


大腦的進化進程持續(xù)已久,從5億年前的蠕蟲大腦到現(xiàn)如今各種現(xiàn)代結(jié)構(gòu)。例如,人類的大腦可以完成各種各樣的活動,其中許多活動都是毫不費力的。例如,分辨一個視覺場景中是否包含動物或建筑物對我們來說是微不足道的。為了執(zhí)行這些活動,人工神經(jīng)網(wǎng)絡(luò)需要專家經(jīng)過多年的艱難研究仔細設(shè)計,并且通常需要處理一項特定任務(wù),例如查找照片中的內(nèi)容,稱為遺傳變異,或幫助診斷疾病。理想情況下,人們會希望有一個自動化的方法來為任何給定的任務(wù)生成正確的架構(gòu)。
如果神經(jīng)網(wǎng)要完成這項任務(wù),則需要專家經(jīng)過多年研究以后進行精心的設(shè)計,才能解決一項專門的任務(wù),比如發(fā)現(xiàn)照片中存在的物體,發(fā)現(xiàn)基因變異,或者幫助診斷疾病。理想情況下,人們希望有一個自動化的方法可以為任何給定的任務(wù)生成正確的網(wǎng)絡(luò)結(jié)構(gòu)。
生成這些網(wǎng)絡(luò)結(jié)構(gòu)的方法之一是通過使用演化算法。傳統(tǒng)的拓撲學研究已經(jīng)為這個任務(wù)奠定了基礎(chǔ),使我們現(xiàn)如今能夠大規(guī)模應(yīng)用這些算法,許多科研團隊正在研究這個課題,包括OpenAI、Uber實驗室、Sentient驗室和DeepMind。當然,谷歌大腦也一直在思考自動學習(AutoML)的工作。
除了基于學習的方法(例如強化學習)之外,我們想知道是否可以使用我們的計算資源以前所未有的規(guī)模進行圖像分類器的編程演化。我們能否以最少的專家參與達成解決方案,今天的人工進化神經(jīng)網(wǎng)絡(luò)能有多好的表現(xiàn)呢?我們通過兩篇論文來解決這些問題。
在ICML 2017上發(fā)表的“圖像分類器的大規(guī)模演化”中,我們用簡單的構(gòu)建模塊和初始條件建立了一個演化過程。這個想法簡單的說就是“從頭開始”,讓規(guī)模的演化做構(gòu)建工作。從非常簡單的網(wǎng)絡(luò)開始,該過程發(fā)現(xiàn)分類器與當時手動設(shè)計的模型相當。這是令人鼓舞的,因為許多應(yīng)用程序可能需要很少用戶參與。
例如,一些用戶可能需要更好的模型,但可能沒有時間成為機器學習專家。接下來要考慮的一個自然問題是手工設(shè)計和進化的組合是否可以比單獨的任何一種方法做得更好。因此,在我們最近的論文“圖像分類器體系結(jié)構(gòu)搜索的正則化演化”(2018年)中,我們通過提供復(fù)雜的構(gòu)建模塊和良好的初始條件(下面討論)參與了該過程。而且,我們使用Google的新TPUv2芯片擴大了計算范圍。對現(xiàn)代硬件、專家知識和進化的結(jié)合共同產(chǎn)生了CIFAR-10和ImageNet兩種流行的圖像分類基準的最新模型。
一個簡單的方法
以下是我們第一篇論文的一個實驗例子。
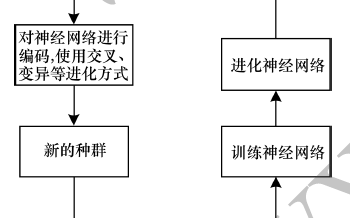
在下圖中,每個點都是在CIFAR-10數(shù)據(jù)集上訓練的神經(jīng)網(wǎng)絡(luò),通常用于訓練圖像分類器。每個點都是一個神經(jīng)網(wǎng)絡(luò),這個網(wǎng)絡(luò)在一個常用的圖像分類數(shù)據(jù)集(CIRAR-10)上進行了訓練。最初,人口由1000個相同的簡單種子模型組成(沒有隱藏層)。從簡單的種子模型開始非常重要,如果我們從初始條件包含專家知識的高質(zhì)量模型開始,那么最終獲得高質(zhì)量模型會更容易。一旦用簡單的模型開始,該過程就會逐步推進。在每一步中,隨機選擇一對神經(jīng)網(wǎng)絡(luò)。選擇更高精度的網(wǎng)絡(luò)作為父類,并通過復(fù)制和變異生成子節(jié)點,然后將其添加到群體中,而另一個神經(jīng)網(wǎng)絡(luò)會消失。所有其他網(wǎng)絡(luò)在此步驟中保持不變。隨著許多這樣的步驟陸續(xù)得到應(yīng)用,整個網(wǎng)絡(luò)就會像人類的進化一樣。
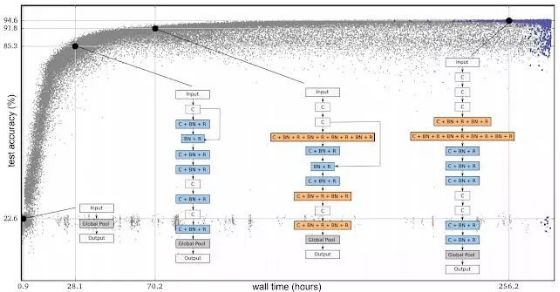
進化實驗進程。每個點代表 population 中的一個元素。這四個列表是發(fā)現(xiàn)架構(gòu)的示例,這些結(jié)構(gòu)對應(yīng)最好的個體(最右邊,根據(jù)驗證準確性篩選)和其三個 ancestor。
綜上所述,盡管我們通過簡單的初始架構(gòu)和直觀的突變來最小化處理研究人員的參與,但大量專家知識進入了構(gòu)建這些架構(gòu)的構(gòu)建塊之中。其中一些包括重要的發(fā)明,如卷積、ReLUs和批處理的歸一化層。我們正在發(fā)展一個由這些組件構(gòu)成的體系結(jié)構(gòu)。 “體系結(jié)構(gòu)”這個術(shù)語并不是偶然的:這與構(gòu)建高質(zhì)量的磚房相似。
結(jié)合進化和手工設(shè)計
在我們的第一篇論文后,我們希望通過給算法提供更少的選擇來減少搜索空間,使其更易于管理。使用我們的架構(gòu)推導(dǎo),我們從搜索空間去掉了制作大規(guī)模錯誤的所有可能的方法,例如蓋房子,我們把墻放在屋頂上的可能性去除了。與神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索類似,通過修復(fù)網(wǎng)絡(luò)的大規(guī)模結(jié)構(gòu),我們可以幫助算法解決問題。那么如何做到這一點? Zoph等人引入了用于架構(gòu)搜索的初始模塊。已經(jīng)證明非常強大。他們的想法是有一堆稱為細胞的重復(fù)單元。堆棧是固定的,但各個模塊的體系架構(gòu)是可以改變的。
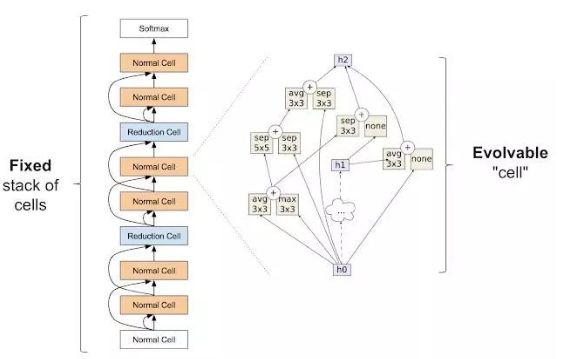
Zophet al. 中引入的構(gòu)建模塊。圖左表示整個神經(jīng)網(wǎng)絡(luò)對外部結(jié)構(gòu),其通過重復(fù)的單元從下到上解析輸入數(shù)據(jù)。右圖單元格的內(nèi)部結(jié)構(gòu)。該實驗的目的是發(fā)現(xiàn)能批生成高精度網(wǎng)絡(luò)的單元
在我們的第二篇論文“圖像分類器體系結(jié)構(gòu)搜索的正則化演化”(2018)中,我們介紹了將演化算法應(yīng)用于上述搜索空間的結(jié)果。突變通過隨機重新連接輸入(圖中右側(cè)箭頭)或隨機替換操作來修改單元格(例如,它們可以替換圖中的“最大3x3”像素塊)。這些突變相對簡單,但最初的條件并不相同:現(xiàn)在的整體已經(jīng)可以用模型進行初始化,這些模型必須符合由專家設(shè)計的細胞結(jié)構(gòu)。
盡管這些種子模型中的單元是隨機的,但我們不再從簡單模型開始,這使得最終獲得高質(zhì)量模型變得更容易。如果演化算法的貢獻有意義,那么,最終的網(wǎng)絡(luò)應(yīng)該比我們已經(jīng)知道可以在這個搜索空間內(nèi)構(gòu)建的網(wǎng)絡(luò)好得多。我們的論文表明,演化確實可以找到與手工設(shè)計相匹配或超越手藝設(shè)計的最先進模型。
控制變量比較法
即使突變/選擇進化過程并不復(fù)雜,也許更直接的方法(如隨機搜索)也可以做到這一點。其他選擇雖然不簡單,但也存在于文獻中(如強化學習)。正因為如此,我們的第二篇論文的主要目的是提供技術(shù)之間的控制變量比較。
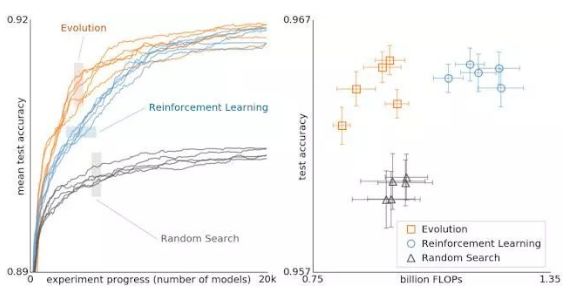
使用演化法、強化學習和隨機搜索法進行架構(gòu)搜索結(jié)果對比。這些實驗在 CIFAR-10 數(shù)據(jù)集上完成,條件與 Zophet al. 相同,他們使用強化學習進行空間搜索。
上圖比較了進化、強化學習和隨機搜索。在左邊,每條曲線代表一個實驗的進展,表明在搜索的早期階段進化比強化學習更快。這很重要,因為計算能力較低,實驗可能不得不提前停止。
此外,演變對數(shù)據(jù)集或搜索空間的變化具有魯棒性。總的來說,這種對照比較的目標是為研究界提供計算昂貴的實驗結(jié)果。在這樣做的過程中,我們希望通過提供不同搜索算法之間關(guān)系的案例研究來促進每個人的架構(gòu)搜索。例如,上圖顯示,使用更少的浮點運算時,通過進化獲取的最終模型可以達到非常高的精度。
我們在第二篇論文中使用的進化算法的一個重要特征是正則化的形式:不是讓最壞的神經(jīng)網(wǎng)絡(luò)死掉,而是刪除最老的一個,無論它們有多好。這改善了正在優(yōu)化的任務(wù)變化的魯棒性,并最終趨于產(chǎn)生更準確的網(wǎng)絡(luò)。其中一個原因可能是因為我們不允許權(quán)重繼承,所有的網(wǎng)絡(luò)都必須從頭開始訓練。因此,這種正則化形式選擇在重新訓練時仍然保持良好的網(wǎng)絡(luò)。換句話說,因為一個模型可能會更準確一些,訓練過程中的噪聲意味著即使是相同的體系結(jié)構(gòu)也可能會得到不同的準確度值。只有在幾代中保持準確的體系結(jié)構(gòu)才能長期存活,從而選擇重新訓練良好的網(wǎng)絡(luò)。篇猜想的更多細節(jié)可以在論文中找到。
我們發(fā)展的最先進的模型被命名為AmoebaNets,是我們AutoML努力的最新成果之一。所有這些實驗通過使用幾百個的GPU/TPU進行了大量的計算。就像一臺現(xiàn)代計算機可以勝過數(shù)千年前的機器一樣,我們希望將來這些實驗?zāi)艹蔀榧矣谩_@里我們旨在提供對未來的一愿。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103457 -
機器學習
+關(guān)注
關(guān)注
66文章
8501瀏覽量
134518
原文標題:谷歌大腦AutoML最新進展:用進化算法發(fā)現(xiàn)神經(jīng)網(wǎng)絡(luò)架構(gòu)
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
神經(jīng)網(wǎng)絡(luò)教程(李亞非)
【案例分享】基于BP算法的前饋神經(jīng)網(wǎng)絡(luò)
如何設(shè)計BP神經(jīng)網(wǎng)絡(luò)圖像壓縮算法?
基于差分進化的BP神經(jīng)網(wǎng)絡(luò)學習算法
神經(jīng)網(wǎng)絡(luò)進化能否改變機器學習
以進化算法為搜索策略實現(xiàn)神經(jīng)架構(gòu)搜索的方法
基于進化計算的神經(jīng)網(wǎng)絡(luò)設(shè)計與實現(xiàn)
基于改進郊狼優(yōu)化算法的淺層神經(jīng)網(wǎng)絡(luò)進化
基于進化卷積神經(jīng)網(wǎng)絡(luò)的屏蔽效能參數(shù)預(yù)測
卷積神經(jīng)網(wǎng)絡(luò)的介紹 什么是卷積神經(jīng)網(wǎng)絡(luò)算法
神經(jīng)網(wǎng)絡(luò)架構(gòu)有哪些
人工神經(jīng)網(wǎng)絡(luò)的原理和多種神經(jīng)網(wǎng)絡(luò)架構(gòu)方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論