 比谷歌快46倍!GPU助力IBM Snap ML,40億樣本訓練模型僅需91.5秒
比谷歌快46倍!GPU助力IBM Snap ML,40億樣本訓練模型僅需91.5秒
近日,IBM 宣布他們使用一組由 Criteo Labs發布的廣告數據集來訓練邏輯回歸分類器,在POWER9服務器和GPU上運行自身機器學習庫Snap ML,結果比此前來自谷歌的最佳成績快了46倍。
英偉達CEO黃仁勛和IBM 高級副總裁John Kelly在Think大會上
最近,在拉斯維加斯的IBM THINK大會上,IBM宣布,他們利用優化的硬件上的新軟件和算法,取得了AI性能的大突破,包括采用 POWER9 和NVIDIA?V100?GPU 的組合。
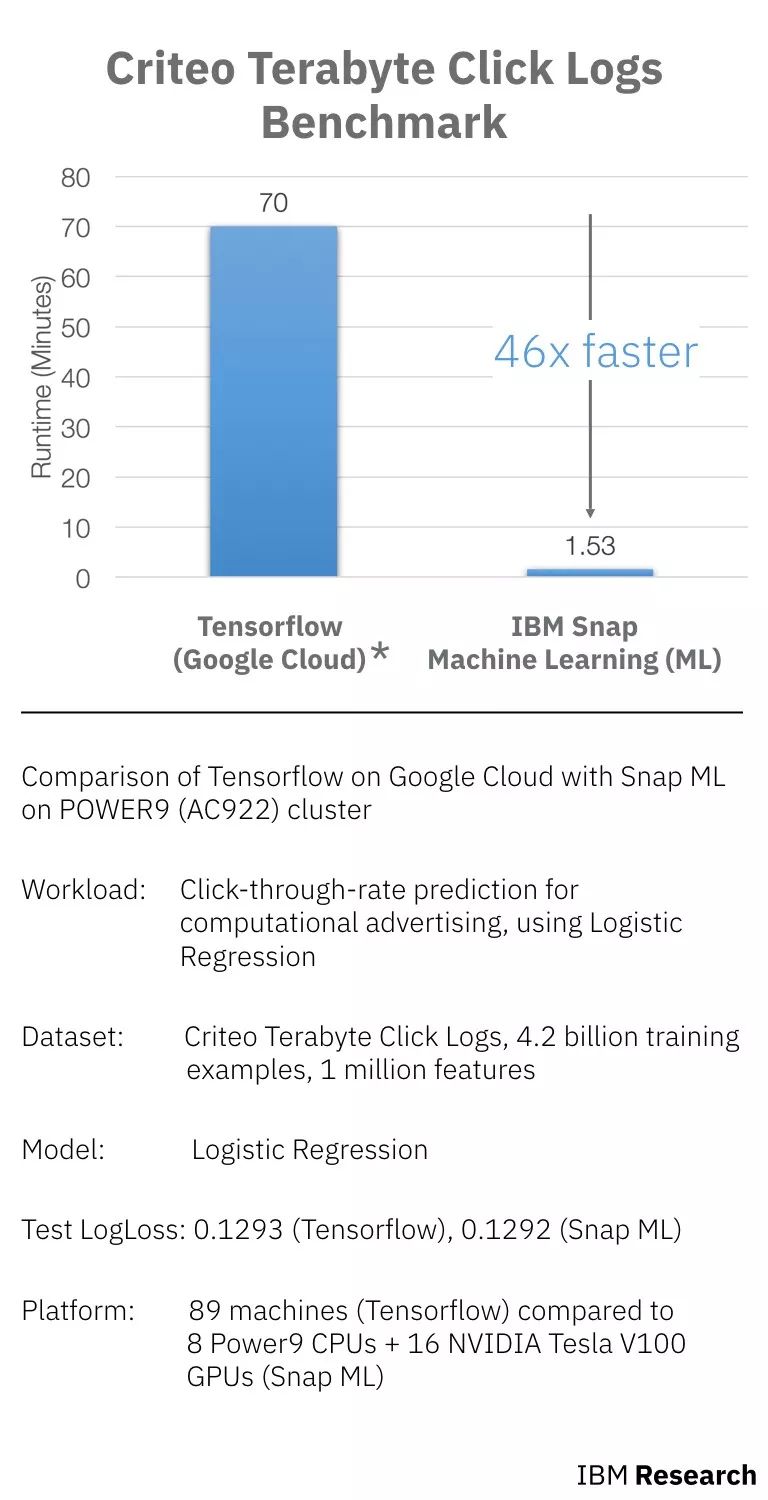
谷歌云上TensorFlow和POWER9 (AC922)cluster上IBM Snap的對比(runtime包含數據加載的時間和訓練的時間)
如上圖所示,workload、數據集和模型都是相同的,對比的是在Google Cloud上使用TensorFlow進行訓練和在Power9上使用Snap ML訓練的時間。其中,TensorFlow使用了89臺機器(60臺工作機和29臺參數機),Snap ML使用了9個 Power9 CPU和16個NVIDIA Tesla V100 GPU。
相比 TensorFlow,Snap ML 獲得相同的損失,但速度快了 46 倍。
怎么實現的?
Snap ML:居然比TensorFlow快46倍
早在去年二月份,谷歌軟件工程師Andreas Sterbenz寫了一篇關于使用谷歌Cloud ML和TensorFlow進行大規模預測廣告和推薦場景的點擊次數的博客。
Sterbenz訓練了一個模型,以預測在Criteo Labs中顯示的廣告點擊量,這些日志大小超過1TB,并包含來自數百萬展示廣告的特征值和點擊反饋。
數據預處理(60分鐘)之后是實際學習,使用60臺工作機和29臺參數機進行培訓。該模型花了70分鐘訓練,評估損失為0.1293。
雖然Sterbenz隨后使用不同的模型來獲得更好的結果,減少了評估損失,但這些都花費更長的時間,最終使用具有三次epochs(度量所有訓練矢量一次用來更新權重的次數)的深度神經網絡,耗時78小時。
但是IBM在POWER9服務器和GPU上運行的自身訓練庫后,可以在基本的初始訓練上勝過谷歌Cloud Platform上的89臺機器。
他們展示了一張顯示Snap ML、Google TensorFlow和其他三個對比結果的圖表:
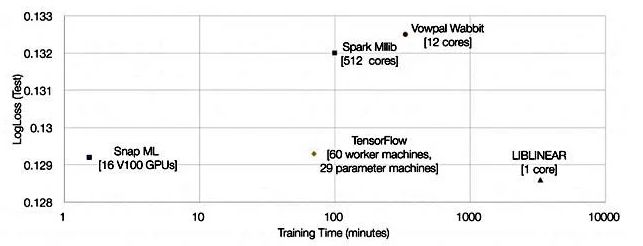
比TensorFlow快46倍,是怎么做到的?
研究人員表示,Snap ML具有多層次的并行性,可以在集群中的不同節點間分配工作負載,利用加速器單元,并利用各個計算單元的多核并行性。
1. 首先,數據分布在集群中的各個工作節點上。
2. 在節點上,數據在CPU和GPU并行運行的主CPU和加速GPU之間分離
3. 數據被發送到GPU中的多個核心,并且CPU工作負載是多線程的
Snap ML具有嵌套的分層算法(nested hierarchical algorithmic)功能,可以利用這三個級別的并行性。
簡而言之,Snap ML的三個核心特點是:
分布式訓練:Snap ML是一個數據并行的框架,能夠在大型數據集上進行擴展和訓練,這些數據集可以超出單臺機器的內存容量,這對大型應用程序至關重要。
GPU加速:實現了專門的求解器,旨在利用GPU的大規模并行架構,同時保持GPU內存中的數據位置,以減少數據傳輸開銷。為了使這種方法具有可擴展性,利用最近異構學習的一些進步,即使可以存儲在加速器內存中的數據只有一小部分,也可以實現GPU加速。
稀疏數據結構:大部分機器學習數據集都是稀疏的,因此在應用于稀疏數據結構,對系統中使用的算法進行了一些新的優化。
技術過程:在91.5秒內實現了0.1292的測試損失
先對Tera-Scale Benchmark設置。
Terabyte Click Logs是由Criteo Labs發布的一個大型在線廣告數據集,用于分布式機器學習領域的研究。它由40億個訓練樣本組成。
其中,每個樣本都有一個“標簽”,即用戶是否點擊在線廣告,以及相應的一組匿名特征。基于這些數據訓練機器學習模型,其目標是預測新用戶是否會點擊廣告。
這個數據集是目前最大的公開數據集之一,數據在24天內收集,平均每天收集1.6億個訓練樣本。
為了訓練完整的Terabyte Click Logs數據集,研究人員在4臺IBM Power System AC922服務器上部署Snap ML。每臺服務器都有4個NVIDIA Tesla V100 GPU和2個Power9 CPU,可通過NVIDIA NVLink接口與主機進行通信。服務器通過Infiniband網絡相互通信。當在這樣的基礎設施上訓練邏輯回歸分類器時,研究人員在91.5秒內實現了0.1292的測試損失。
再來看一遍前文中的圖:
在為這樣的大規模應用部署GPU加速時,出現了一個主要的技術挑戰:訓練數據太大而無法存儲在GPU上可用的存儲器中。因此,在訓練期間,需要有選擇地處理數據并反復移入和移出GPU內存。為了解釋應用程序的運行時間,研究人員分析了在GPU內核中花費的時間與在GPU上復制數據所花費的時間。
在這項研究中,使用Terabyte Clicks Logs的一小部分數據,包括初始的2億個訓練樣本,并比較了兩種硬件配置:
基于Intel x86的機器(Xeon Gold 6150 CPU @ 2.70GHz),帶有1個使用PCI Gen 3接口連接的NVIDIA Tesla V100 GPU。
使用NVLink接口連接4個Tesla V100 GPU的IBM POWER AC922服務器(在比較中,僅使用其中1個GPU)。
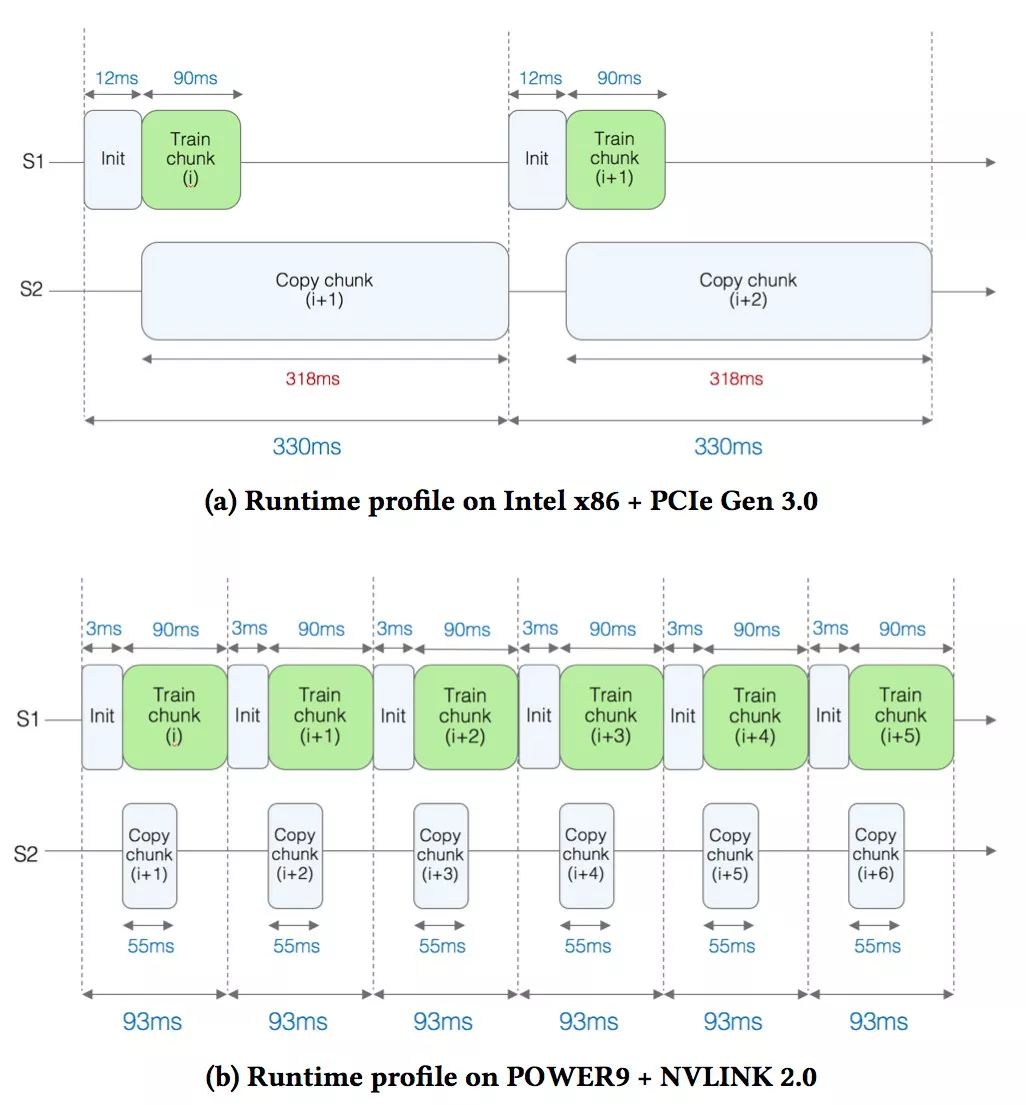
圖a顯示了基于x86的設置的性能分析結果。可以看到S1和S2這兩條線。在S1線上,實際的訓練即將完成時(即,調用邏輯回歸內核)。訓練每個數據塊的時間大約為90毫秒(ms)。
當訓練正在進行時,在S2線上,研究人員將下一個數據塊復制到GPU上。觀察到復制數據需要318毫秒,這意味著GPU閑置了相當長的一段時間,復制數據的時間顯然是一個瓶頸。
在圖b中,對于基于POWER的設置,由于NVIDIA NVLink提供了更快的帶寬,因此下一個數據塊復制到GPU的時間顯著減少到55 ms(幾乎減少了6倍)。這種加速是由于將數據復制時間隱藏在內核執行后面,有效地消除了關鍵路徑上的復制時間,并實現了3.5倍的加速。
IBM的這個機器學習庫提供非常快的訓練速度,可以在現代CPU / GPU計算系統上訓練流主流的機器學習模型,也可用于培訓模型以發現新的有趣模式,或者在有新數據可用時重新訓練現有模型,以保持速度在線速水平(即網絡所能支持的最快速度)。這意味著更低的用戶計算成本,更少的能源消耗,更敏捷的開發和更快的完成時間。
不過,IBM研究人員并沒有聲稱TensorFlow沒有利用并行性,并且也不提供Snap ML和TensorFlow之間的任何比較。
但他們的確說:“我們實施專門的解決方案,來利用GPU的大規模并行架構,同時尊重GPU內存中的數據區域,以避免大量數據傳輸開銷。”
文章稱,采用NVLink 2.0接口的AC922服務器,比采用其Tesla GPU的PCIe接口的Xeon服務器(Xeon Gold 6150 CPU @ 2.70GHz)要更快,PCIe接口是特斯拉GPU的接口。“對于基于PCIe的設置,我們測量的有效帶寬為11.8GB /秒,對于基于NVLink的設置,我們測量的有效帶寬為68.1GB /秒。”
訓練數據被發送到GPU,并在那里被處理。NVLink系統以比PCIe系統快得多的速度向GPU發送數據塊,時間為55ms,而不是318ms。
IBM團隊還表示:“當應用于稀疏數據結構時,我們對系統中使用的算法進行了一些新的優化。”
總的來說,似乎Snap ML可以更多地利用Nvidia GPU,在NVLink上傳輸數據比在x86服務器的PCIe link上更快。但不知道POWER9 CPU與Xeons的速度相比如何,IBM尚未公開發布任何直接POWER9與Xeon SP的比較。
因此也不能說,在相同的硬件配置上運行兩個suckers之前,Snap ML比TensorFlow好得多。
無論是什么原因,46倍的降幅都令人印象深刻,并且給了IBM很大的空間來推動其POWER9服務器作為插入Nvidia GPU,運行Snap ML庫以及進行機器學習的場所。
-
谷歌
+關注
關注
27文章
6161瀏覽量
105303 -
神經網絡
+關注
關注
42文章
4771瀏覽量
100715 -
gpu
+關注
關注
28文章
4729瀏覽量
128890
原文標題:比谷歌快46倍!GPU助力IBM Snap ML,40億樣本訓練模型僅需91.5 秒
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

在Ubuntu上使用Nvidia GPU訓練模型
GPU如何訓練大批量模型?方法在這里
YOLO的另一選擇,手機端97FPS的Anchor-Free目標檢測模型NanoDet
一個GPU訓練一個130億參數的模型





 工商網監
工商網監
評論