") MIT的研究人員研發(fā)了一種新型神經(jīng)網(wǎng)絡(luò),稱為Transparency by Design
MIT的研究人員研發(fā)了一種新型神經(jīng)網(wǎng)絡(luò),稱為Transparency by Design
編者按:論智曾系統(tǒng)地介紹過視覺問答技術(shù),而在本文中,MIT的研究人員研發(fā)了一種新型神經(jīng)網(wǎng)絡(luò),稱為Transparency by Design,既有出色的性能,還易于解釋。以下是論智對(duì)論文的大致編譯。
視覺問題回答(VQA)需要對(duì)圖像進(jìn)行高階推理,這是機(jī)器系統(tǒng)執(zhí)行復(fù)雜指令的基本能力。最近,模塊化網(wǎng)絡(luò)已被證明是執(zhí)行視覺推理任務(wù)的有效框架。雖然模塊化網(wǎng)絡(luò)最初設(shè)計(jì)時(shí)具備一定的模型透明度,但當(dāng)用于復(fù)雜的視覺推理任務(wù)時(shí),表現(xiàn)卻不那么完美。即使是目前最先進(jìn)的方法也沒有理解推理過程的有效機(jī)制。在本文,我們消除了可解釋模型和最先進(jìn)的視覺推理方法之間的性能差距,提出了一套視覺推理原型,它可以作為一個(gè)模型,以明確可解釋的方式執(zhí)行復(fù)雜的推理任務(wù)。而原型輸出的準(zhǔn)確性和可解釋性能讓人輕易地判斷模型的優(yōu)點(diǎn)和缺點(diǎn)。重要的是,我們證明原型的性能出色,在CLEVR數(shù)據(jù)集上的最高精確度達(dá)99.1%。另外,當(dāng)面對(duì)含有新數(shù)據(jù)的少量樣本時(shí),模型仍然能有效地學(xué)習(xí)。利用CoGenT泛化任務(wù),我們證明該模型比現(xiàn)有技術(shù)水平提高了20個(gè)百分點(diǎn)。
一個(gè)VQA模型必須具備推理圖片中復(fù)雜場(chǎng)景的能力,例如,要回答“大金屬球右邊的正方體是什么顏色?”這個(gè)問題,模型必須先判斷哪個(gè)球體是最大的,而且還是金屬的,然后理解“右邊”是什么意思,最后把這一概念應(yīng)用到圖片中。在這一新興領(lǐng)域中,模型必須找到正方體,然后辨別它的顏色。這種行為需要綜合能力才能應(yīng)對(duì)任意推理過程。
Transparency by Design
將一個(gè)復(fù)雜的推理過程分解成一連串小問題,每個(gè)問題都能被獨(dú)立解決再組合,這種推理方法非常強(qiáng)大且有效。這種類型的模塊化結(jié)構(gòu)同樣允許在推理的每個(gè)步驟對(duì)網(wǎng)絡(luò)輸出進(jìn)行檢查。受此啟發(fā),我們開發(fā)了一種神經(jīng)模塊網(wǎng)絡(luò),能夠在圖像空間中建立一個(gè)注意力機(jī)制模型,我們稱之為Transparency by Design network(TbD-net),重點(diǎn)突出透明度是此次設(shè)計(jì)的亮點(diǎn)。
下表是TbD-net中用到的模塊匯總。“Attention”和“Encoding”分別表示從上一模塊中輸出的單一維度和高維度。“Stem”表示訓(xùn)練過的神經(jīng)網(wǎng)絡(luò)生成的圖像特征。變量x和y表示場(chǎng)景中的目標(biāo)物體,[property]表示物體的顏色、形狀、大小或是材料的其中一個(gè)特點(diǎn)。
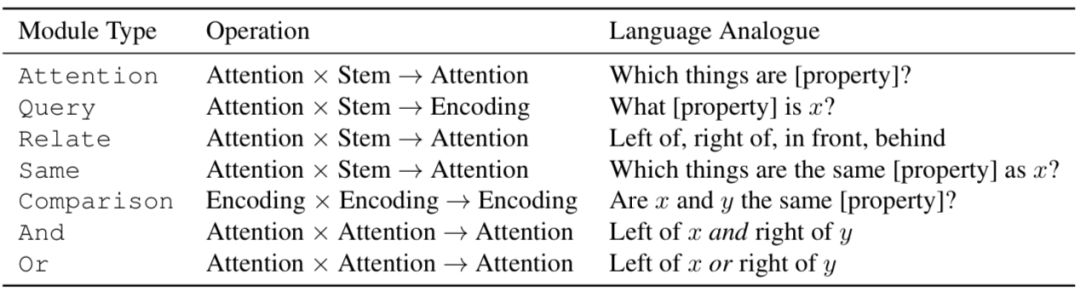
Attention模塊負(fù)責(zé)能體現(xiàn)目標(biāo)物體特征的圖像區(qū)域,例如如果圖像中有紅色目標(biāo),模塊就會(huì)被使用。在Attention模塊中輸入圖像特征,然后進(jìn)行微調(diào)。之后輸出一張關(guān)于維度的熱圖1×H×W。
And或Or邏輯模塊分別在交集和并集中組合兩個(gè)注意力掩碼,這些操作不需要學(xué)習(xí),因?yàn)樗鼈円呀?jīng)經(jīng)過微調(diào)并且可以用手工實(shí)現(xiàn)。
Relate模塊表示一個(gè)區(qū)域與另一個(gè)區(qū)域有某種空間關(guān)系;Same模塊負(fù)責(zé)從區(qū)域中提取某種相關(guān)特征,然后與圖像中的其他模塊分享這種特征。例如,當(dāng)回答“哪個(gè)物體的顏色和小正方體一樣?”這種問題時(shí),網(wǎng)絡(luò)需要利用Attention模塊鎖定小正方體,然后利用Same模塊判斷它的顏色,然后輸出一個(gè)注意力掩碼,定位出所有與其有相同特征的物體。
Query模塊需要從圖片中某個(gè)位置提取出特征。例如,這些模塊要判斷某個(gè)對(duì)象的顏色是什么。每個(gè)Query模塊就會(huì)輸入特征和注意力掩碼,然后產(chǎn)生帶有相關(guān)特點(diǎn)的特征映射。
Compare模塊可以比較兩個(gè)Query模塊輸出的屬性,并生成一個(gè)特征映射,該映射對(duì)特征是否相同進(jìn)行了編碼。
下圖是TbD網(wǎng)絡(luò)在解決復(fù)雜VQA問題時(shí),在推理過程中注意力變化的過程:
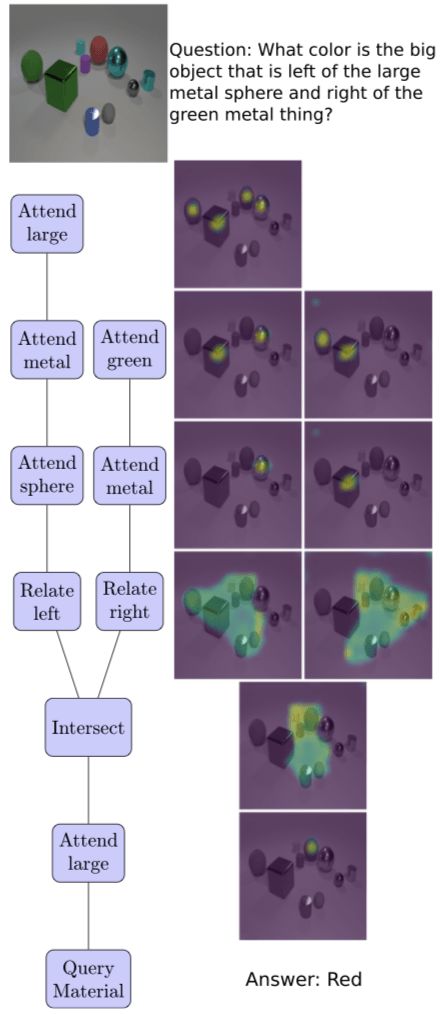
注意,模塊在使用注意力時(shí)并不用學(xué)習(xí),而是利用經(jīng)過它們的注意力,生成精確的注意力映射。所有的注意力掩碼都是由感官上一致的顏色映射生成的。
實(shí)驗(yàn)過程
為了評(píng)估模型性能,研究人員使用了兩個(gè)數(shù)據(jù)集:CLEVR和CLEVR-CoGenT。CLEVR是一個(gè)含有7萬張訓(xùn)練圖像和70萬個(gè)訓(xùn)練問題的VQA數(shù)據(jù)集,同時(shí)還有15000張圖像和150000個(gè)問題作為測(cè)試和對(duì)照集。
CLEVR
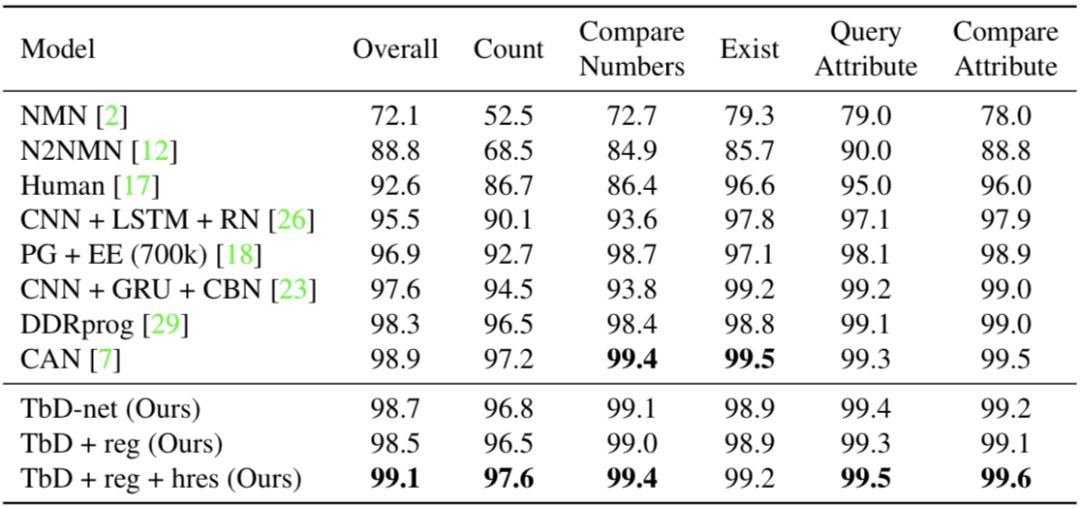
最初在CLEVR數(shù)據(jù)集上測(cè)試時(shí),模型的精確度為98.7%,遠(yuǎn)遠(yuǎn)優(yōu)于其他神經(jīng)模塊化網(wǎng)絡(luò)。在這之后研究人員檢查了模型產(chǎn)生的注意力掩碼,發(fā)現(xiàn)背景有噪音。雖然不影響模型的性能,但這些雜亂的區(qū)域可能會(huì)誤導(dǎo)用戶。于是,研究人員對(duì)其進(jìn)行了泛化處理,對(duì)比結(jié)果如下圖所示:

沒有經(jīng)過泛化,模塊在背景區(qū)域產(chǎn)生了少量的注意力,目標(biāo)物體處的注意力較多,而其他物體上的注意力為零。當(dāng)加上泛化后,背景中雜亂的注意力消失,注意力精準(zhǔn)地落在目標(biāo)物體上。
除此之外,最初的模型將14×14的特征映射作為每個(gè)模塊的輸入,但是這對(duì)于解決密集物體圖片卻很困難。于是將特征映射的分辨率調(diào)整為28×28之后,這個(gè)問題就解決了。如下圖所示:

當(dāng)要求觀察藍(lán)色橡膠物體后面和青色大圓柱前面的空間時(shí),左邊是輸入的圖像,中間是分辨率為14×14的映射,右邊是28×28的映射。
經(jīng)過上述兩方面的改進(jìn),模型在CLEVR上的性能由原先的98.7%升至99.1%,模型與其他方法的對(duì)比可以在下表中看到,其中TbD-net是最初的模型,“+reg”表示增加了泛化,“+reg+hres”表示在泛化的基礎(chǔ)上提高了特征映射的分辨率:
透明度
下面研究人員還對(duì)透明度就行了量化分析,接著還檢查了幾個(gè)模塊的輸出,證明了在沒有任何光滑處理的前提下,模型的每一步都可以直接解讀出來。
如果模塊能明顯的標(biāo)記出正確的目標(biāo)物體,那么他的注意力就是可解釋的。下圖展示了一個(gè)Attention模塊的輸出,它將注意力放在所有金屬物體上。

然而,在更復(fù)雜的操作中,例如Same和Relate模塊仍然能產(chǎn)生直接的注意力掩碼。在下圖中這些模塊仍然容易理解。
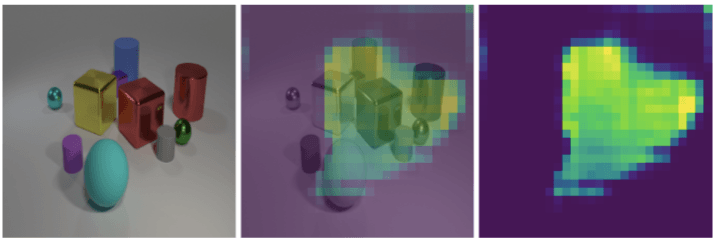
左圖是輸入的圖像,右圖是Relate模塊生成的注意力掩碼,它接收到要注意紫色的圓柱體。中間的圖表示注意力掩碼與輸入的圖相重疊。很明顯,注意力落在了紫色圓柱體右邊的所有區(qū)域。

左圖是輸入的圖像,右圖是Same模塊輸出的掩碼,它被要求注意藍(lán)色的球體。中間的圖表示輸入圖像與掩碼重疊。最終說明它成功地完成了任務(wù):首先確定球體的顏色,然后確定這一顏色的所有對(duì)象,最后找到有該顏色的目標(biāo)物體。
CLEVR-CoGenT
CLEVR-CoGenT對(duì)于泛化測(cè)試是一個(gè)好選擇,它在形式上與CLEVR相同,但只有兩個(gè)特殊條件。A,所有的立方體必須是灰色、藍(lán)色、棕色或黃色其中的一種,所有的圓柱體必須是紅色、綠色、紫色或青色的一種;B,顏色被互換。
結(jié)果表明,當(dāng)只用A情況的數(shù)據(jù)進(jìn)行訓(xùn)練時(shí),模型的性能在A下的表現(xiàn)優(yōu)于B。下圖說明了模型在兩種情況下的性能:
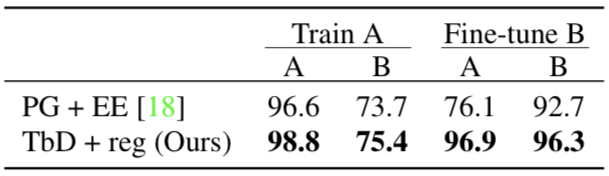
接著,研究人員用B中的數(shù)據(jù)對(duì)模型進(jìn)行微調(diào),模型的準(zhǔn)確率由75.4%升至96.3%。
結(jié)語
本文中,研究人員提出了Transparency by Design網(wǎng)絡(luò),這些網(wǎng)絡(luò)組成可視基元,利用外部注意力機(jī)制執(zhí)行復(fù)雜的推理操作。與此前的方法不同,由此產(chǎn)生的神經(jīng)模塊網(wǎng)絡(luò)既具有高性能,有方便解釋。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100719 -
MIT
+關(guān)注
關(guān)注
3文章
253瀏覽量
23389
原文標(biāo)題:MIT提出TbD網(wǎng)絡(luò),讓視覺問答模型更易于解釋同時(shí)保持高性能
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
隱藏技術(shù): 一種基于前沿神經(jīng)網(wǎng)絡(luò)理論的新型人工智能處理器
卷積神經(jīng)網(wǎng)絡(luò)模型發(fā)展及應(yīng)用
麻省理工研發(fā)新神經(jīng)網(wǎng)絡(luò)芯片,速度提升6倍,功耗減少94%!
日本東京大學(xué)的研究人員開發(fā)了一種稱為DRAGON(龍)的飛行機(jī)器人






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論