 Sentient揭示了人工智能神經進化的突破性研究
Sentient揭示了人工智能神經進化的突破性研究
過去幾年時間里,我們有一個完整的團隊致力于人工智能研究和實驗。該團隊專注于開發新的進化計算方法(EC),包括設計人工神經網絡架構、構建商業應用程序,以及使用由自然進化激發的方法來解決具有挑戰性的計算問題。這一領域的發展勢頭非常強勁。我們相信進化計算很可能是人工智能技術的下一個重大課題。
EC與Deep Learning(DL)一樣都是幾十年前引入的,EC也能夠從可用的計算和大數據中得到提升。然而,它解決了一個截然不同的需求:我們都知道DL側重于建模我們已知的知識,而EC則專注于創建新的知識。從這個意義上講,它是DL的下個步驟:DL能夠在熟悉的類別中識別對象和語音,而EC使我們能夠發現全新的對象和行為-最大化特定目標的對象和行為。因此,EC使許多新的應用成為可能:為機器人和虛擬代理設計更有效的行為,創造更有效和更廉價的衛生干預措施,促進農業機械化發展和生物過程。
前不久,我們發布了5篇論文來報告在這一領域上取得了顯著的進展,報告主要集中在三個方面:(1)DL架構在三個標準機器學習基準測試中已達到了最新技術水平。(2)開發技術用于提高實際應用發展的性能和可靠性。(3)在非常困難的計算問題上證明了進化問題的解決。
本文將重點介紹里面的第一個領域,即用EC優化DL架構。
Sentient揭示了神經進化的突破性研究
深度學習的大部分取決于網絡的規模和復雜性。隨著神經進化,DL體系結構(即網絡拓撲、模塊和超參數)可以在人類能力之外進行優化。我們將在本文中介紹三個示例:Omni Draw、Celeb Match和Music Maker(語言建模)。在這三個例子中,Sentient使用神經進化成功地超越了最先進的DL基準。
音樂制作(語言建模)
在語言建模領域,系統被訓練用來預測“語言庫”中的下一個單詞,例如《華爾街日報》幾年內的大量文本集合,在網絡做出預測結果后,這個輸入還可以被循環輸入,從而網絡可以生成一個完整的單詞序列。有趣的是,同樣的技術同樣適用于音樂序列,以下為一個演示。用戶輸入一些初始音符,然后系統根據該起始點即興創作一首完整的旋律。通過神經元進化,Sentient優化了門控周期性(長期短期記憶或LSTM)節點(即網絡的“記憶”結構)的設計,使模型在預測下一個音符時更加準確。
在語言建模領域(在一個叫Penn Tree Bank的語言語料庫中預測下一個詞),基準是由困惑點定義的,用來度量概率模型如何預測真實樣本。當然,數字越低越好,因為我們希望模型在預測下一個單詞時“困惑”越少越好。在這種情況下,感知器以10.8的困惑點擊敗了標準的LSTM結構。值得注意的是,在過去25年內,盡管人類設計了一些LSTM變體,LSTM的性能仍然沒有得到改善。事實上,我們的神經進化實驗表明,LSTM可以通過增加復雜性,即記憶細胞和更多的非線性、平行的途徑來顯著改善性能。
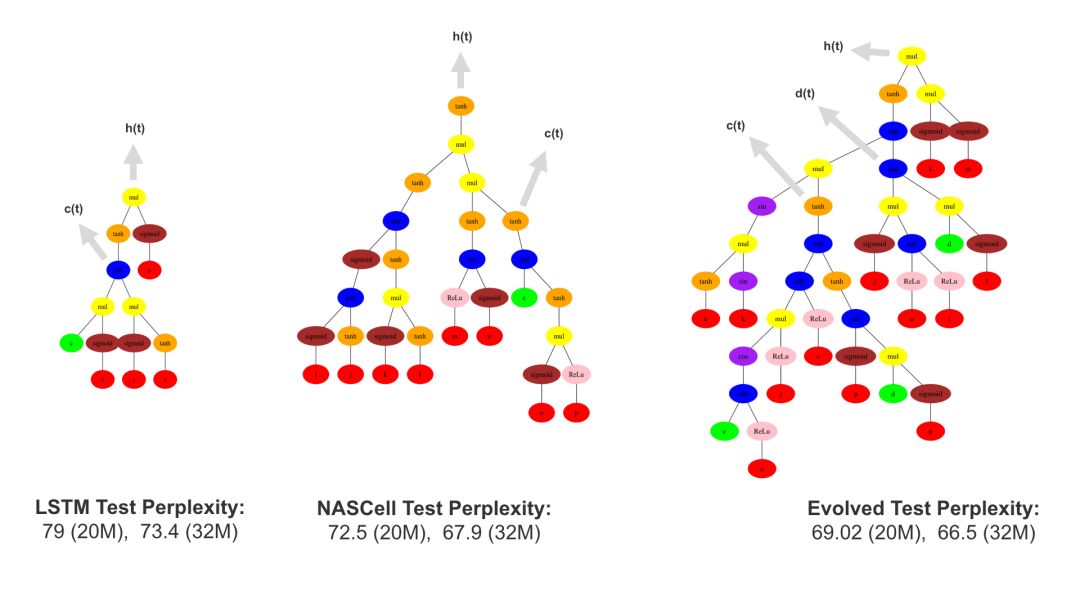
為什么這個突破很重要?語言是人類強大而復雜的智能構造。語言建模,即預測文本中的下一個單詞,是衡量機器學習方法如何學習語言結構的基準。因此,它是構建自然語言處理系統的代理,包括語音和語言接口、機器翻譯,甚至包括DNA序列和心率診斷等醫學數據。而在語言建模基準測試中我們可以做得更好,可以使用相同的技術建立更好的語言處理系統。
Omni Draw
Omniglot是一種可以識別50種不同字母字符的手寫字符識別基準,包括像西里爾語(書面俄語)、日語和希伯來語等真實語言,以及諸如Tengwar(《指環王》中的書面語言)等人工語音。
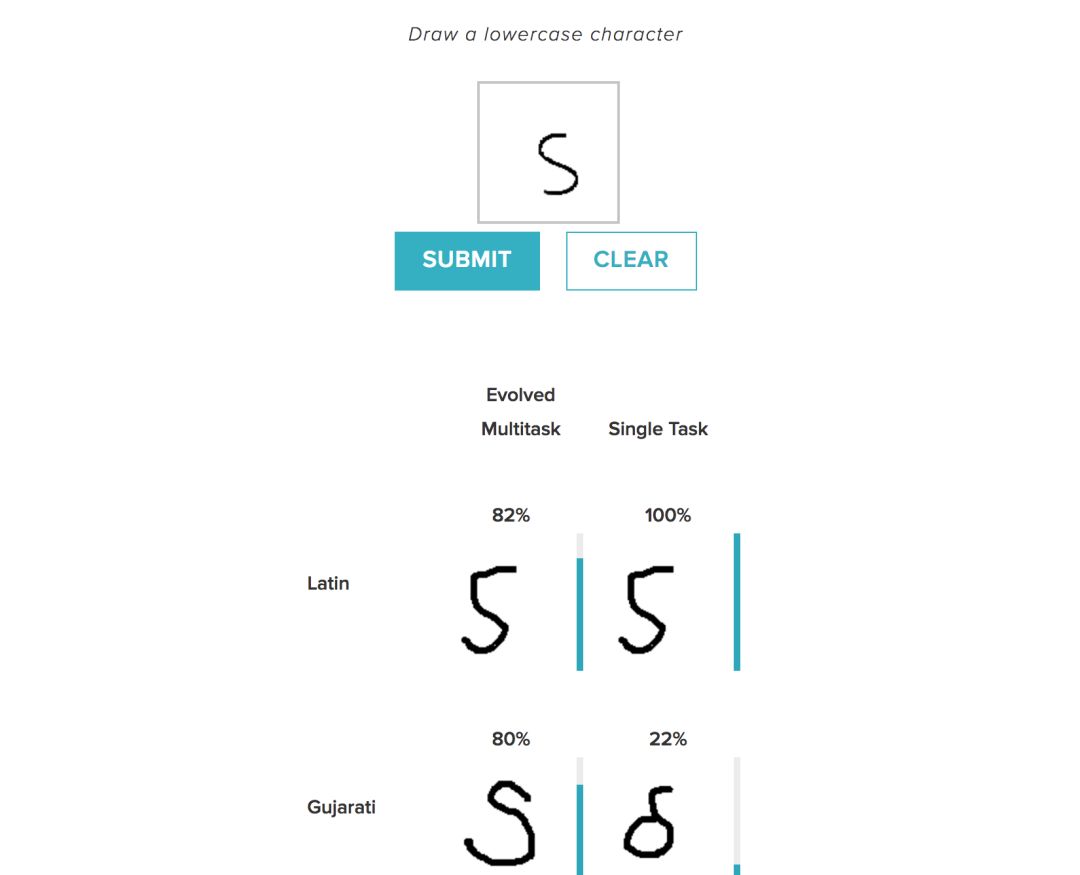
上圖示例展示了多任務學習,模型可以同時學習所有語言,并利用不同語言中字符之間的關系。例如,用戶輸入圖像,系統根據匹配輸出不同語言的含義,“這將是拉丁語中的X,日語中的Y以及Tengwar中的Z等等”——利用日本、Tengwar和拉丁語之間的關系找出哪些角色是最好的匹配。這與單一任務學習環境不同,單一環境下模型只對一種語言進行訓練,并且不能在語言數據集上建立相同的連接。
雖然Omniglot是一個數據集的例子,但每個語言的數據相對較少。例如它可能只有幾個希臘字母,但很多都是日語。它能夠利用語言之間關系的知識來尋找解決方案。為什么這個很重要?對于許多實際應用程序來說,標記數據的獲取是非常昂貴或危險的(例如醫療應用程序、農業和機器人救援),因此可以利用與相似或相關數據集的關系自動設計模型,在某種程度上可以替代丟失的數據集并提高研究能力。這也是神經進化能力的一個很好的證明:語言之間可以有很多的聯系方式,并且進化發現了將他們的學習結合在一起的最佳方式。
Celeb Match
Celeb Match的demo同樣適用于多任務學習,但它使用的是大規模數據集。該demo是基于CelebA數據集,它由約20萬張名人圖像組成,每張圖片的標簽都由40個二進制標記屬性,如“男性與女性”、“有無胡子”等等。每個屬性都會產生一個“分類任務”,它會引導系統檢測和識別每個屬性。作為趣味附加組件,我們創建了一個demo來完成這項任務:用戶可以為每個屬性設置所需的程度,并且系統會根據進化的多任務學習網絡來確定最接近的名人。例如,如果當前的圖片為布拉德·皮特的形象,用戶可以增加“灰色頭發”屬性,已發現哪個名人與他相似但是頭發不同。
在CelebA多任務人臉分類領域,Sentient使用了演化計算來優化這些檢測屬性的網絡,成功將總體三個模型的誤差從8%降到了7.94%。
這一技術使得人工智能在預測人類、地點和物質世界各種屬性的能力上提升了一大步。與基于抽象,學習功能找到相似性的訓練網絡不同,它使相似的語義和可解釋性也成為可能。
-
人工智能
+關注
關注
1791文章
47183瀏覽量
238264 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:推薦!神經進化才是深度學習未來的發展之路!
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論