 Linux內核的連續內存分配器(CMA)——避免預留大塊內存
Linux內核的連續內存分配器(CMA)——避免預留大塊內存
這是我2012年上半年寫的文章,現在微信公眾號再次發表。
在我們使用ARM等嵌入式Linux系統的時候,一個頭疼的問題是GPU,Camera,HDMI等都需要預留大量連續內存,這部分內存平時不用, 但是一般的做法又必須先預留著。目前,Marek Szyprowski和Michal Nazarewicz實現了一套全新的Contiguous Memory Allocator。通過這套機制,我們可以做到不預留內存,這些內存平時是可用的,只有當需要的時候才被分配給Camera,HDMI等設備。下面分析 它的基本代碼流程。
聲明連續內存
內核啟動過程中arch/arm/mm/init.c中的arm_memblock_init()會調用dma_contiguous_reserve(min(arm_dma_limit, arm_lowmem_limit));
該函數位于:drivers/base/dma-contiguous.c
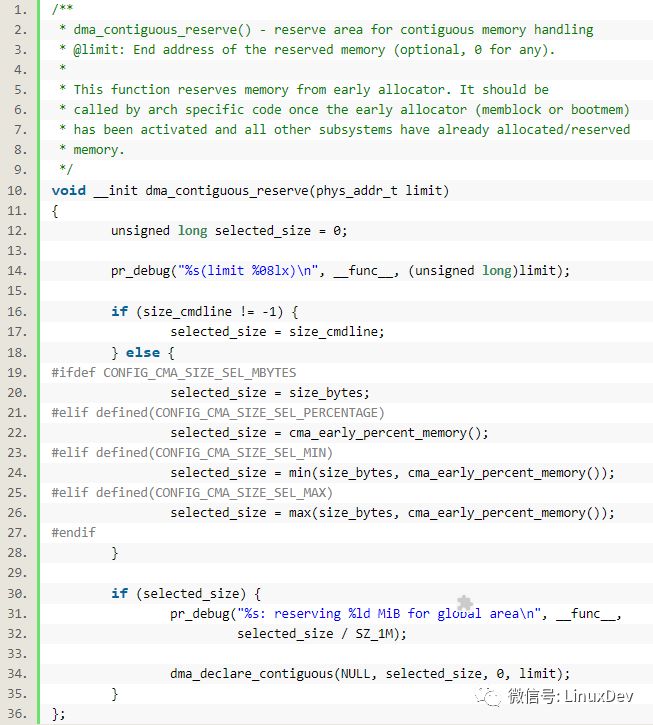
其中的size_bytes定義為:
static const unsigned long size_bytes = CMA_SIZE_MBYTES * SZ_1M; 默認情況下,CMA_SIZE_MBYTES會被定義為16MB,來源于CONFIG_CMA_SIZE_MBYTES=16->
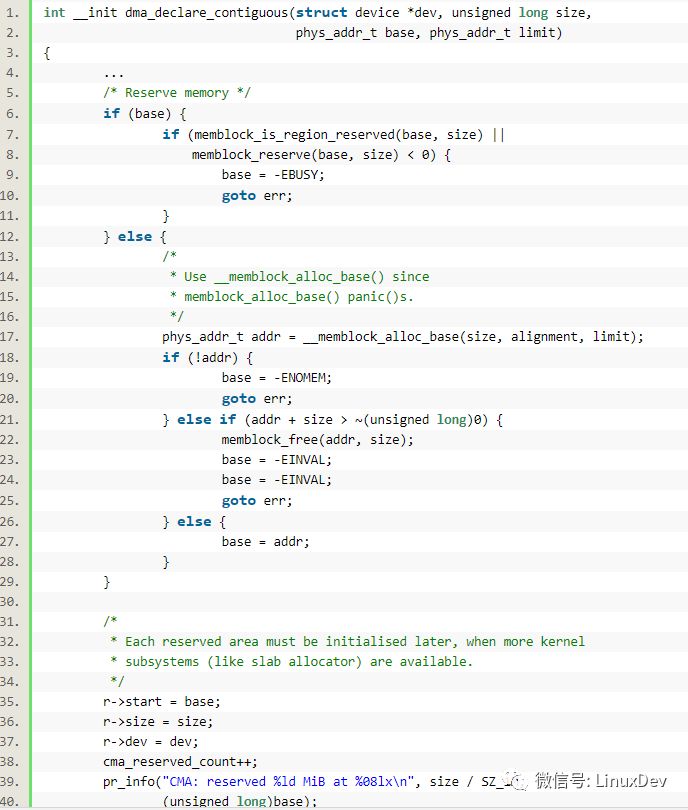
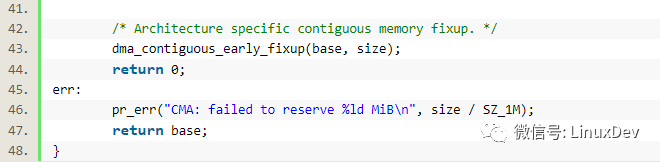
由此可見,連續內存區域也是在內核啟動的早期,通過__memblock_alloc_base()拿到的。
另外:
drivers/base/dma-contiguous.c里面的core_initcall()會導致cma_init_reserved_areas()被調用:
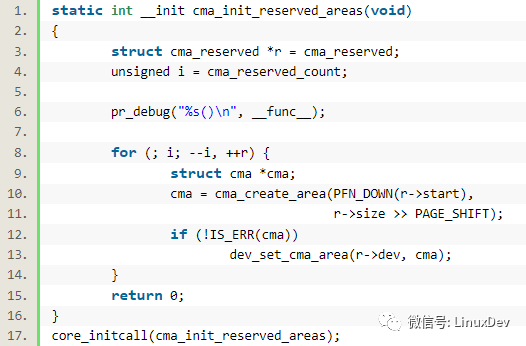
cma_create_area()會調用cma_activate_area(),cma_activate_area()函數則會針對每個page調用:
init_cma_reserved_pageblock(pfn_to_page(base_pfn));
這個函數則會通過set_pageblock_migratetype(page, MIGRATE_CMA)將頁設置為MIGRATE_CMA類型的:
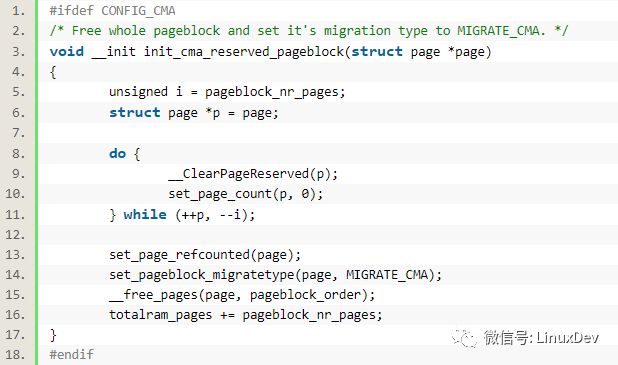
同時其中調用的__free_pages(page, pageblock_order);最終會調用到__free_one_page(page, zone, order, migratetype);相關的page會被加到MIGRATE_CMA的free_list上面去:
list_add(&page->lru, &zone->free_area[order].free_list[migratetype]);
申請連續內存
申請連續內存仍然使用標準的arch/arm/mm/dma-mapping.c中定義的dma_alloc_coherent()和dma_alloc_writecombine(),這二者會間接調用drivers/base/dma-contiguous.c中的

->
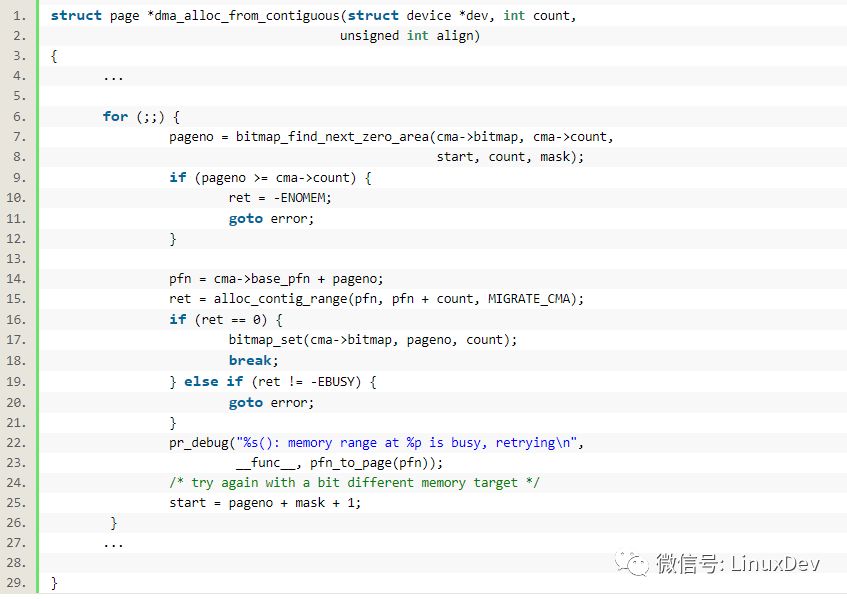
->
int alloc_contig_range(unsigned long start, unsigned long end,
unsigned migratetype)
需要隔離page,隔離page的作用通過代碼的注釋可以體現:
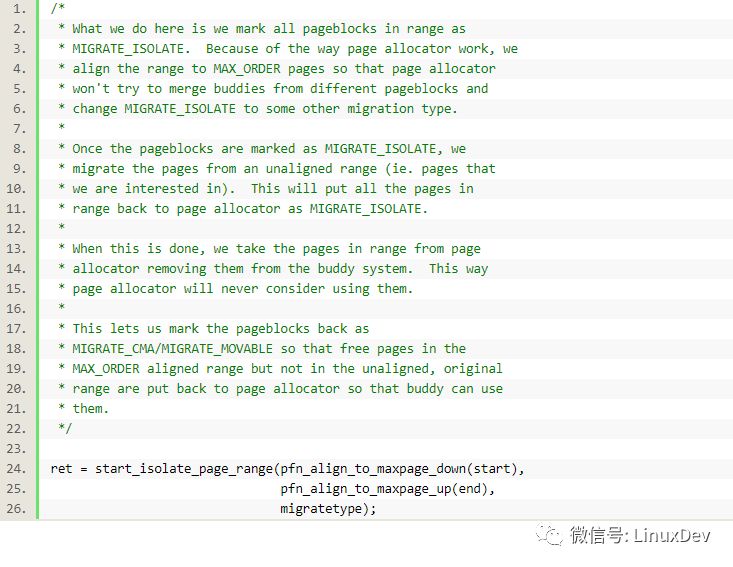
簡單地說,就是把相關的page標記為MIGRATE_ISOLATE,這樣buddy系統就不會再使用他們。

接下來調用__alloc_contig_migrate_range()進行頁面隔離和遷移:

其中的函數migrate_pages()會完成頁面的遷移,遷移過程中通過傳入的__alloc_contig_migrate_alloc()申請新的page,并將老的page付給新的page:
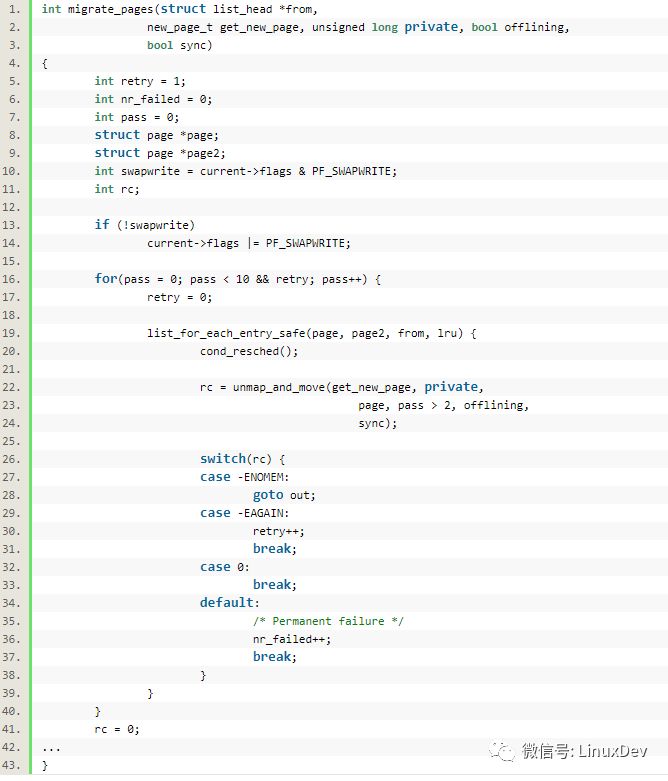
其中的unmap_and_move()函數較為關鍵,它定義在mm/migrate.c中
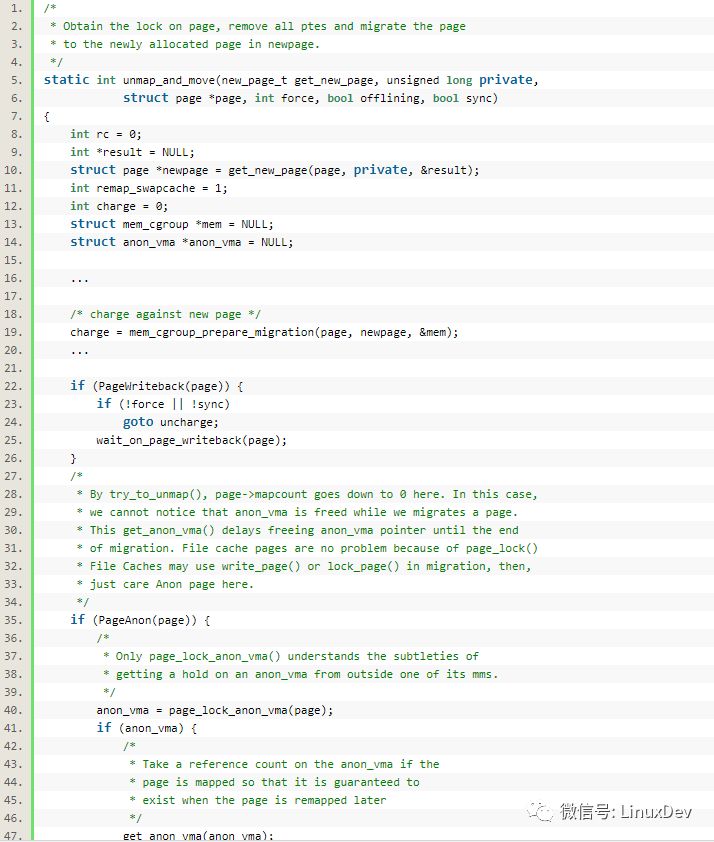
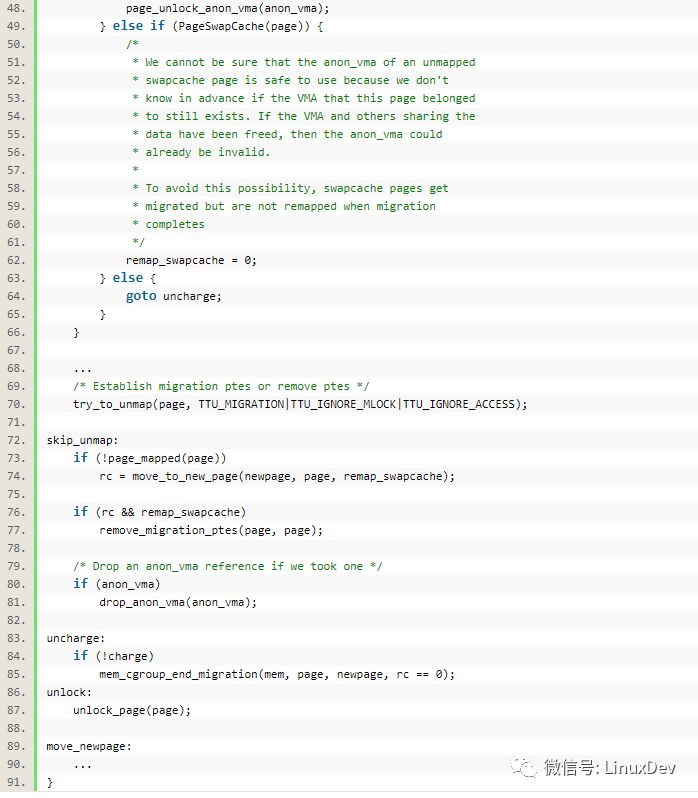
通過unmap_and_move(),老的page就被遷移過去新的page。
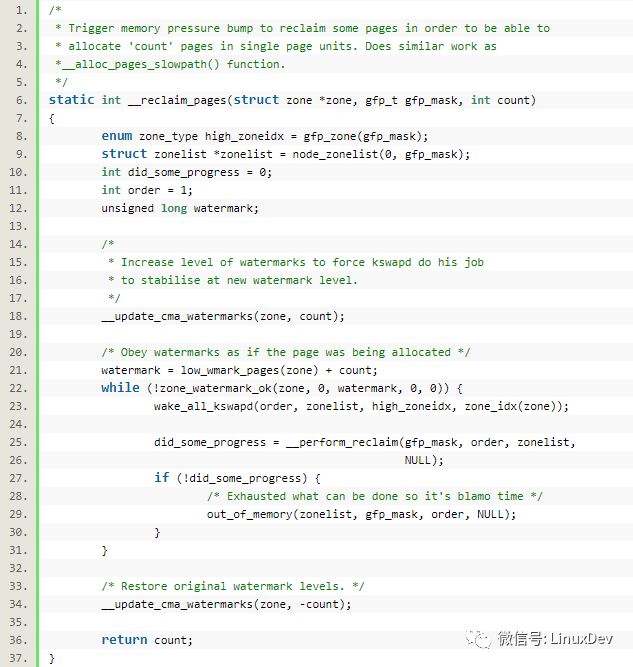
接下來要回收page,回收page的作用是,不至于因為拿了連續的內存后,系統變得內存饑餓:
->

->
釋放連續內存
內存釋放的時候也比較簡單,直接就是:
arch/arm/mm/dma-mapping.c:
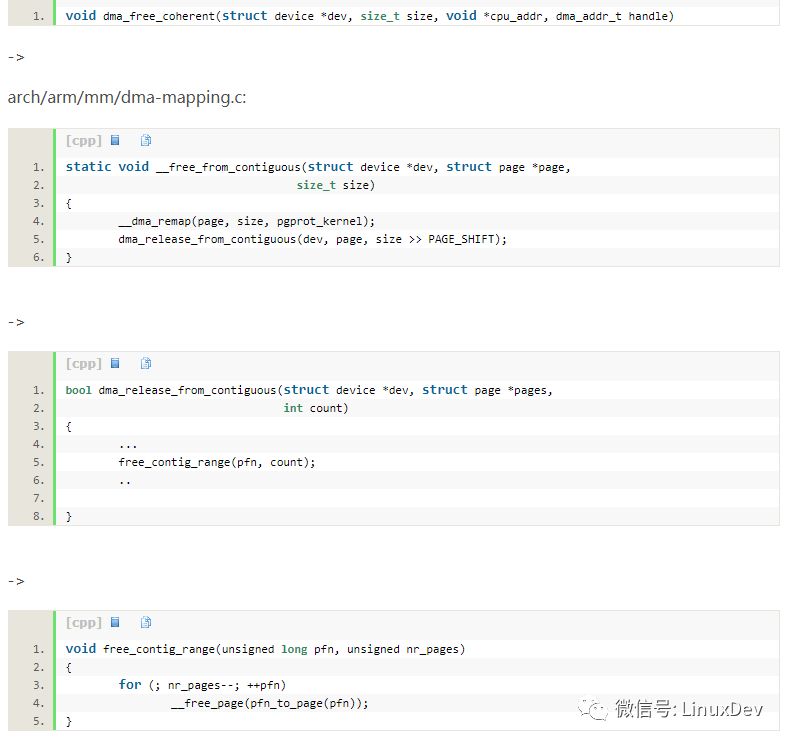
將page交還給buddy。
內核內存分配的migratetype
內核內存分配的時候,帶的標志是GFP_,但是GFP_可以轉化為migratetype:
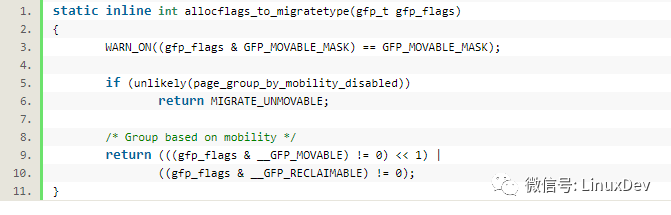
之后申請內存的時候,會對比遷移類型匹配的free_list:

另外,筆者也編寫了一個測試程序,透過它隨時測試CMA的功能:
/*
* kernel module helper for testing CMA
*
* Licensed under GPLv2 or later.
*/
#include
#include
#include
#include
#include
#define CMA_NUM 10
static struct device *cma_dev;
static dma_addr_t dma_phys[CMA_NUM];
static void *dma_virt[CMA_NUM];
/* any read request will free coherent memory, eg.
* cat /dev/cma_test
*/
static ssize_t
cma_test_read(struct file *file, char __user *buf, size_t count, loff_t *ppos)
{
int i;
for (i = 0; i < CMA_NUM; i++) {??
if (dma_virt[i]) {
dma_free_coherent(cma_dev, (i + 1) * SZ_1M, dma_virt[i], dma_phys[i]);
_dev_info(cma_dev, "free virt: %p phys: %p\n", dma_virt[i], (void *)dma_phys[i]);
dma_virt[i] = NULL;
break;
}
}
return 0;
}
/*
* any write request will alloc coherent memory, eg.
* echo 0 > /dev/cma_test
*/
static ssize_t
cma_test_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos)
{
int i;
int ret;
for (i = 0; i < CMA_NUM; i++) {??
if (!dma_virt[i]) {
dma_virt[i] = dma_alloc_coherent(cma_dev, (i + 1) * SZ_1M, &dma_phys[i], GFP_KERNEL);
if (dma_virt[i]) {
void *p;
/* touch every page in the allocated memory */
for (p = dma_virt[i]; p
*(u32 *)p = 0;
_dev_info(cma_dev, "alloc virt: %p phys: %p\n", dma_virt[i], (void *)dma_phys[i]);
} else {
dev_err(cma_dev, "no mem in CMA area\n");
ret = -ENOMEM;
}
break;
}
}
return count;
}
static const struct file_operations cma_test_fops = {
.owner = THIS_MODULE,
.read = cma_test_read,
.write = cma_test_write,
};
static struct miscdevice cma_test_misc = {
.name = "cma_test",
.fops = &cma_test_fops,
};
static int __init cma_test_init(void)
{
int ret = 0;
ret = misc_register(&cma_test_misc);
if (unlikely(ret)) {
pr_err("failed to register cma test misc device!\n");
return ret;
}
cma_dev = cma_test_misc.this_device;
cma_dev->coherent_dma_mask = ~0;
_dev_info(cma_dev, "registered.\n");
return ret;
}
module_init(cma_test_init);
static void __exit cma_test_exit(void)
{
misc_deregister(&cma_test_misc);
}
module_exit(cma_test_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Barry Song <21cnbao@gmail.com>");
MODULE_DESCRIPTION("kernel module to help the test of CMA");
MODULE_ALIAS("CMA test");
申請內存:
#echo0>/dev/cma_test
釋放內存:
#cat/dev/cma_test
-
Linux
+關注
關注
87文章
11322瀏覽量
209869 -
分配器
+關注
關注
0文章
194瀏覽量
25778
原文標題:宋寶華:Linux內核的連續內存分配器(CMA)——避免預留大塊內存
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Linux內核內存規整總結

Linux內核內存管理之內核非連續物理內存分配
Linux內存系統: Linux 內存分配算法
深入剖析SLUB分配器和SLAB分配器的區別






 工商網監
工商網監
評論