 三種回歸算法及其優缺點,將會為我們理解和選擇算法提供很好的幫助
三種回歸算法及其優缺點,將會為我們理解和選擇算法提供很好的幫助
任何一個機器學習問題都有著不止一種算法來解決,在機器學習領域“沒有免費的午餐”的意思就是沒有一個對于所有問題都很好的算法。機器學習算法的表現很大程度上與數據的結構和規模有關。所以判斷算法性能最好的辦法就是在數據上運行比較結果。
不過與此同時我們對于算法的優缺點有一定的了解可以幫助我們找需要的算法。本文將會介紹三種回歸算法及其優缺點,將會為我們理解和選擇算法提供很好的幫助。
線性和多項式回歸
在這一簡單的模型中,單變量線性回歸的任務是建立起單個輸入的獨立變量與因變量之間的線性關系;而多變量回歸則意味著要建立多個獨立輸入變量與輸出變量之間的關系。除此之外,非線性的多項式回歸則將輸入變量進行一系列非線性組合以建立與輸出之間的關系,但這需要擁有輸入輸出之間關系的一定知識。訓練回歸算法模型一般使用隨機梯度下降法(SGD)。
優點:
建模迅速,對于小數據量、簡單的關系很有效;
線性回歸模型十分容易理解,有利于決策分析。
缺點:
對于非線性數據或者數據特征間具有相關性多項式回歸難以建模;
難以很好地表達高度復雜的數據。
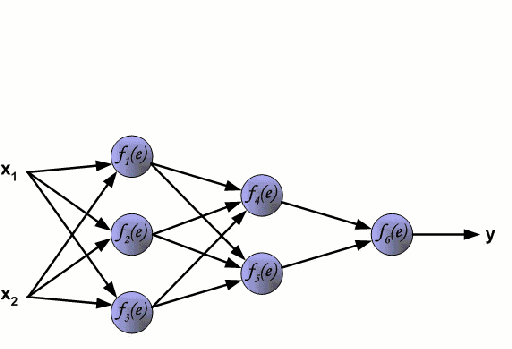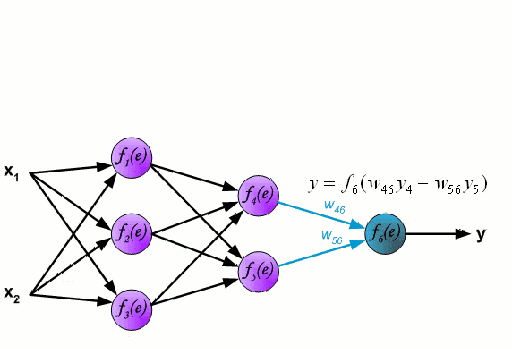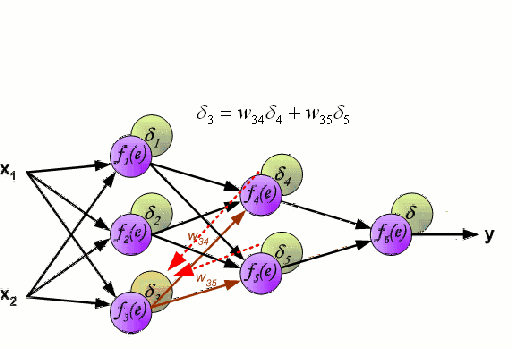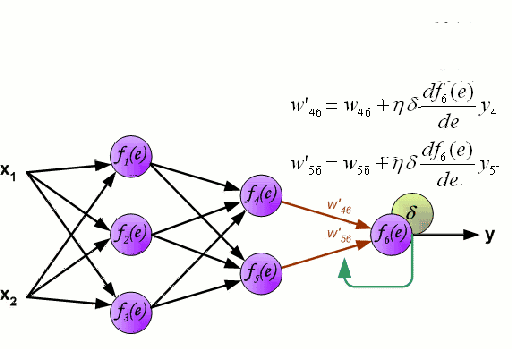
神經網絡由一系列稱為神經元的節點通過內部網絡連接而成,數據的特征通過輸入層被逐級傳遞到網絡中,形成多個特征的線性組合,每個特征會與網絡中的權重相互作用。隨后神經元對線性組合進行非線性變化,這使得神經網絡模型具有對多特征復雜的非線性表征能力。神經網絡可以具有多層結構,以增強對于輸入數據特征的表征。人們一般利用隨機梯度下降法和反向傳播法來對神經網絡進行訓練,請參照上述圖解。
優點:
多層的非線性結構可以表達十分復雜的非線性關系;
模型的靈活性使得我們不需要關心數據的結構;
數據越多網絡表現越好。
缺點:
模型過于復雜,難以解釋;
訓練過程需要強大算力、并且需要微調超參數;
對數據量依賴大,但常規機器學習問題則使用較小量數據。
回歸樹和回歸森林
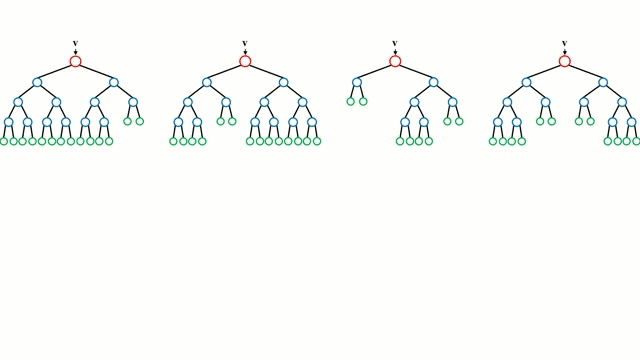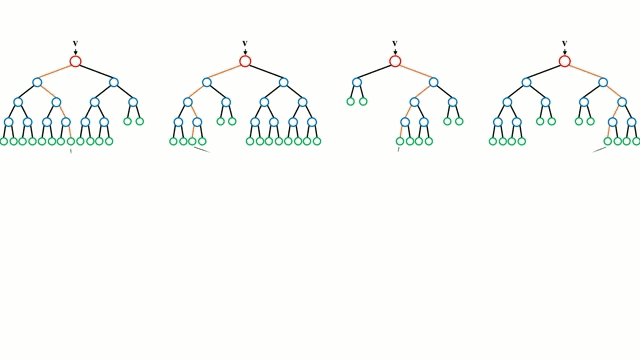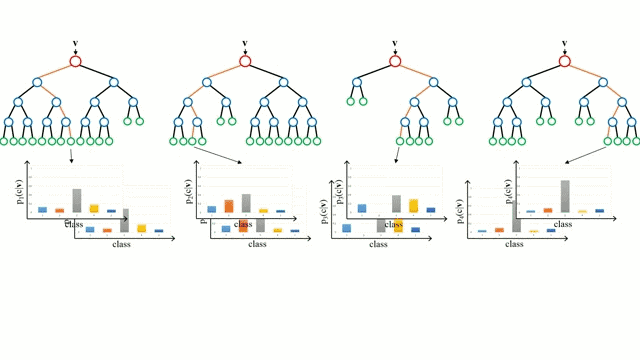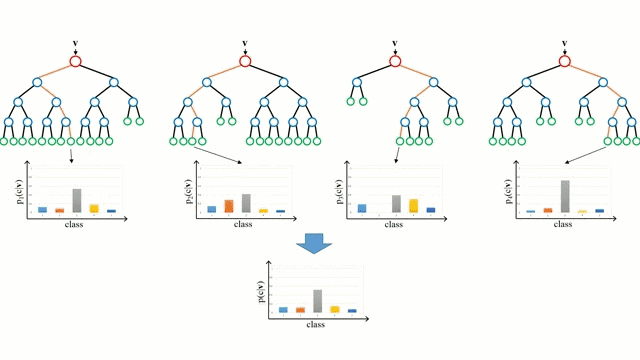
讓我們從最基本的概念出發,決策樹是通過遍歷樹的分支并根據節點的決策選擇下一個分支的模型。樹型感知利用訓練數據作為數據,根據最適合的特征進行拆分,并不斷進行循環指導訓練數據被分到一類中去。建立樹的過程中需要將分離建立在最純粹的子節點上,從而在分離特征的情況下保持分離數目盡可能的小。純粹性是來源于信息增益的概念,它表示對于一個未曾謀面的樣本需要多大的信息量才能將它正確的分類。實際上通過比較熵或者分類所需信息的數量來定義。而隨機森林則是決策樹的簡單集合,輸入矢量通過多個決策樹的處理,最終的對于回歸需要對輸出數據取平均、對于分類則引入投票機制來決定分類結果。
優點:
具有很高的復雜度和高度的非線性關系,比多項式擬合擁有更好的效果;
模型容易理解和闡述,訓練過程中的決策邊界容易實踐和理解。
缺點:
由于決策樹有過擬合的傾向,完整的決策樹模型包含很多過于復雜和非必須的結構。但可以通過擴大隨機森林或者剪枝的方法來緩解這一問題;
較大的隨機數表現很好,但是卻帶來了運行速度慢和內存消耗高的問題。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100719 -
機器學習
+關注
關注
66文章
8407瀏覽量
132567
原文標題:如何為回歸問題選擇一個合適的算法呢?我們先從模型的優缺點講起...
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
常見算法優缺點比較
FDTD和FEM算法各有什么優缺點
回歸算法有哪些,常用回歸算法(3種)詳解
FOC中的三種電流采樣方式,你知道怎么選擇嗎?
算法的三種結構介紹
如何提升示波器波形質量 三種波形算法的應用
三種PCB電路板灌封膠的優缺點
三種失電延裝置的構成原理及優缺點





 工商網監
工商網監
評論