 語音通信用哪些方法來提高語音質量
語音通信用哪些方法來提高語音質量
語音通信是實時通信,影響語音質量的因素很多,大致可把這些因素分成兩大類:一類是回聲噪聲等周圍環境因素導致語音質量差;另一類是丟包延時等網絡環境因素導致語音質量差。這兩類因素由于成因不一樣,解決方法也不一樣。下面就講講用哪些方法來提高語音質量。
首先看由于周圍環境因素導致語音質量差的解決方法。這類方法主要是用信號處理算法來提高音質,不同的因素有不同的處理算法,用回聲消除算法把回聲消除掉,用噪聲抑制算法把噪聲抑制住,用自動增益控制算法把音量調整到一個期望的值。這些都是信號處理領域比較專業的算法,好在現在webRTC已經開源,也包括這些算法(AEC/ANS/AGC)。我們只要把這些算法用好就有非常不錯的效果。這些算法的調試中AEC相對復雜一些,我在前面的文章中(音頻處理之回聲消除及調試經驗)專門寫過怎么調試,有興趣的可以去看一看。ANS/AGC相對簡單,先在Linux下做一個小應用程序驗證算法的效果,有可能要調一下參數,找一個相對效果較好的值。驗證算法的過程也是熟悉算法怎么使用的過程,對后面把算法應用到方案中是有好處的。
再來看由于網絡環境因素導致語音質量差的解決方法。網絡環境因素主要包括延時、亂序、丟包、抖動等,又有多種方法來提高音質,主要有抖動緩沖區(Jitter Buffer)、丟包補償(PLC)、前向糾錯(FEC)、重傳等,下面分別一一介紹。
1、Jitter Buffer
Jitter Buffer主要針對亂序、抖動因素,主要功能是把亂序的包排好序,同時把包緩存一些時間(幾十毫秒)來消除語音包間的抖動使播放的更平滑。我在前面的文章(音頻傳輸之Jitter Buffer設計與實現)中專門寫過Jitter Buffer 的設計和實現,有興趣的可以去看一看。
2、FEC
FEC主要針對丟包這種因素。FEC屬于信道編碼,想了解原理的朋友可以找相關文章看,這里就不講了。再說我講也講不好,我掌握信源編碼(語音編碼就是信源編碼的一種),對信道編碼只是了解。語音上利用FEC來做補償主要是在發端對發出的RTP包(幾個為一組,稱為原始包)FEC編碼生成冗余包發給收端,收端收到冗余包后結合FEC解碼得到原始的RTP包從而把丟掉的RTP包補上。至于生成幾個冗余包,這取決于收方反饋過來的丟包率。例如原始包5個為一組,丟包率為30%,經過FEC編碼后需要生成兩個冗余包,把這7個包都發給對方。對方收到原始包和冗余包的個數和只要達到5個就可以通過FEC完美復原出5個原始包,這5個原始包中丟掉的就通過這種方式補償出來了。原始RTP包有包頭和payload,冗余包中還要加上一個FEC頭(在RTP頭和payload中間),FEC頭結構如下:

其中Group first Sequence number是指這一組原始包中第一個的sequence number,original count是指一組原始包的個數,redundant count是指生成的冗余包的個數,Redundant index是指第幾個冗余包。冗余包有自己的payload type 和sequence number,要在SIP的SDP中告訴對方冗余包的payload type是多少,對方收到這個payload type的包后就做冗余包處理。
FEC不依賴與語音包內的payload,對于丟失的包能精確的復原出來。但是它也有缺點,一是它要累積到指定數量的包才能精確的復原,這就增加了時延;二是它要產生冗余包發送給對方,增加了流量。
3、PLC
PLC也主要針對丟包因素。它本質上是一種信號處理方法,利用前面收到的一個或者幾個包來近似的產生出當前丟的包。產生補償包的技術有很多種,比如基音波形復制(G711 Appendix A PLC用的就是這種技術)、波形相似疊加技術(WSOLA)、基音同步疊加(PSOLA)技術等,這些都很專業,有興趣可以找相關的文章看看。對codec而言,如果支持PLC功能,如G729,就不需要再在外部加PLC功能了,只需要對codec做相應的配置,讓它的PLC功能使能。如果不支持PLC功能,如G711,就需要在外部實現PLC。
PLC對小的丟包率(< 15%)有比較好的效果,大的丟包率效果就不好了,尤其是連續丟包,第一個丟的包補償效果還不錯,越到后面丟的包效果越差。
把Jitter Buffer、FEC、PLC結合起來就可以得到如下的接收側針對網絡環境因素的提高音質方案:
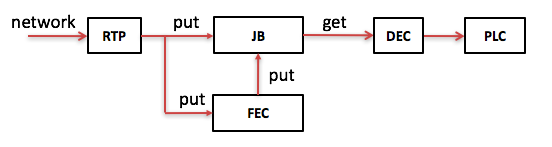
從網絡收到的RTP包如是原始包不僅要PUT進JB,還要PUT進FEC。如是冗余包則只PUT進FEC,在FEC中如果一組包中原始包的個數加上冗余包的個數達到指定值就開始做FEC解碼得到丟失的原始包,并把那些丟失的原始包PUT進JB。在需要的時候把語音幀從JB中GET出解碼并有可能做PLC。
4、重傳
重傳也主要針對丟包這種因素,把丟掉的包再重新傳給對方,一般都是采用按需重傳的方法。我在用重傳的方法時是這樣做的:接收方把收到的包排好序后放在buffer里,如果收到RTP包頭中的sequence number能被5整除(即模5),就統計一下這個包前面未被播放的包有哪些沒收到(即buffer里相應位置為空), 采用比特位的方式記錄下來(當前能被5整除的包的前一個包用比特位0表示,丟包置1,不丟包置0,比特位共16位(short型),所以做多可以看到前16個包是否有丟包),然后組成一個控制包(控制包的payload有兩方面信息:當前能被5整除的包的sequence number(short型)以及上面組成的16位的比特位)發給對方,讓對方重發這些包。接收方收到這個控制包后就能解析出哪些包丟了,然后重傳這些包。在控制包的payload里面也可以把每個丟了的包的sequence number發給對方,這里用比特位主要是減小payload大小,省流量。
在實際使用中重傳起的效果不大,主要是因為經常重傳包來的太遲,已經錯過了播放窗口而只能主動丟棄了。它是這些方法中效果最差的一個。
5、RFC2198
RFC2198是RTP Payload for Redundant Audio Data(用于冗余音頻數據的RTP負載格式),用了它后在當前RTP包中不僅可以承載當前語音的payload,還可以承載前幾個包的payload,承載以前包的個數越多,在高丟包率的情況下效果越好,但是延時也就越大,同時消耗的流量也就越多。相比于FEC,它消耗的流量更多,因為FEC用一組RTP包編碼生一個或多個成冗余包,而它一個RTP包就帶一個或多個以前包的payload。在有線網絡或者WIFI下可以用,在蜂窩網絡下建議慎用。
以上就是我用過的提高音質的方法。還有其他方法,我沒實踐過,就不寫了,寫出來也是紙上談兵。歡迎大家補充其他的方法。
-
語音通信
+關注
關注
0文章
50瀏覽量
18789 -
FEC
+關注
關注
0文章
40瀏覽量
13811
原文標題:語音通信中提高音質的幾個方法
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
PCM1681-Q1語音質量很差是什么原因導致的?
基于網絡性能的VoIP語音質量評價模型
可否使用labview和聲卡的結合來測試電話機的語音質量
如何實現低碼率語音編碼MELP聲碼器?
怎么實現基于無線傳感器網絡/ZigBee協議多跳語音通信結點的設計?
基于E-Model的VoIP語音質量研究
客觀語音質量評估算法
羅德與施瓦茨的ATC語音質量保證系統增強安全性、可靠性和效率
如何提升語音芯片的音質?






 工商網監
工商網監
評論