 回歸樣條法介紹及其實現步驟與技巧
回歸樣條法介紹及其實現步驟與技巧
作為數據科學領域的新手,你接觸的第一個算法是不是線性回歸?當你把它用于不同的數據集時,你會發現它非常簡單方便,但現實中的很多問題是非線性的,這種依賴因變量和自變量之間線性關系的做法有時行不通。這時,你嘗試了多項式回歸,雖然大部分時間它給出了更好的結果,但在面對高度可變的數據集時,你的模型也會頻繁地過擬合。
過擬合
我們的模型總是變得太靈活,這對“看不見”的數據來說其實并不合適。你也許聽說過加權最小二乘估計(weighted least-squares)、核估計(kernel smoother)、局部多項式估計(local polynomial fitting),但談到對模型中未知函數的估計,樣條估計依然占據著重要的位置。本文將通過一些線性和多項式回歸的基礎知識,簡要介紹樣條估計的一種方法——回歸樣條法(regression spline)以及它的Python實現。
注:本文來自印度數據科學家Gurchetan Singh,假設讀者對線性回歸和多項式回歸有初步了解。
目錄
1.了解數據
2.線性回歸
3.線性回歸改進:多項式回歸
4.回歸樣條法及其實現
分段階梯函數
基函數
分段多項式
限制和樣條
三次樣條和自然三次樣條
選擇結點的數量和位置
回歸樣條與多項式回歸的比較
了解數據
為了理解這些概念,首先我們還是得提一下這本黃黃的、“可愛”的、磚頭一樣的教材:《統計學習入門》(An Introduction to Statistical Learning with Applications in R)。幾天前twitter上有許多人轉發了一個段子,說有人在馬路邊撿到了一本破爛的《統計學習入門》,邊上躺著一個空的伏特加酒瓶和空煙盒,這本書的“毒性”請自行體會。
***、酒精以及SVM
書中提到了一個工資預測數據集,感興趣的讀者可以點擊這里下載。這個數據集包含諸如身份ID、年份、年齡、性別、婚姻狀況、種族、受教育程度、所在地、工作類別、健康狀況、保險繳納和工資等多種信息。為了介紹樣條回歸,這里我們把“年齡”作為自變量,用它來預測目標的工資情況(因變量)。
先處理數據:
# 導入模塊
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
%matplotlib inline
# 讀取data_set
data = pd.read_csv("Wage.csv")
data.head()

data_x = data['age']
data_y = data['wage']
# 將數據分為訓練集和測試集
from sklearn.model_selection import train_test_split
train_x, valid_x, train_y, valid_y = train_test_split(data_x, data_y, test_size=0.33, random_state = 1)
# 年齡和工資關系b/w的可視化
import matplotlib.pyplot as plt
plt.scatter(train_x, train_y, facecolor='None', edgecolor='k', alpha=0.3)
plt.show()
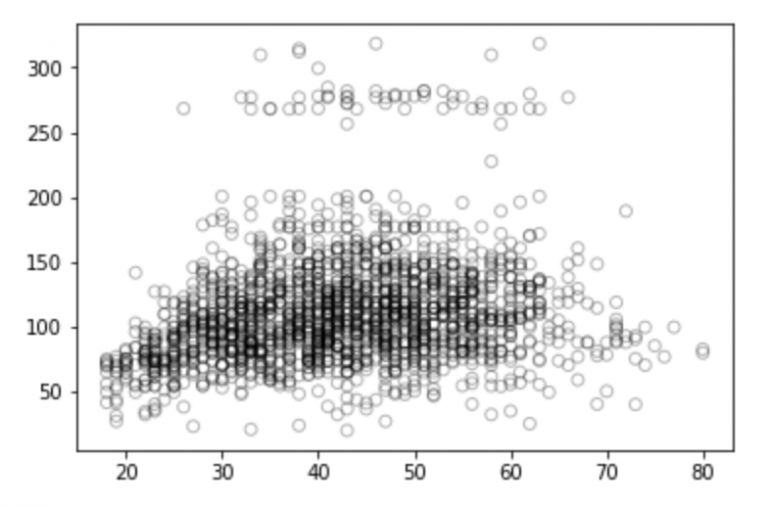
看了這幅圖,你對這些離散的點有什么想法嗎?它們是積極的、消極的還是全然不相關的?你可以在評論區談談自己的想法。但別急,我們先做一些分析。
線性回歸
線性回歸是一種極其簡單的、使用最廣泛的用于預測建模的統計方法。作為監督學習算法,它能解決回歸問題。當我們建立起因變量和自變量之間的線性關系后,這時我們就得到了一個線性模型。從數學角度看,它可以被當做是一個線性表達式:
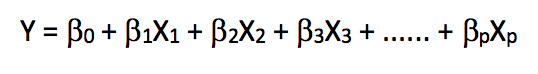
在上式中,Y是因變量,X是自變量,也就是我們常說的特征,β則是分配給特征的權值系數,它們表示各個特征對于最終預測結果的重要性。例如我們設X1對方程結果的影響最大,那么和其他特征相比,β1/權重 的值會大于其他系數和權重的商。
那么,如果我們的線性回歸中只有一個特征,這個等式會變成什么樣?
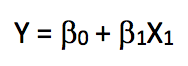
我們把這種只包含一個獨立變量的線性回歸稱為簡單線性回歸。因為之前的目標是根據“年齡”預測員工的“工資”,所以我們將在訓練集上執行簡單線性回歸,并在測試集上計算模型的誤差(均方誤差RMSE)。
from sklearn.linear_model importLinearRegression
# Fit線性回歸模型
x = train_x.reshape(-1,1)
model = LinearRegression()
model.fit(x,train_y)
print(model.coef_)
print(model.intercept_)
-> array([0.72190831])
-> 80.65287740759283
# 在測試集上預測
valid_x = valid_x.reshape(-1,1)
pred = model.predict(valid_x)
# 可視化
# 我們將從valid_x的最小值和最大值之間選70個plot畫圖
xp = np.linspace(valid_x.min(),valid_x.max(),70)
xp = xp.reshape(-1,1)
pred_plot = model.predict(xp)
plt.scatter(valid_x, valid_y, facecolor='None', edgecolor='k', alpha=0.3)
plt.plot(xp, pred_plot)
plt.show()
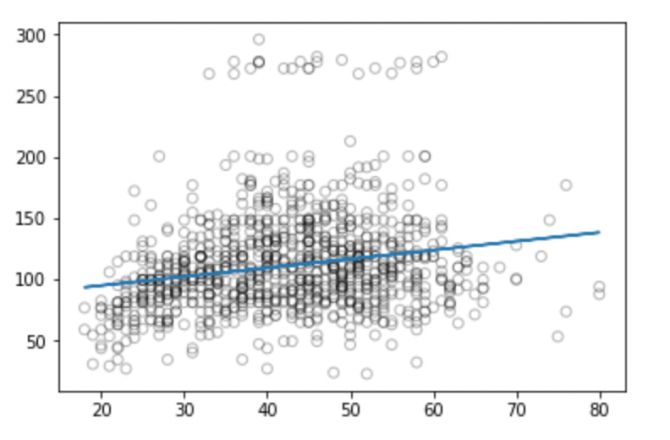
現在我們可以計算模型預測的RMSE:
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(valid_y, pred))
print(rms)
-> 40.436
從圖中我們可以看到,線性回歸沒法捕捉所有可用的信號,結果不太好。
盡管線性模型的描述和實現相對簡單,而且在解釋和推理方面也更有優勢,但它確實在性能上存在重大限制。線性模型假設各個獨立變量之間存在線性關系,可惜的是這總是一個直線擬合的近似值,有時候它的精度會很差。
既然線性模型精度一般,那么我們暫且把線性假設放在一邊,在它的基礎上進行擴展,比如用多項式回歸、階梯函數等使模型獲得性能提升。
線性回歸改進:多項式回歸
我們先來看看這些可視化圖像:
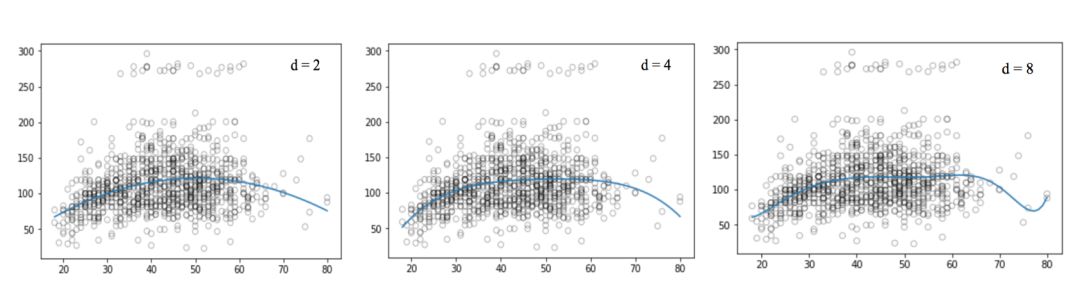
和線性回歸那張圖相比,上圖中的曲線似乎更好地擬合了工資和年齡信號的分布,它們在形狀上是非線性的。像這種使用非線性函數的做法,我們稱它為多項式回歸。
多項式回歸通過增加額外預測因子來擴展線性模型,它最直接的做法是在原先的自變量基礎上添加乘方運算(冪)。例如一個三次回歸會把X1、X22、X33作為自變量。
將線性回歸擴展到因變量和自變量之間的非線性關系的一種標準方法是用多項式函數代替線性模型。
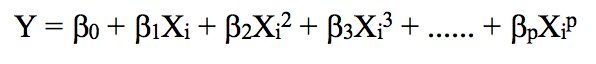
如果我們提高階值,整個曲線會出現高頻震蕩,它的后果是模型過擬合。
# 為二次回歸函數生成權值,degree =2
weights = np.polyfit(train_x, train_y, 2)
print(weights)
-> array([ -0.05194765, 5.22868974, -10.03406116])
# 用給定的權值生成模型
model = np.poly1d(weights)
# 在測試集上預測
pred = model(valid_x)
# 用70個觀察值畫圖
xp = np.linspace(valid_x.min(),valid_x.max(),70)
pred_plot = model(xp)
plt.scatter(valid_x, valid_y, facecolor='None', edgecolor='k', alpha=0.3)
plt.plot(xp, pred_plot)
plt.show()

同樣的,我們可以提高函數的冪(d),看看四次、十二次、十六次、二十五次回歸函數的圖像:
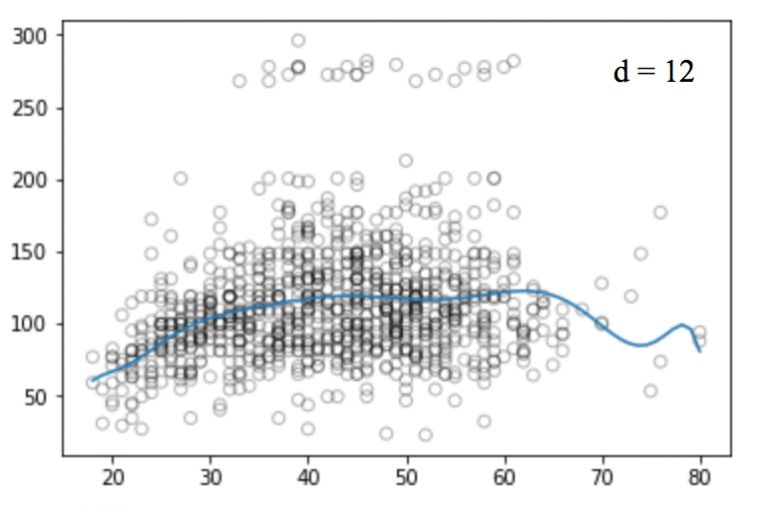
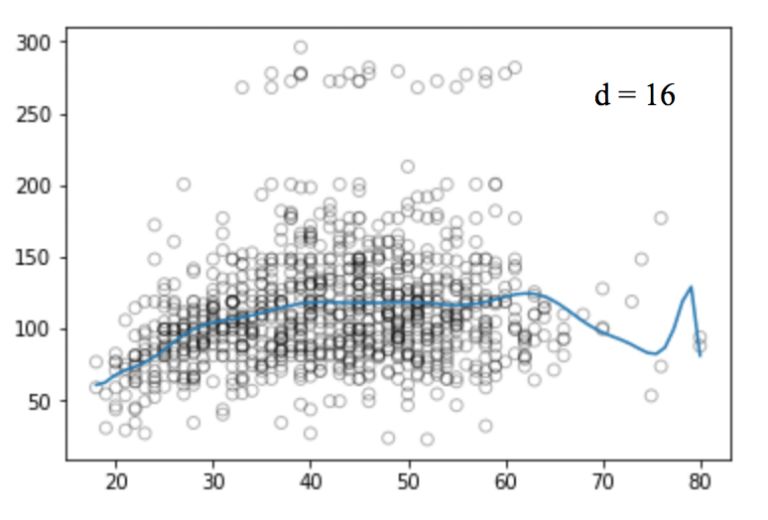
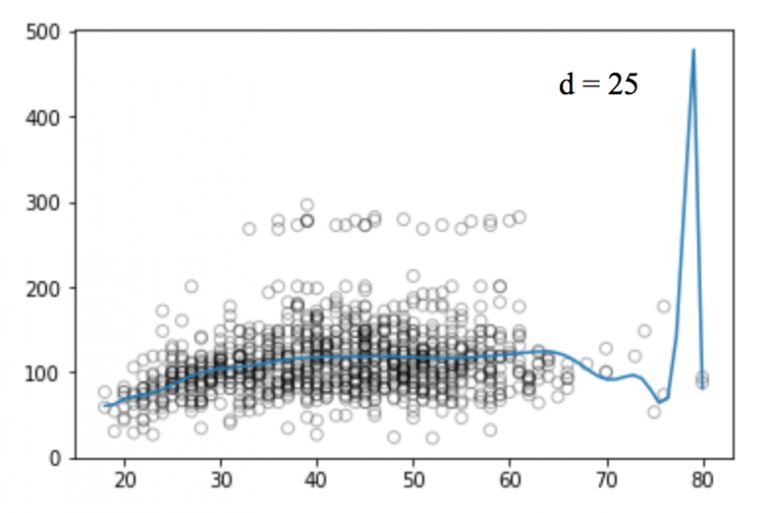
和線性回歸一樣,多項式回歸的缺點也不少。一方面,隨著等式變得越來越復雜,函數的數量也會逐漸增加,這就導致我們很難對它們進行處理。另一方面,正如上圖所展示的,即便是在這么簡單的一維數據集上,冪越高,曲線經過的信號點越多,形狀也越詭異,這時模型已經出現過擬合傾向。它并沒有從輸入和輸出中推導出一般規律,而是簡單記憶訓練集的結果,這樣的模型在測試集上不會有良好的性能。
多項式回歸還有一些其他的問題,比如它在本質上是非局部的。如果我們改變訓練集上一個點的Y值,這會影響多項式對遠處某點的擬合情況。因此,為了避免在整個數據集上使用高階多項式,我們可以用多個不同的低階多項式函數作為替代。
回歸樣條法及其實現
為了克服多項式回歸的缺點,一種可行的改進方法是不把訓練集作為一個整體,而是把它劃分成多個連續的區間,并用單獨的模型來擬合。這種方法被稱為回歸樣條。
回歸樣條法是最重要的非線性回歸方法之一。在普通多項式回歸中,我們通過在現有特征基礎上使用多項式函數來生成新特征,對于數據集而言,這些特征具有全局性影響。為了解決這個問題,我們可以把數據分布分成不同的幾個部分,然后針對每一部分擬合線性或非線性的低階多項式函數。
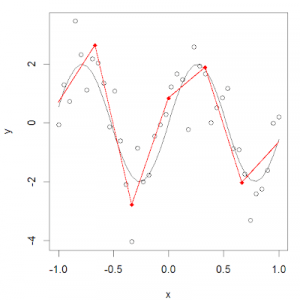
我們把這些分區的紅點稱為節點(knot),把擬合單個區間數據分布的函數稱為分段函數(piecewise function)。如上圖所示,這個數據分布可以用多個分段函數來擬合。
分段階梯函數
階梯函數是最常見的分段函數之一,它是一個在一定區間內保持不變的函數。通過使用階梯函數,我們能把X的范圍分成幾個區間(bin),并在每個區間內擬合不同的常數。
換句話說,假設我們在X范圍內設置了K個節點:C1,C2,...,CK,然后構建K+1個新變量:
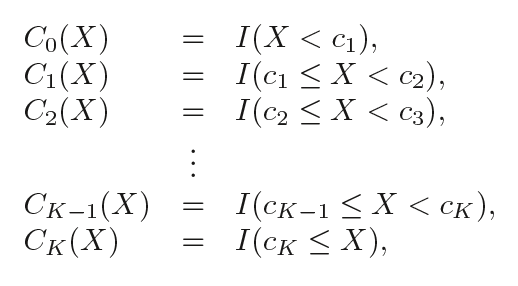
I( )是個指示函數,如果在范圍內,即條件為真就返回1;否則返回0。
# 把數據分成4個連續的區間
df_cut, bins = pd.cut(train_x, 4, retbins=True, right=True)
df_cut.value_counts(sort=False)
->
(17.938, 33.5] 504
(33.5, 49.0] 941
(49.0, 64.5] 511
(64.5, 80.0] 54
Name: age, dtype: int64
df_steps = pd.concat([train_x, df_cut, train_y], keys=['age','age_cuts','wage'], axis=1)
# 為年齡組創建虛擬變量
df_steps_dummies = pd.get_dummies(df_cut)
df_steps_dummies.head()
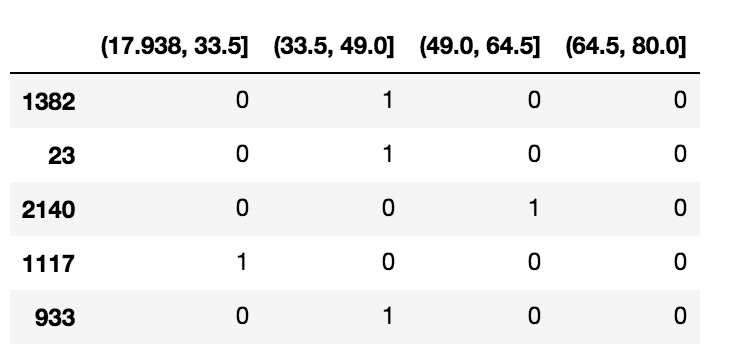
df_steps_dummies.columns = ['17.938-33.5','33.5-49','49-64.5','64.5-80']
# 擬合廣義線性模型
fit3 = sm.GLM(df_steps.wage, df_steps_dummies).fit()
# 把分段函數對應到相應的4個區間內
bin_mapping = np.digitize(valid_x, bins)
X_valid = pd.get_dummies(bin_mapping)
# 刪除異常值
X_valid = pd.get_dummies(bin_mapping).drop([5], axis=1)
# 預測
pred2 = fit3.predict(X_valid)
# 計算RMSE
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(valid_y, pred2))
print(rms)
->39.9
# 用70個觀察值畫圖
xp = np.linspace(valid_x.min(),valid_x.max()-1,70)
bin_mapping = np.digitize(xp, bins)
X_valid_2 = pd.get_dummies(bin_mapping)
pred2 = fit3.predict(X_valid_2)
# 可視化
fig, (ax1) = plt.subplots(1,1, figsize=(12,5))
fig.suptitle('Piecewise Constant', fontsize=14)
# 多項式回歸線散點圖
ax1.scatter(train_x, train_y, facecolor='None', edgecolor='k', alpha=0.3)
ax1.plot(xp, pred2, c='b')
ax1.set_xlabel('age')
ax1.set_ylabel('wage')
plt.show()
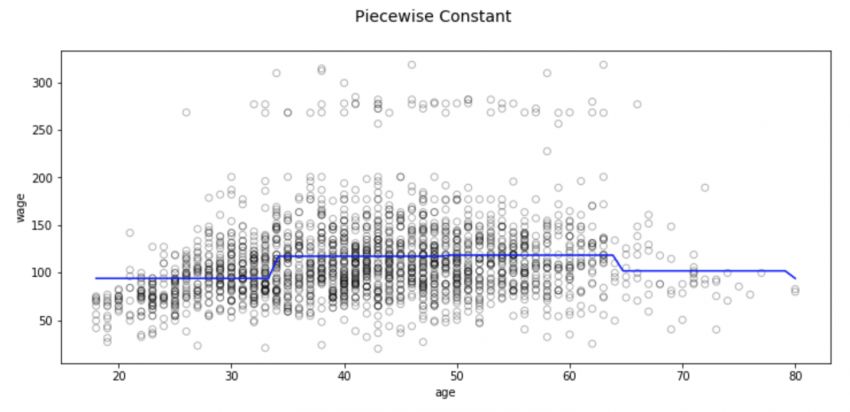
這種分區方法也存在一些問題,其中最顯著的是我們期望輸入不同,模型的輸出也會發生相應變化。但分類回歸不會創建預測變量的連續函數,因此在大多數情況下,其實它的假設是輸入和輸出之間沒有關系。例如在上圖中,第一個區間的函數顯然沒有發現到隨年齡增長工資也會不斷上漲的趨勢。
基函數
為了捕捉回歸模型中的非線性因素,我們需要對一部分甚至所有的預測變量做一些變換。我們希望這是一個非常普遍的變換,它既能避免模型把每個自變量看作線性的,可以靈活地擬合各種形狀的數據分布,又相對的不那么“靈活”,能有效防止過擬合。
像這種可以組合在一起以捕捉數據分布情況的變換,我們稱之為基函數,也稱樣條基。在根據年齡預測工資的這個問題中,樣條基為b1(X), b2(X),…,bK(X)。
現在,我們不再用X擬合線性模型,而是用這個新模型:
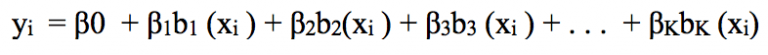
讓我們深入了解基函數的一種基礎用法:分段多項式。
分段多項式
在介紹分段階梯函數時,我們介紹它是“把X分成幾個區間,并在每個區間內擬合不同的常數”,套用線性回歸和多項式回歸的區別,分段多項式則是把X分成幾個區間,并在每個區間內擬合不同的低階多項式函數。由于函數的冪較低,所以圖像不會劇烈震蕩。
例如,分段二次多項式可以通過擬合二元回歸方程來發揮作用:
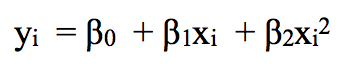
其中β0、β1和β2在不同區間內取值不同。詳細來說,如果我們有一個包含單個節點c的數據集,那它的分段三次多項式應該具有以下形式:
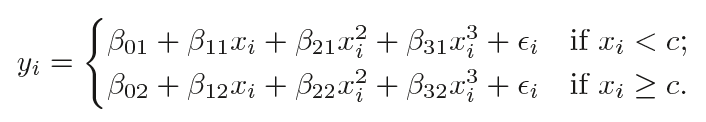
這其實是擬合了兩個不同的多項式函數:一個xi
需要注意的一點是,這個多項式函數共有8個變量,每個多項式4個。
節點越多,分段多項式就越靈活,因為我們要為每個X區間分配不同的函數,而函數的形式則取決于該區間的數據分布。一般來說,如果我們在整個X范圍內設置了K個不同的節點,我們最終將擬合K+1個不同的三次多項式。理論上來說,我們可以用任意低階多項式擬合某個單獨區間。
現在我們來看看設計分段多項式時應遵循的一些必要條件和限制條件。
約束和樣條
能擬合目標區間數據分布的函數有很多,但分段多項式是不能隨便設的,它也有各種需要遵循的限制條件。我們先來看看這幅圖:
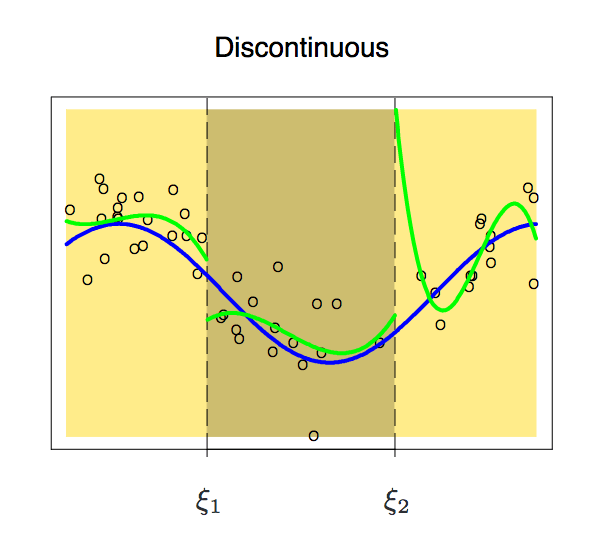
因為是分段的,兩個區間的函數可能會出現不連續的現象。為了避免這種情況,一個必要的額外限制就是任一側的多項式在節點上應該是連續的。
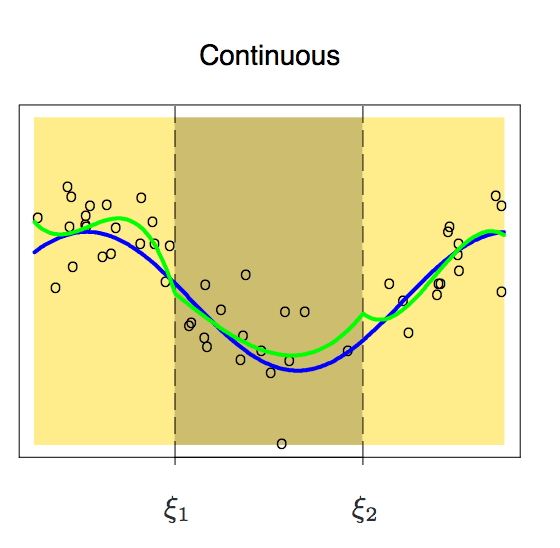
增加了這個約束條件后,我們得到了一條連續的曲線,但它看起來完美嗎?答案顯然是否定的,在閱讀下文之前,我們可以先自行思考一個問題,為什么我們不能接受這種不流暢的曲線?
根據上圖可以發現,這時節點在曲線上還很突出,為了平滑節點上的多項式,我們需要增加一個新約束:兩個多項式的一階導數必須相同。這里有一點值得注意,我們每增加一個條件,多項式就有效釋放一個自由度,這可以降低分段多項式擬合的復雜性。因此在上圖中,我們只用了10個自由度而不是12個。
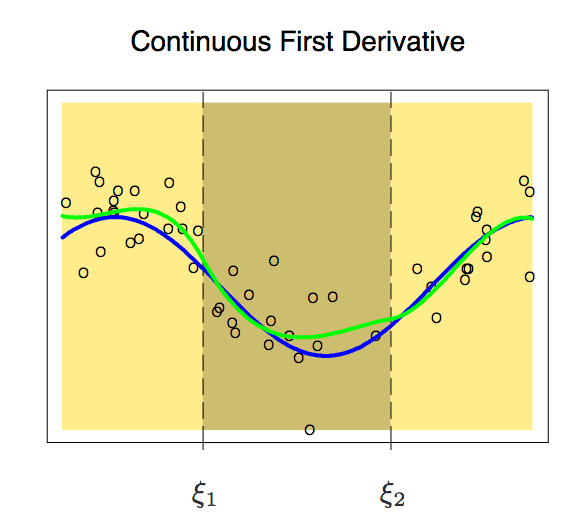
加入一階導數后,現在我們的多項式稍稍變得平滑了一些。這時它的自由度也從12個減少到了8個。雖然曲線改進了不少,但它還有不少提升空間。所以現在,我們再向它施加一個新約束:一個節點上兩個多項式的二階導數必須相同。
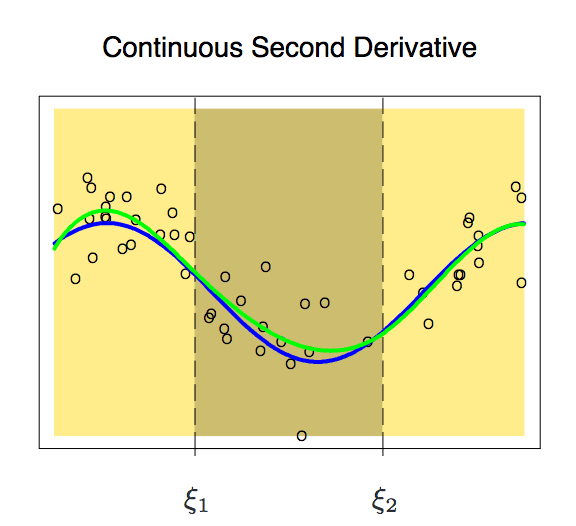
這條曲線就比較符合我們預期了,它只有6個自由度。像這樣具有m-1個連續導數的m階分段多項式,我們稱之為樣條(Spline)。
三次樣條和自然三次樣條
三次樣條指的是具有一組約束(連續性、一階和二階連續性)的分段多項式。通常情況下,具有K個節點的三次樣條一般有(K+1)×4-K×3,也就是K+4個維度。當K=3時,維度為8,這時圖像的自由度是維度-1=7。一般情況下,我們只用三次樣條。
from patsy import dmatrix
import statsmodels.api as sm
import statsmodels.formula.api as smf
# 在25、40和60三個節點生成三次樣條
transformed_x = dmatrix("bs(train, knots=(25,40,60), degree=3, include_intercept=False)", {"train": train_x},return_type='dataframe')
# 在分區的數據集上擬合廣義線性模型
fit1 = sm.GLM(train_y, transformed_x).fit()
# 生成4節三次樣條曲線
transformed_x2 = dmatrix("bs(train, knots=(25,40,50,65),degree =3, include_intercept=False)", {"train": train_x}, return_type='dataframe')
# 在分區的數據集上擬合廣義線性模型
fit2 = sm.GLM(train_y, transformed_x2).fit()
# 兩個樣條同時預測
pred1 = fit1.predict(dmatrix("bs(valid, knots=(25,40,60), include_intercept=False)", {"valid": valid_x}, return_type='dataframe'))
pred2 = fit2.predict(dmatrix("bs(valid, knots=(25,40,50,65),degree =3, include_intercept=False)", {"valid": valid_x}, return_type='dataframe'))
# 計算RMSE
rms1 = sqrt(mean_squared_error(valid_y, pred1))
print(rms1)
-> 39.4
rms2 = sqrt(mean_squared_error(valid_y, pred2))
print(rms2)
-> 39.3
# 用70個觀察值畫圖
xp = np.linspace(valid_x.min(),valid_x.max(),70)
# 預測
pred1 = fit1.predict(dmatrix("bs(xp, knots=(25,40,60), include_intercept=False)", {"xp": xp}, return_type='dataframe'))
pred2 = fit2.predict(dmatrix("bs(xp, knots=(25,40,50,65),degree =3, include_intercept=False)", {"xp": xp}, return_type='dataframe'))
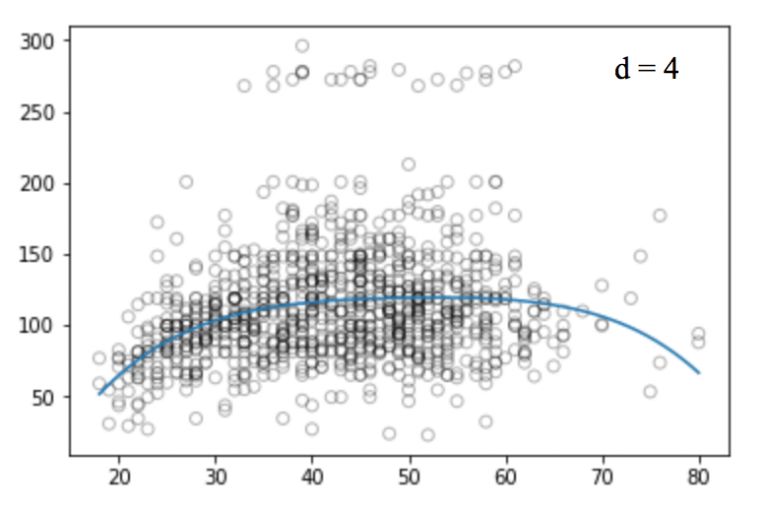
# 繪制樣條曲線和誤差曲線
plt.scatter(data.age, data.wage, facecolor='None', edgecolor='k', alpha=0.1)
plt.plot(xp, pred1, label='Specifying degree =3 with 3 knots')
plt.plot(xp, pred2, color='r', label='Specifying degree =3 with 4 knots')
plt.legend()
plt.xlim(15,85)
plt.ylim(0,350)
plt.xlabel('age')
plt.ylabel('wage')
plt.show()
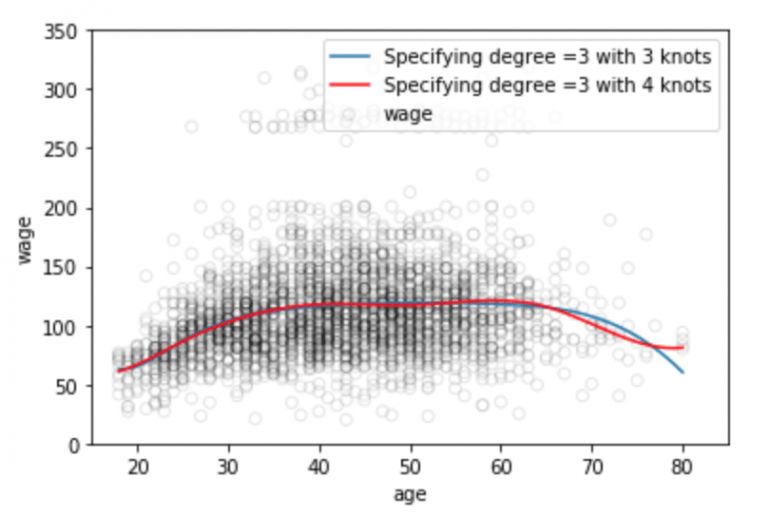
眾所周知,擬合數據分布的多項式函數在數據邊界地帶往往是不穩定的,邊界區域的已知數據少,函數曲線常常會過擬合,這個問題同樣存在于樣條中。為了使多項式更平滑地擴展到邊界節點之外,我們需要用到一種叫做自然樣條的特殊方法。
相比三次樣條,自然三次樣條在邊界區域增加了一個線性約束。這里我們說明一下,邊界區域指的是自變量X的最大值/最小值與相應的最大最小節點之間的區域,這里信號比較稀疏,用線性處理簡單控制RMSE值是可以接受的。這時函數的三階、二階就成了0,每個減少2個自由度,而這些自由度又在每條曲線的兩段,所以多項式的維度K+4個維度這時就變成了K。
# 生成自然三次樣條
transformed_x3 = dmatrix("cr(train,df = 3)", {"train": train_x}, return_type='dataframe')
fit3 = sm.GLM(train_y, transformed_x3).fit()
# 在測試集上預測
pred3 = fit3.predict(dmatrix("cr(valid, df=3)", {"valid": valid_x}, return_type='dataframe'))
# Calculating RMSE value
rms = sqrt(mean_squared_error(valid_y, pred3))
print(rms)
-> 39.44
# 用70個觀察值畫圖
xp = np.linspace(valid_x.min(),valid_x.max(),70)
pred3 = fit3.predict(dmatrix("cr(xp, df=3)", {"xp": xp}, return_type='dataframe'))
# 繪制樣條曲線
plt.scatter(data.age, data.wage, facecolor='None', edgecolor='k', alpha=0.1)
plt.plot(xp, pred3,color='g', label='Natural spline')
plt.legend()
plt.xlim(15,85)
plt.ylim(0,350)
plt.xlabel('age')
plt.ylabel('wage')
plt.show()
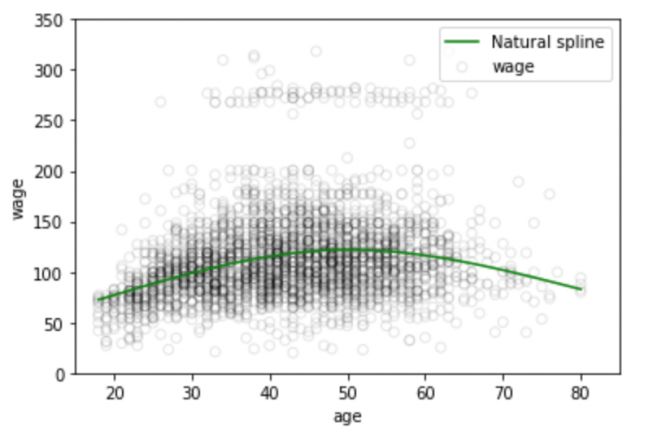
結點的數量和位置
說了這么多,那么當我們擬合樣條時,我們該怎么選擇節點?一種可行的方法是選擇數據分布中的劇烈變化區域作為節點,如經濟現象中的突變時刻——金融危機;第二種方法則是在數據變化復雜的地方多設置節點,在看起來更穩定的地方少設置節點,雖然這樣做能起作用,但一般我們為了簡便還是會截取長度相同的區間。另外,平均分配相同樣本點個數是第三種常用的方法。
這里我們簡要介紹第四種更客觀的做法——交叉驗證。要用這種方法,我們需要:
取走一部分數據;
用一定數量的節點使樣條擬合剩下的這些數據;
用樣條擬合之前取走的數據。
我們重復這個過程,直到每個觀察值被忽略1次,再計算整個交叉驗證的RMSE。它可以針對不同數量的節點重復多次,最后選擇輸出最小RMSE的K值。
回歸樣條與多項式回歸的比較
回歸樣條一般能比多項式回歸得到更好的輸出。因為它與多項式不同,多項式必須要用高次多項式靈活地擬合整個數據集,而回歸樣條在保留非線性函數的靈活性的同時,依靠節點保證了整體的穩定性。
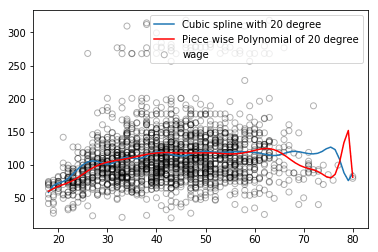
如上圖所示,藍色的回歸樣條曲線整體更平滑,捕捉到的信息也更全面。穩定只是一方面,此外,回歸樣條可以通過控制節點數量調節樣條的靈活性,同時它也能添加線性約束來控制曲線在邊界區域的結果,這使它能更有效地防止過擬合。
小結
寫到這里,本文已接近尾聲。通過這篇文章,我們了解了回歸樣條及其相較于線性回歸和多項式回歸的優勢。在《統計學習入門》中,你還可以進一步學習另一種適用于高度可變數據集的生成樣條方法,稱為平滑樣條。它與Ridge/Lasso正則化類似,懲罰了損失函數和平滑函數。
-
函數
+關注
關注
3文章
4327瀏覽量
62573 -
線性
+關注
關注
0文章
198瀏覽量
25145
原文標題:回歸樣條法(regression splines)簡介
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論