

近年來,人工智能技術迅速發展,大規模深度學習模型(即大模型)在自然語言處理、計算機視覺、語音識別以及自動駕駛等多個領域取得了突破性進展。自動駕駛作為未來智能交通的重要方向,其核心技術之一便是對海量、多模態傳感器數據的實時處理與決策。在這一過程中,大模型以其強大的特征提取、信息融合和預測能力為自動駕駛系統提供了有力支持。而在大模型的中,有一個“Token”的概念,有些人看到后或許會問:Token是個啥?對自動駕駛有何影響?
將Token輸入翻譯軟件,被解釋為“代幣”、“禮券”等,但在大模型領域中,Token則代表著數據經過預處理后劃分出的最小信息單位。無論是文本、圖像、視頻,還是激光雷達的點云數據,都可以通過Token化處理轉化為離散化的符號或向量表示。正是這種離散化和標準化的方式,使得大模型能夠高效地處理復雜、多模態的數據,捕捉其中蘊含的上下文關系和深層語義。
Token的基本概念與演變
Token作為一種數據表示單元,最早起源于自然語言處理(NLP)領域。傳統文本處理中,Token通常指將文本通過分詞或子詞拆分后得到的最小語義單位。如在英文處理過程中,一個單詞可以直接作為一個Token,而在中文處理中,由于語言特性,往往需要采用字符級或基于統計的分詞算法來生成Token。隨著深度學習技術的發展,出現了諸如BPE(Byte-Pair Encoding)、WordPiece和SentencePiece等先進的分詞方法,這些方法既能有效降低詞匯表大小,又能保證對罕見詞匯的較好表示。
隨著大模型的不斷擴展,Token這一概念也逐漸超越了文本領域。在圖像處理任務中,研究人員常將一幅圖像劃分為若干個固定大小的patch,每個patch都可視為一個Token;在視頻分析和激光雷達數據處理中,也可以通過對連續數據進行區域切分,將局部區域看作Token。這種思想使得不同模態的數據都能夠通過統一的離散化過程轉換為向量表示,為后續跨模態信息融合提供了理論基礎和實踐支持。
Token在大模型中的作用遠不止于數據的離散化,它更是一種衡量數據量、控制計算復雜度和管理內存消耗的重要手段。通過合理的Token化策略,模型不僅可以減少冗余信息,還能在保證關鍵信息表達的同時降低輸入序列的長度,從而大幅度提高訓練和推理效率。
Token化技術在大模型中的關鍵作用
Token化,亦或稱之為分詞(Tokenization)作為數據預處理的重要環節,其核心任務是將原始數據(無論是文本、圖像還是點云數據)轉換為離散的、易于處理的基本單元。大模型在接收這些離散化的Token后,通常會先通過嵌入層(Embedding Layer)將Token映射為高維向量,這一步驟對于捕捉數據內部的語義關系至關重要。
Token化有助于實現數據的離散化和標準化。自動駕駛系統中,不同傳感器采集的數據格式、分辨率和采樣頻率各不相同,如何將這些異構數據轉化為統一格式是一個巨大挑戰。Token化技術正是通過對數據進行切分、標準化處理,將圖像、點云等數據轉化為統一的Token序列,使得后續的模型可以在同一向量空間內進行操作。這樣不僅便于數據融合,還能減少各數據源之間的不匹配問題,提高整體處理效率。
嵌入層在大模型中也扮演著關鍵角色。每個Token經過嵌入層后,會被映射到一個高維向量空間中,向量之間的距離和角度可以反映出Token之間的語義相似度。傳統方法如Word2Vec、GloVe提供了靜態的詞向量表示,而更先進的動態嵌入方法(如BERT、GPT系列)則能夠根據上下文信息動態調整Token的向量表示。在自動駕駛領域,不同傳感器數據的Token經過嵌入后,能夠捕捉到更多細節信息,如圖像中物體的邊緣特征、點云中物體的立體結構等,為后續的目標檢測、語義分割以及軌跡預測提供了可靠基礎。
Token化技術在序列建模中也發揮著重要作用。大模型中的Transformer結構廣泛依賴自注意力機制(Self-Attention)來捕捉Token之間的遠距離依賴關系。通過位置編碼(Positional Encoding)和多頭注意力機制,模型可以充分挖掘序列中每個Token與其他Token之間的關系,生成全局性的信息表示。這在處理長文本、連續視頻幀以及動態點云數據時尤為重要,有助于自動駕駛系統在面對復雜交通場景時快速捕捉并理解環境變化。
Token在自動駕駛系統中的具體應用
自動駕駛系統的核心任務在于實時感知環境、快速決策與精準控制,而這一過程離不開對多模態數據的有效處理。隨著傳感器技術的不斷提升,自動駕駛車輛通常配備多個攝像頭、激光雷達、毫米波雷達和超聲波傳感器,各自采集的數據種類和格式存在巨大差異。Token化技術正好為這一多模態數據融合提供了統一的解決方案。
在感知模塊中,攝像頭捕捉的圖像和激光雷達獲取的點云數據均需要經過預處理,將連續數據離散化為Token。以圖像數據為例,傳統的目標檢測方法通常依賴于卷積神經網絡(CNN)對整幅圖像進行處理;而近年來基于Transformer的視覺模型,則將圖像劃分為固定大小的patch,每個patch即為一個Token。這樣不僅能充分保留圖像的局部細節,還能利用自注意力機制捕捉全局信息,從而提高目標檢測和語義分割的準確率。對于激光雷達點云數據,則可以依據空間分布將點云劃分為若干區域,每個區域對應一個Token,進而構建出三維環境模型,幫助系統準確識別路邊障礙物和行人位置。
在決策與規劃模塊中,自動駕駛車輛需要根據實時感知數據制定行駛策略和路徑規劃。這里,Token化技術同樣發揮著重要作用。通過對多傳感器數據進行Token化和嵌入,系統可以將各個傳感器捕捉到的信息在同一向量空間中進行融合,使得模型能夠同時參考圖像、點云以及其他傳感器數據的優勢,綜合判斷前方道路狀況和潛在風險。特別是在復雜路況或交叉路口場景中,不同傳感器數據之間存在大量冗余和噪聲,統一的Token化處理能夠幫助系統更高效地濾除無關信息,提取出對決策至關重要的特征,從而實現精準的實時決策。
自動駕駛系統要求極高的實時性。車輛在行駛過程中,必須在毫秒級別內完成大量數據的采集、處理和決策輸出。在這種情況下,Token化技術通過將輸入數據轉換為離散化的Token序列,有助于降低數據量、減少計算復雜度和內存消耗。如在處理長序列文本或高分辨率圖像時,合理的Token劃分策略可以有效減少Token數量,進而加速模型的推理速度,確保系統在關鍵時刻能夠快速響應,避免因計算延遲而引發安全隱患。
Token化技術還為自動駕駛系統的在線學習和增量更新提供了便利。由于道路環境和交通狀況不斷變化,車輛需要持續更新和優化感知模型。通過對新采集的數據進行Token化處理,系統可以迅速將新的信息融入現有模型,實現在線自適應更新和持續學習。這種基于Token的動態更新機制,使得自動駕駛系統能夠不斷提升環境適應能力和安全性,保證在各種復雜情況下都能保持高精度識別和決策。
Token技術面臨哪些挑戰?
Token化技術在大模型和自動駕駛系統中優勢非常明顯,但在實際應用過程中也面臨著一系列技術挑戰。如何在保證信息完整表達的前提下控制Token數量始終是一大難題。過細的Token劃分雖然可以保留更多細節信息,但也會顯著增加計算負擔和內存消耗;而過粗的Token劃分則可能導致關鍵信息丟失。為此,未來的研究需要在信息表達和計算效率之間找到最佳平衡點,開發更加自適應的Token化算法,依據具體場景動態調整Token的劃分策略。
跨模態數據的Token融合也存在技術瓶頸。自動駕駛系統中,不同傳感器的數據在采樣頻率、噪聲特性和分辨率上存在巨大差異,如何將這些異構數據經過Token化后實現有效對齊和融合,是當前亟待解決的問題。未來,可能需要結合注意力機制、圖神經網絡以及自監督學習等先進技術,進一步提高多模態數據的融合效果,確保各類Token在統一向量空間中的準確表達。
實時性和魯棒性一直是自動駕駛系統設計中的兩大關鍵指標。雖然Token化技術有助于降低模型運算量,但在極端復雜或高動態場景下,如何保證模型在毫秒級別內完成Token處理和信息融合,有人需要借助硬件加速和分布式計算技術。此外,如何增強大模型對突發狀況的預測能力、提升系統的容錯和自我修正能力,也是未來需要深入研究的方向。隨著計算資源的進一步提升和算法的不斷改進,基于Token的多模態數據處理技術有望在自動駕駛系統中發揮更大作用。在不久的將來,通過對Token化策略、嵌入層設計和跨模態融合技術的持續優化,自動駕駛系統將更加智能、精準和安全。
審核編輯 黃宇
-
自動駕駛
+關注
關注
788文章
14042瀏覽量
168163 -
大模型
+關注
關注
2文章
2847瀏覽量
3507
發布評論請先 登錄
相關推薦
為什么聊自動駕駛的越來越多,聊無人駕駛的越來越少?
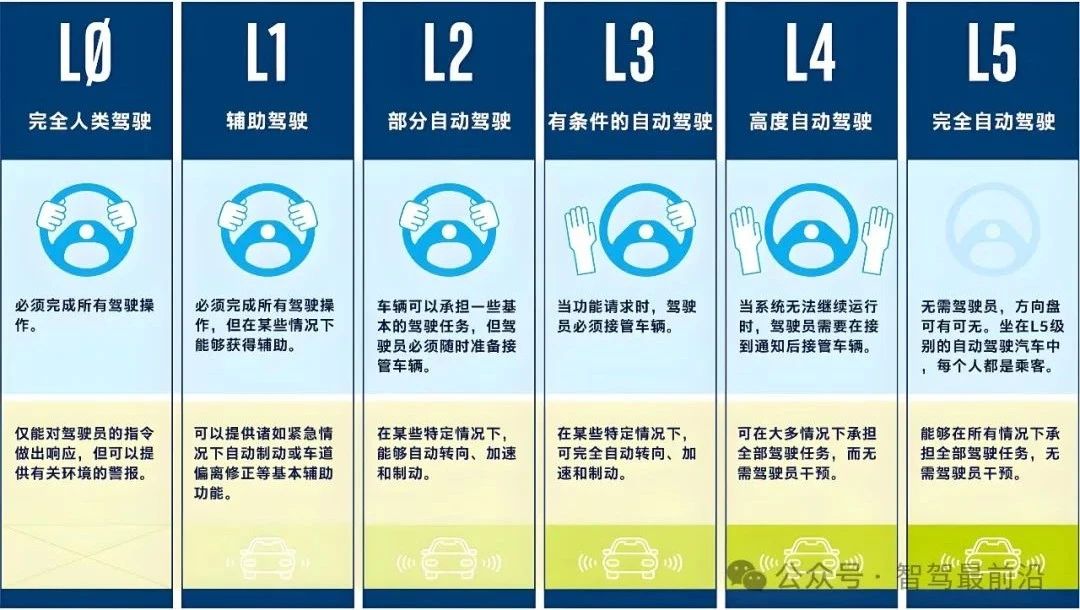
自動駕駛中常提的魯棒性是個啥?
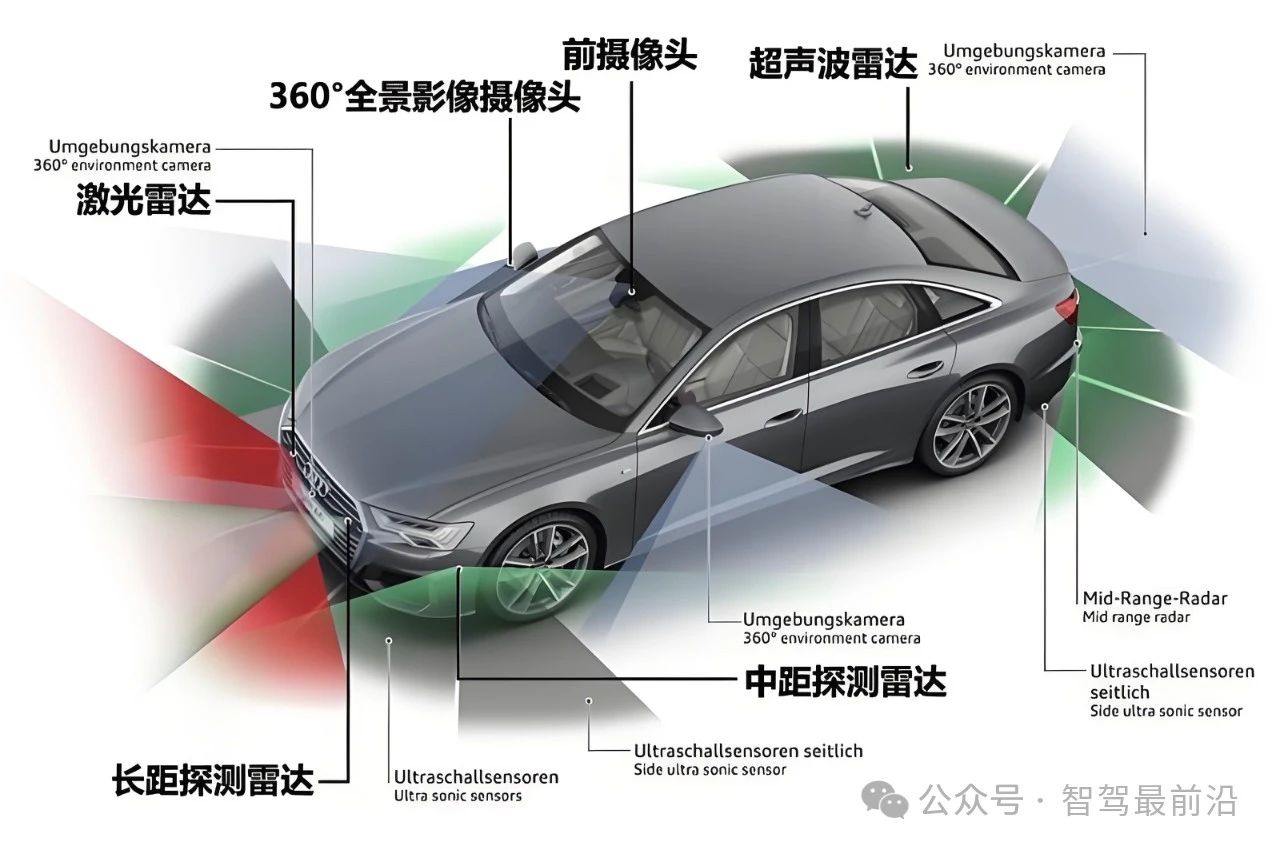
標貝科技:自動駕駛中的數據標注類別分享

標貝科技:自動駕駛中的數據標注類別分享

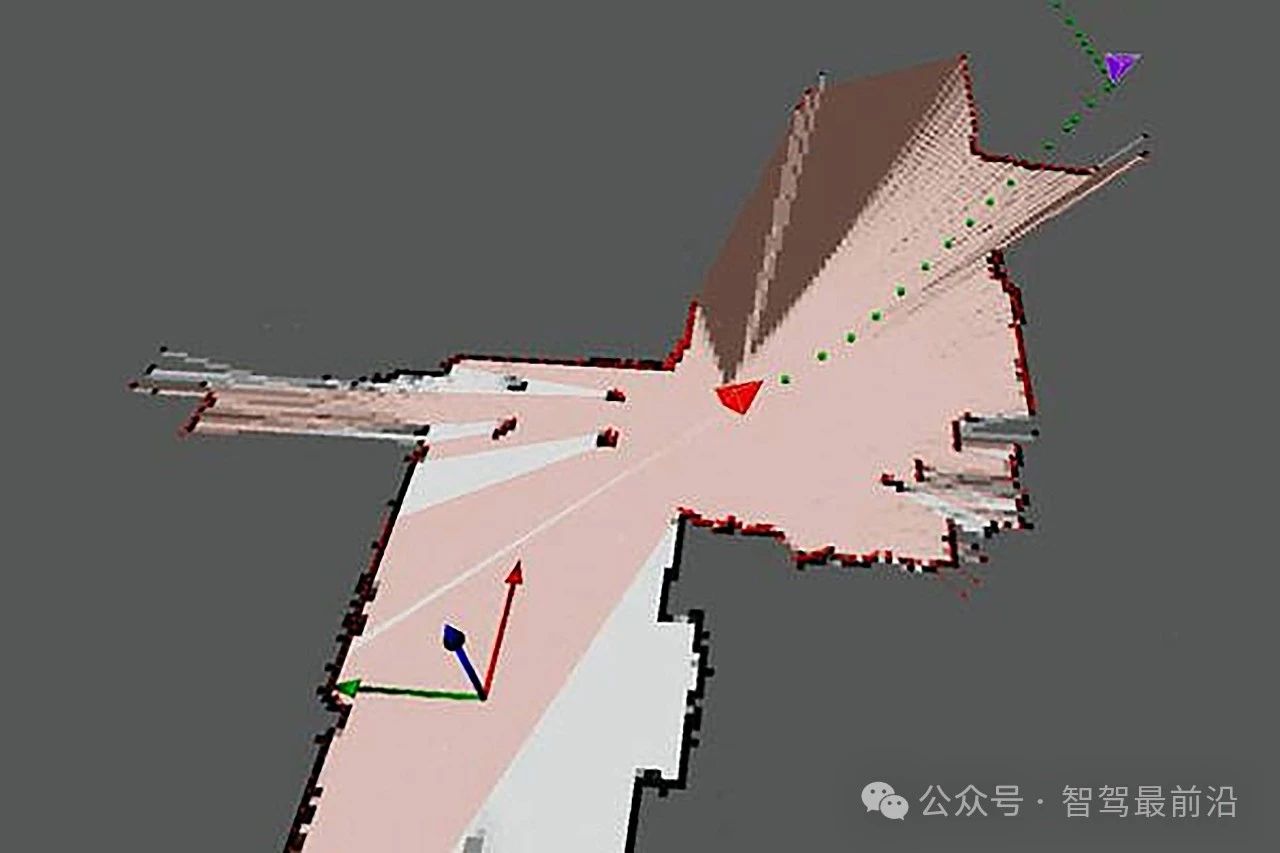
自動駕駛中常提的SLAM到底是個啥?
Apollo自動駕駛開放平臺10.0版即將全球發布
自動駕駛中一直說的BEV+Transformer到底是個啥?

自動駕駛汽車安全嗎?








 工商網監
工商網監

評論