 機器學習:三張拉面圖,就能識別出每碗拉面在哪家出品
機器學習:三張拉面圖,就能識別出每碗拉面在哪家出品
只要三張拉面圖,就能識別出每碗拉面是在41家不同拉面店中的哪家制作出來。數據科學家Kenji Doi開發了一種拉面專家AI分類器,它能辨別出不同拉面之間的細微差異。這背后,是谷歌AutoML Vision提供的ML模型。
看下面的三碗拉面。你能相信機器學習(ML)模型能以95%的準確率識別出每碗拉面是在41家拉面店中的哪家制作的么?數據科學家Kenji Doi開發了一種拉面專家AI分類器,它能辨別出不同拉面之間的細微差異。
拉面Jiro是日本最受歡迎的連鎖餐廳之一,因為它的配料、面條和湯的價格都很便宜。這個連鎖餐廳在東京有41家分店,每家店都有基本相同的菜單。
正如你在照片中所看到的,對于一個剛剛接觸拉面的人來說,幾乎不可能知道每碗面的制作材料是什么,因為它們看起來幾乎是一樣的。你不相信自己可以通過看這些照片來辨別這些面到底屬于41家餐館的哪一家。
Kenji想知道深度學習是否能幫助解決這個問題。他從網絡上收集了48,244張Jiro做的拉面的圖片。在刪除了不適合進行模型訓練的照片之后(比如重復照片或沒有拉面的照片),他為每個餐館準備了大約1,170張照片,也就是48000張帶有商店標簽的照片。
AutoML Vision達到了94.5%的準確率
當Kenji正在研究這個問題時,他了解到Google剛剛發布了AutoML Vision的alpha版本。
AutoML Vision允許用戶在不具備設計ML模型的專業知識的情況下使用自己的圖像定制ML模型。首先,你要做的就是上傳圖像文件進行模型訓練,并確保上傳數據具有正確的標簽。一旦完成了定制模型的訓練,您就可以輕松地將其應用到到可擴展的服務平臺上,以便通過自動擴展擁有的資源來滿足實際需求。整個過程是為那些不具備專業ML知識的非數據科學家設計的。
AutoML Vision訓練、部署和服務自定義ML模型的過程
當Kenji獲得了AutoML Vision的alpha版本后,他試了一下。他發現用帶有商店標簽的拉面照片作為數據集訓練模型時,F值可以達到94.5%,其中精確率未94.8%,召回率為94.5%。
使用AutoML Vision(高級模式)的拉面店分類器的混淆矩陣(行=實際店鋪,欄=預測店鋪)
通過觀察上圖的混淆矩陣,您可以看到AutoML Vision在每個測試樣例中,僅僅對幾個樣本做出了錯誤的分類。
這怎么可能?每個照片使用AutoML檢測區別是什么?Kenji想知道ML模型如何能準確地識別出拉面對應的商店。起初,他認為模型是在看碗,或桌子的顏色或形狀。但是,正如你在上面的照片中所看到的,即使每個商店在他們的照片中使用了相同的碗和桌子設計,這個模型也非常準確。Kenji的新理論是,該模型精確地能夠區分肉塊和澆頭的細微差別。他計劃繼續在AutoML上做實驗,看看他的理論是否正確。
數據科學的自動化技術
在嘗試AutoML Vision之前,Kenji花了相當多的時間來為他的拉面分類項目建立自己的ML模型。他仔細地選擇了一個通過Inception,ResNetSE-ResNeXt獲得的一個集合模型,構建了一個數據增強設置,在超參數調優上耗費了很長的時間,如改變學習率等,并引入他積累的知識作為一個專家知識。
但是,通過AutoML Vision,Kenji發現他唯一需要做的就是上傳圖片并點擊“訓練”按鈕,僅此而已。通過AutoML Vision,他不費吹灰之力就能夠訓練一個ML模型。
標記圖像集的示例。借助AutoML Vision,您只需上傳帶有標簽的圖像即可開始使用
當使用AutoML Vision訓練一個模型時,有兩種模式任你選擇:基本模式或高級模式。在基本模式下,AutoML Vision可以在18分鐘之內完成Kenji的訓練數據。在高級模式下用了將近24個小時。在這兩種情況下,他都沒有執行任何超參數調優、數據擴充或嘗試不同的ML模型類型。一切都是自動化處理,不需要擁有相關的專業知識。
據Kenji說,“在基本模式下無法獲得最優的準確性,但是可以在很短的時間內得到一個粗略的結果。而高級模式可以在用戶不進行任何優化或具備任何學習技能的情況下獲得最優的精度。這樣看來,這個工具肯定會提高數據科學家的生產力。數據科學家們已經為我們的客戶進行了太多的人工智能解答,因此,我們必須盡快將深度學習應用到PoCs上。有了AutoML Vision,數據科學家就不需要為了獲得最優的模型結果花很長時間來培訓和優化模型獲。這意味著即使只有擁有限數量的數據科學家,企業也可以擴大他們的人工智能產業。”
他喜歡AutoML Vision還有因為其另外一個特點:“AutoML Vision太酷了,你可以在訓練后使用它的在線預測功能。而這項任務對于數據科學家來說通常是特別耗時的,因為必須要將模型部署到生產服務環境中后,再對其進行管理。”
AutoML Vision在另一個不同的用例中也證明了它的能力:對產品進行品牌分類。Mercari是日本最受歡迎的銷售APP之一,它在美國也受到越來越多人的青睞,它一直在嘗試通過閃頻的圖片自動識別其品牌。
Mercari官網
在日本,Mercari推出了一款名為Mercari MAISONZ的新App,用于銷售品牌商品。Mercari在這款應用中開發了自己的ML模型,在用戶的圖片上傳界面中,該模型可以對12個主要品牌的商品進行分類。該模型使用了VGG16在TensorFlow上的遷移學習,準確率達到75%。

正如ML模型預測的那樣,用戶上傳圖片界面顯示了品牌名稱
而當Mercari在AutoML Vision的高級模式下嘗試用5000個訓練來進行訓練,它達到了91.3%的準確率。這比他們現有的模型高出了15%。
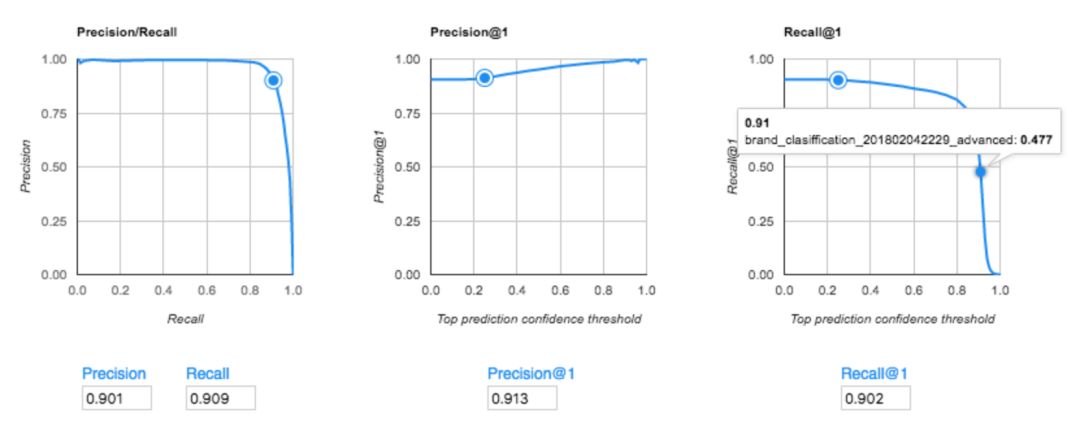
Mercari的AutoML Vision模型(高級模式)的準確性分數(精確度/召回率)
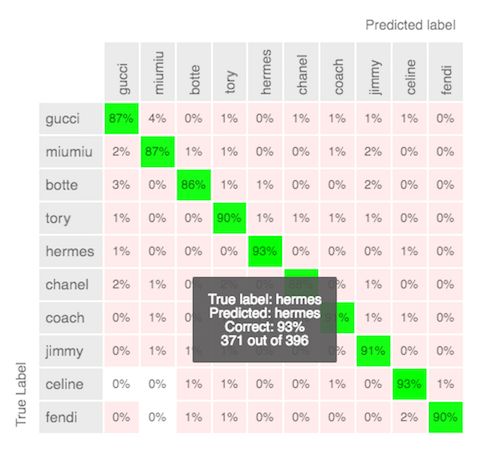
Mercari的AutoML Vision模型的混淆矩陣(高級模式)
對AutoML Vision的近距離觀察
Mercari的數據科學家Shuhei Fujiwara對這個結果感到非常驚訝,他說:“我無法想象谷歌是如何做到如此高精度的!”
用于大規模圖像分類和對象檢測的AutoML
高級模式里面,除了轉移學習還有什么呢?實際上,其中還包括谷歌的學習技術,特別是NASNet。
NASNet使用ML來優化ML:元級ML模型試圖為特定的訓練數據集獲得最佳的深度學習模型。這才是高級模式的秘密,它代表了谷歌的“人工智能”哲學。這項技術可以讓用戶在不用長時間學習人工智能的情況下,充分地利用最先進的深度學習能力。
Shuhei還很喜歡這項服務的用戶界面。“它很容易使用,你不需要對超參數優化做任何的人工處理,而且在UI上的一個混淆矩陣也為用戶來帶了方便,因為它可以幫助用戶快速檢查模型的準確性。該服務還允許你將最耗時的人工標記工作交給谷歌。因此,我們正在等待公測版本取代現有的自動化版本,這樣就可以將其部署到生產環境中了。”
-
谷歌
+關注
關注
27文章
6161瀏覽量
105304 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238265 -
機器學習
+關注
關注
66文章
8406瀏覽量
132567
原文標題:【谷歌云AutoML Vision官方教程】手把手教會訓練模型解決計算機視覺問題,準確率達94.5%
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ASR和機器學習的關系
什么是機器學習?通過機器學習方法能解決哪些問題?

用EDA做了一張校園卡但是發現學校大門刷不進去,學校內充當飯卡時能正常識別,不知道哪里出問題了
人工智能、機器學習和深度學習是什么
深度學習與傳統機器學習的對比
特斯拉面臨庫存危機
圖機器學習入門:基本概念介紹
機器學習怎么進入人工智能
基于CYUSB3014做了一塊USB3.0的開發板,怎么樣能讓FX3被識別出USB3.0呢?
特斯拉面臨4680電池生產挑戰
什么是機器學習?它的重要性體現在哪





 工商網監
工商網監
評論