看一下get_objects函數的返回值:
[Object(id=16, score=0.5, bbox=BBox(xmin=-2, ymin=102, xmax=158, ymax=296)), Object(id=0, score=0.16015625, bbox=BBox(xmin=6, ymin=114, xmax=270, ymax=300)), Object(id=61, score=0.12109375, bbox=BBox(xmin=245, ymin=166, xmax=301, ymax=302))]
我們看到,每個檢測到的對象都包含一個ID、一個分數以及一個帶有坐標的邊界框。為了確定檢測到了哪個對象,我們需要查看標簽:
{0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 12: 'stop sign', 13: 'parking meter', 14: 'bench', 15: 'bird', 16: 'cat', 17: 'dog', 18: 'horse', 19: 'sheep', 20: 'cow', 21: 'elephant', 22: 'bear', 23: 'zebra',24: 'giraffe', 26: 'backpack', 27: 'umbrella', 30: 'handbag', 31: 'tie', 32: 'suitcase', 33: 'frisbee', 34: 'skis', 35: 'snowboard', 36: 'sports ball', 37: 'kite', 38: 'baseball bat', 39: 'baseball glove', 40: 'skateboard', 41: 'surfboard', 42: 'tennis racket', 43: 'bottle', 45: 'wine glass', 46: 'cup', 47: 'fork', 48: 'knife', 49: 'spoon', 50: 'bowl', 51: 'banana', 52: 'apple', 53: 'sandwich', 54: 'orange', 55: 'broccoli', 56: 'carrot', 57: 'hot dog', 58: 'pizza', 59: 'donut', 60: 'cake', 61: 'chair', 62: 'couch', 63: 'potted plant',64: 'bed', 66: 'dining table', 69: 'toilet', 71: 'tv', 72: 'laptop', 73: 'mouse', 74: 'remote', 75: 'keyboard', 76: 'cell phone', 77: 'microwave', 78: 'oven', 79: 'toaster', 80: 'sink', 81: 'refrigerator', 83: 'book', 84: 'clock', 85: 'vase', 86: 'scissors', 87: 'teddy bear', 88: 'hair drier', 89: 'toothbrush'}
在我的案例中,識別到的對象有貓(ID=16)、人(ID=0)和椅子(ID=61)。
如果你想知道這些標簽是從哪里來的:它們是在模型中訓練的,因此被包含在內。如果你創建自己的模型,也可以只包含對你而言重要的一個或幾個對象。例如,識別你自己的臉也是可能的。在上面的例子中,我們想在檢測到某個特定對象(例如ID=5的公交車)時立即觸發一個動作。為此,我們首先查找該對象的ID。接下來,我們需要檢查是否找到了具有該ID的對象。我們還可以為分數添加一個閾值(例如0.8)。偽代碼看起來像這樣:
found_scores = [o.score for o in objs if o.id == 5]if len(found_scores) > 0 and max(found_scores) >= 0.8:# do something
正如你所見,對其做出反應非常簡單。之后,我們可以保存照片。
結論
對于那些覺得Raspberry Pi的計算能力不夠的人來說,Google的Edge TPU提供了一個很好的機會。與高端顯卡相比,USB加速器也非常便宜。高端顯卡的平均價格超過一千美元。
以300x300px的分辨率運行對象檢測非常流暢。也可以使用更高的分辨率,但你必須注意設備的溫度。我建議為連續運行增加一個額外的風扇。
此外,Google還提供了其他包含學習內容的存儲庫。對于Coral的其他用例,這個存儲庫仍然很有趣,并且除了其他內容外,還配備了圖像識別的示例。
https://github.com/google-coral/pycoral順便說一下,我們也可以使用TensorFlow創建自己的對象識別模型。為此,我們首先需要標注圖像,然后訓練一個模型。如果你感興趣,未來將提供相關的教程。
-
AI
+關注
關注
87文章
32937瀏覽量
272580 -
TPU
+關注
關注
0文章
146瀏覽量
20924 -
樹莓派
+關注
關注
118文章
1881瀏覽量
106243
發布評論請先 登錄
相關推薦
從CPU、GPU再到TPU,Google的AI芯片是如何一步步進化過來的?
阿里云MaxCompute,用計算力讓數據發聲
好奇~!谷歌的 Edge TPU 專用 ASIC 旨在將機器學習推理能力引入邊緣設備
CORAL-EDGE-TPU:珊瑚開發板TPU
BHR-AI-HX-M1產品概述
2018中國AI計算力報告發布
炸裂!小小樹莓派要搭上 Google 的人工智能了
Python的PyCoral迎來多項更新,為邊緣AI注入更多精彩

什么叫AI計算?AI計算力是什么?
樹莓派攜手Hailo為其新品注入人工智能功能
讓性能飆升!使用Python并行計算榨干樹莓派算力!






 工商網監
工商網監

評論