 深度學習初學者了解CNN卷積神經網絡的黃金指南
深度學習初學者了解CNN卷積神經網絡的黃金指南
卷積神經網絡。這聽起來像是一個奇怪的生物學和數學的結合,但是這些網絡已經成為計算機視覺領域最具影響力的創新之一。2012年是神奇網絡成長的第一年,Alex Krizhevsky用它們贏得了當年的ImageNet競賽(基本上是計算機視覺年度奧運會),把分類錯誤記錄從26%降到了15%,這個驚人的提高從那以后,許多公司一直在以服務為核心進行深度學習。Facebook使用自動標記算法的神經網絡,谷歌的照片搜索,亞馬遜的產品推薦,Pinterest的家庭飼料個性化和Instagram的搜索基礎設施。
然而,經典的,可以說是最流行的,這些網絡的用例是用于圖像處理。在圖像處理中,讓我們來看看如何使用這些CNN進行圖像分類。
問題空間
圖像分類是獲取輸入圖像和輸出類(貓,狗等)或類的概率最好描述圖像的任務。對于人類來說,承認這項任務是我們從出生那一刻起學到的第一個技能之一,并且是成年人自然而不費吹灰之力的人。即使沒有兩次思考,我們也能夠快速無縫地識別我們所處的環境以及周圍的物體。當我們看到一張圖像或者只是看著周圍的世界時,大部分時間我們都能夠立刻刻畫這個場景,給每個對象一個標簽,所有這些都沒有自覺地注意到。這些能夠快速識別模式的技能,從先前的知識概括,

投入和產出
當一臺電腦看到一個圖像(以圖像作為輸入)時,它會看到一個像素值的數組。根據圖像的分辨率和大小,它將看到一個32×32×3的數字數組(3指的是RGB值)。為了說明這一點,假設我們有一個JPG格式的彩色圖像,它的大小是480 x 480.代表性的數組將是480 x 480 x 3.這些數字中的每一個都有一個從0到255的值,它描述該點的像素強度。這些數字對于我們進行圖像分類時毫無意義,這是計算機唯一可用的輸入。這個想法是,你給計算機這個數組的數組,它會輸出的數字,描述了圖像是一個類的概率(.80為貓,.15為狗,0.05為鳥等)。
我們想要計算機做什么
現在我們知道這個問題以及輸入和輸出了,我們來思考如何解決這個問題。我們希望計算機做的是能夠區分所有的圖像,并找出使狗成為狗或使貓成為貓的獨特功能。這也是下意識地在我們的腦海中繼續的過程。當我們看一張狗的照片時,如果照片具有可識別的特征,例如爪子或四條腿,我們可以將其分類。以類似的方式,計算機能夠通過查找諸如邊緣和曲線等低級特征來執行圖像分類,然后通過一系列卷積層來構建更抽象的概念。這是一個CNN的一般概述。我們來詳細說明一下。
生物連接
但首先,有一點背景。當你第一次聽說卷積神經網絡這個術語的時候,你可能已經想到了一些與神經科學或生物學有關的東西,你會是對的。有點。CNNs確實從視覺皮層中獲得了生物啟發。視覺皮層具有對視野特定區域敏感的細胞區域。這個想法是由1962年在一個迷人的實驗由胡貝爾和威塞爾(在擴展視頻)在那里他們表明,大腦中的一些個體神經元細胞只有在某個方位的邊緣存在的情況下才會響應(或發射)。例如,一些神經元在暴露于垂直邊緣時發射,而另一些在顯示水平或對角邊緣時發射。Hubel和Wiesel發現,所有這些神經元都是以柱狀結構組織的,并且能夠產生視覺感知。在具有特定任務的系統內部(視覺皮層中尋找特定特征的神經元細胞)內部的專門組件的想法也是機器使用的,并且是CNN背后的基礎。
結構體
回到具體細節。有關CNN做的更詳細的概述是,您將圖像傳遞給一系列卷積,非線性,匯聚(下采樣)和完全連接的圖層,并獲得輸出。正如我們前面所說的那樣,輸出可以是一個類或者一個最能描述圖像的類的概率。現在,困難的部分是了解每個層次都做了什么。所以讓我們進入最重要的一個。
第一層 - 數學部分
CNN中的第一層始終是一個卷積層。首先要確保你記得這個轉換(我將使用這個縮寫很多)的輸入是什么。就像我們之前提到的那樣,輸入是一個32×32×3的像素值數組。現在,解釋一個conv層的最好方法就是想象一個閃爍在圖像左上角的手電筒。假設這個手電筒照射的光線覆蓋了5×5的區域。現在,讓我們想象這個手電筒滑過輸入圖像的所有區域。在機器學習方面,這種手電筒被稱為濾波器(有時也稱為神經元或內核),而它所照射的區域稱為接受場。現在這個過濾器也是一個數組數組(數字稱為權重或參數)。一個非常重要的注意事項是,這個過濾器的深度必須和輸入的深度相同(這可以確保數學運算出來),所以這個過濾器的尺寸是5 x 5 x 3。現在,我們來看看例如過濾器的第一個位置。這將是左上角。當濾波器在輸入圖像周圍滑動或卷積時,它將濾波器中的值與圖像的原始像素值相乘(也稱為計算元素智能乘法)。所有這些乘法都被總結出來(從數學上講,這將是總共75次乘法)。所以,現在你有一個單一的數字。記住,這個數字只是過濾器位于圖像左上角的代表。現在,我們對輸入音量上的每個位置重復這個過程。(下一步將過濾器向右移動1個單位,然后再向右移動1,依此類推)。輸入卷上的每個唯一位置都會生成一個數字。將過濾器滑過所有位置后,您將發現所剩下的是一個28 x 28 x 1的數字數組,我們稱之為激活圖或功能圖。你得到一個28×28陣列的原因是有一個5×5的濾波器可以放在一個32×32輸入圖像上的784個不同的位置。這784個數字被映射到一個28×28數組。
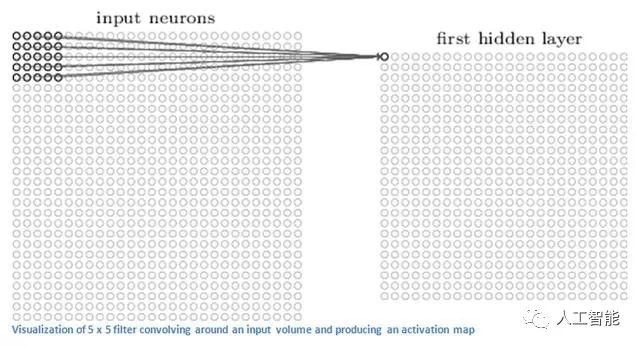
(快速注意:我使用的一些圖像,包括上面的圖像,來自Michael Nielsen的"Neural Networks and Deep Learning",強烈推薦)。
假設我們現在使用兩個5 x 5 x 3濾鏡而不是一個。那么我們的輸出量將是28 x 28 x 2.通過使用更多的過濾器,我們能夠更好地保留空間尺寸。在數學上,這是卷積層中發生的事情。
第一層 - 高層次的視角
但是,讓我們從高層次談論這個卷積實際上在做什么。每個這些過濾器都可以被認為是功能標識符。當我說功能時,我正在談論的是直線邊緣,簡單的顏色和曲線。想想所有圖像的共同點,最簡單的特點。假設我們的第一個過濾器是7 x 7 x 3并且將成為曲線檢測器。(在本節中,為了簡單起見,讓我們忽略過濾器深度為3單位的事實,并且只考慮過濾器和圖像的頂部深度切片)。作為曲線檢測器,過濾器將具有像素結構,沿曲線形狀的區域是更高的數值(請記住,我們正在討論的這些濾波器只是數字!)。
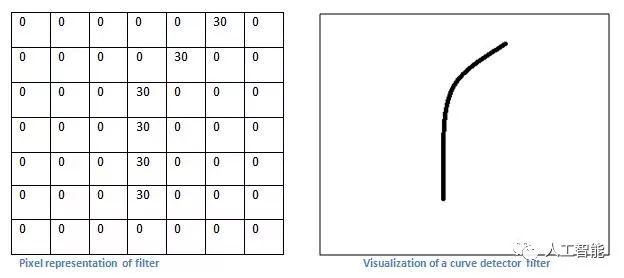
現在,讓我們回到數學上的可視化。當我們在輸入體積的左上角有這個濾波器時,它將計算該區域的濾波器和像素值之間的乘法。現在讓我們舉一個想要分類的圖像的例子,讓我們把我們的過濾器放在左上角。
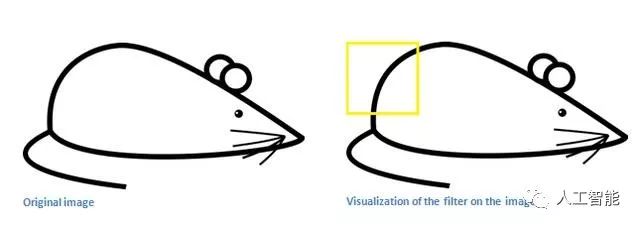
請記住,我們所要做的就是將濾鏡中的值與圖像的原始像素值相乘。
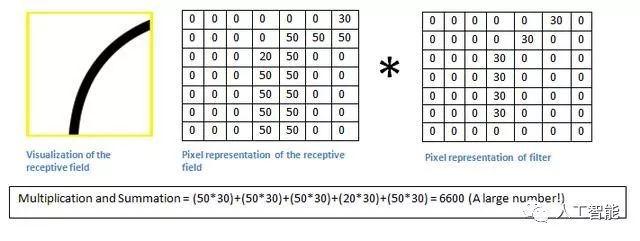
基本上,在輸入圖像中,如果有一個通常類似于這個濾波器所代表的曲線的形狀,那么所有相乘的相加將會產生一個大的值!現在讓我們看看當我們移動過濾器時會發生什么。
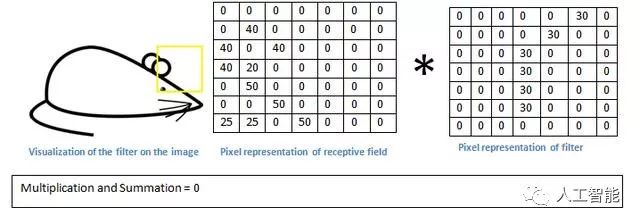
價值低得多!信息信息范范信息亦范范范范范辛辛區信息預范信息 記住,這個conv層的輸出是一個激活圖。因此,在單一濾波器卷積的簡單情況下(如果該濾波器是曲線檢測器),激活圖將顯示圖片中最有可能是曲線的區域。在這個例子中,我們的26 x 26 x 1激活圖的左上角(26是因為7x7濾鏡而不是5x5)將是6600.這個高值意味著在輸入中可能有某種曲線導致過濾器激活的音量。在我們的激活地圖右上角的值將是0,因為沒有任何東西在輸入音量導致過濾器激活(或者更簡單的說,在原始圖像的該區域中沒有曲線)。請記住,這只是一個過濾器。信息范范范讀范范范亦內范亦會信息及信息范信信息范辛辛 我們可以有其他的過濾器,用于向左彎曲或為直線邊緣的線條。更多的過濾器,激活圖的深度越大,我們對輸入量的信息也越多。
免責聲明:本節中描述的過濾器對描述卷積過程中數學的主要目的是簡單的。在下面的圖片中,您將看到一些經過訓練的網絡的第一個conv層過濾器的實際可視化示例。盡管如此,主要論點仍然是一樣的。第一層上的過濾器在輸入圖像周圍進行卷積,并在其正在查找的特定功能位于輸入體積中時"激活"(或計算高值)。

(快速提示:上面的圖片來自斯坦福大學的由Andrej Karpathy和Justin Johnson教授,推薦給那些希望更深入了解CNN的人。)
越來越深入的網絡
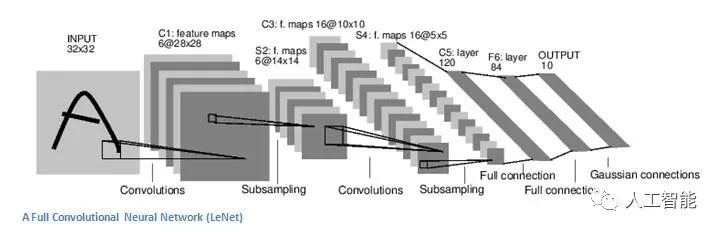
現在在傳統的卷積神經網絡架構中,在這些conv層之間還有其他層。我強烈鼓勵有興趣的讀者了解他們的功能和效果,但是從一般意義上說,他們提供了非線性和維度維度,有助于提高網絡的魯棒性和控制過擬合。一個經典的CNN架構看起來就像這樣。

然而,最后一層是一個重要的層面,我們稍后會介紹。讓我們退一步看看迄今為止我們已經學到了什么。我們討論了第一個conv層中的過濾器是用來檢測的。他們檢測低級功能,如邊緣和曲線。正如人們所想象的,為了預測圖像是否是一種對象,我們需要網絡能夠識別更高層次的特征,如手或爪子或耳朵。那么讓我們來思考第一個conv層之后的網絡輸出結果。這將是一個28×28×3的體積(假設我們使用三個5×5×3濾波器)。當我們經過另一個conv層時,第一個conv層的輸出成為第二個的輸入conv層。現在,這看起來有點難以想象。當我們在談論第一層時,輸入只是原始圖像。然而,當我們談論第二層次的時候,輸入是第一層產生的激活圖。因此,輸入的每一層都基本上描述了原始圖像中某些低級特征出現的位置。現在當你在上面應用一組過濾器時(通過第二個過濾器)conv層),則輸出將是代表更高級特征的激活。這些特征的類型可以是半圓(曲線和直邊的組合)或正方形(幾個直邊的組合)。當您瀏覽網絡并通過更多的轉發層時,您將獲得代表越來越復雜功能的激活地圖。在網絡結束時,您可能會有一些過濾器在圖像中有手寫時激活,過濾器在看到粉紅色的物體時激活,等等。如果您想要了解關于在ConvNets中可視化過濾器的更多信息,Matt Zeiler和Rob Fergus一個很好的研究論文討論的話題。杰森Yosinski也有一個視頻在YouTube上提供了一個很好的視覺表現。另一個值得注意的事情是,當你深入到網絡中時,過濾器開始具有越來越大的接受范圍,這意味著他們能夠從原始輸入量的較大區域中考慮信息(另一種放置方式它們對像素空間的較大區域更敏感)。
完全連接層
現在,我們可以檢測到這些高級功能,蛋糕上的糖霜就是連接一個完全連接的層到網絡的盡頭。這個圖層基本上需要一個輸入量(無論輸出是在其之前的conv或ReLU還是pool層),并輸出一個N維向量,其中N是程序必須從中選擇的類的數量。例如,如果你想要一個數字分類程序,N將是10,因為有10個數字。這個N維向量中的每個數字表示某個類別的概率。例如,如果用于數字分類程序的結果向量是[0.1.175 0 0 0 0 0 .05],那么這代表10%的概率,即圖像是1,10%的概率圖像是2,圖像是3的概率是75%,圖像是9的概率是5%(注意:還有其他方法可以表示輸出,但我只是展示了softmax方法)。完全連接圖層的工作方式是查看上一層的輸出(我們記得它應該代表高級特征的激活圖),并確定哪些特征與特定類最相關。例如,如果程序預測某些圖像是狗,則在激活圖中將具有高值,例如爪子或4條腿等的高級特征。類似地,如果程序預測某圖像是鳥,它將在激活地圖中具有很高的價值,代表像翅膀或喙等高級特征。基本上,FC層看著什么高級特征與特定類最強關聯,并具有特定的權重,以便當你計算權重與上一層之間的乘積,
培訓(又名:什么使這個東西工作)
現在,這是我故意沒有提到的神經網絡的一個方面,它可能是最重要的部分。閱讀時可能有很多問題。第一個conv層中的過濾器如何知道要查找邊和曲線?完全連接的圖層如何知道要查看的激活圖?每層中的過濾器如何知道有什么值?計算機能夠調整其過濾值(或權重)的方式是通過稱為反向傳播的訓練過程。
在我們進入反向傳播之前,我們必須先退后一步,討論神經網絡的工作需求。現在我們都出生了,我們的思想是新鮮的。我們不知道什么是貓,狗或鳥。以類似的方式,在CNN開始之前,權重或篩選值是隨機的。過濾器不知道尋找邊緣和曲線。在更高層的過濾器不知道尋找爪子和喙。然而,隨著年齡的增長,我們的父母和老師向我們展示了不同的圖片和圖片,并給了我們相應的標簽。被賦予形象和標簽的想法是CNN經歷的培訓過程。在深入研究之前,我們假設我們有一套訓練集,其中包含成千上萬的狗,貓和鳥的圖像,每個圖像都有一個這個圖像是什么動物的標簽。
所以反向傳播可以分為4個不同的部分,正向傳遞,丟失函數,反向傳遞和權重更新。在正向傳球過程中,您將會看到一張訓練圖像,我們記得這是一個32 x 32 x 3的數字數組,并將其傳遞給整個網絡。在我們的第一個訓練樣例中,由于所有的權值或過濾值都是隨機初始化的,因此輸出結果可能類似[.1.1.1.1.1.1.1.1.1.1],基本上是輸出不特別優先考慮任何數字。網絡以其當前的權重無法查找這些低級特征,因此無法就分類的可能性作出任何合理的結論。這轉到損失功能反向傳播的一部分。請記住,我們現在使用的是培訓數據。這個數據有一個圖像和一個標簽。例如,假設輸入的第一個訓練圖像是3,圖像的標簽是[0 0 0 1 0 0 0 0 0 0]。損失函數可以用許多不同的方式來定義,但常見的是MSE(均方誤差),是實際預測的平方的1.5倍。
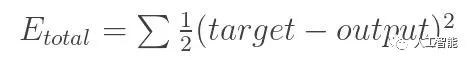
假設變量L等于該值。正如你可以想象的那樣,第一對訓練圖像的損失將非常高。現在,讓我們直觀地思考這個問題。我們希望達到預測的標簽(ConvNet的輸出)與訓練標簽相同的點(這意味著我們的網絡得到了預測權)。為了達到這個目的,我們希望最小化損失量我們有。將這看作是微積分中的一個優化問題,我們想要找出哪些輸入(權重在我們的情況下)是最直接導致網絡損失(或錯誤)的因素。
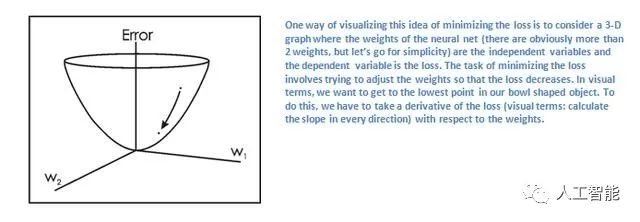
這是dL / dW的數學等價物,其中W是特定層的權重。現在,我們要做的是通過網絡進行反向傳遞,即確定哪些權重對損失貢獻最大,并設法調整損失,從而減少損失。一旦我們計算出這個導數,我們就會進入權重更新的最后一步。這是我們取得所有過濾器的權重,并更新它們,使它們在梯度的相反方向變化。

該學習速率是由程序員選擇的參數。高學習率意味著在權重更新中采取更大的步驟,因此,模型可能花費較少的時間來收斂于最優權重集合。但是,如果學習速度過高,可能會導致跳躍過大,不夠精確,無法達到最佳點。

正向傳遞,丟失函數,反向傳遞和參數更新的過程是一次訓練迭代。程序將重復這個過程,對每組訓練圖像(通常稱為批次)進行固定次數的迭代。一旦你完成了最后一個訓練樣例的參數更新,希望網絡應該被訓練得足夠好,這樣層的權重才能被正確地調整。
測試
最后,為了看看我們的CNN是否有效,我們有一套不同的圖像和標簽(在訓練和測試之間不能一蹴而就),并通過CNN傳遞圖像。我們將輸出與實際情況進行比較,看看我們的網絡是否正常工作!
公司如何使用CNNs
數據,數據,數據。那些擁有這個神奇的4字母詞的公司就是那些比其他競爭者具有內在優勢的公司。您可以為網絡提供的培訓數據越多,您可以進行的培訓迭代次數越多,您可以進行的權重更新越多,調整到網絡的時間越長。Facebook(和Instagram)可以使用目前擁有的十億用戶的所有照片,Pinterest可以使用其網站上500億個引腳的信息,Google可以使用搜索數據,Amazon可以使用數百萬個產品每天都買。現在你知道他們如何使用它的魔法了。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100721 -
深度學習
+關注
關注
73文章
5500瀏覽量
121118 -
cnn
+關注
關注
3文章
352瀏覽量
22204
原文標題:深度學習初學者了解CNN卷積神經網絡的黃金指南
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
卷積神經網絡的基本概念、原理及特點
卷積神經網絡的實現原理
卷積神經網絡分類方法有哪些
卷積神經網絡的基本結構和工作原理
cnn卷積神經網絡三大特點是什么
卷積神經網絡訓練的是什么
深度學習與卷積神經網絡的應用
卷積神經網絡的原理與實現
卷積神經網絡cnn模型有哪些
卷積神經網絡的基本結構及其功能
卷積神經網絡的原理是什么
深度神經網絡模型cnn的基本概念、結構及原理
詳解深度學習、神經網絡與卷積神經網絡的應用






 工商網監
工商網監
評論