


尋找并分析百度云的轉存api
首先你得有一個百度云盤的賬號,然后登錄,用瀏覽器(這里用火狐瀏覽器做示范)打開一個分享鏈接。F12打開控制臺進行抓包。手動進行轉存操作:全選文件->保存到網盤->選擇路徑->確定。點擊【確定】前建議先清空一下抓包記錄,這樣可以精確定位到轉存的api,這就是我們中學時學到的【控制變量法】2333。
可以看到上圖中抓到了一個帶有 “transfer” 單詞的 post 請求,這就是我們要找的轉存(transfer)api 。接下來很關鍵,就是分析它的請求頭和請求參數,以便用代碼模擬。

點擊它,再點擊右邊的【Cookies】就可以看到請求頭里的 cookie 情況。
cookie分析
因為轉存是登錄后的操作,所以需要模擬登錄狀態,將與登錄有關的 cookie 設置在請求頭里。我們繼續使用【控制變量法】,先將瀏覽器里關于百度的 cookie 全部刪除(在右上角的設置里面,點擊【隱私】,移除cookies。具體做法自己百度吧。)
然后登錄,右上角進入瀏覽器設置->隱私->移除cookie,搜索 "bai" 觀察 cookie 。這是所有跟百度相關的 cookie ,一個個刪除,刪一個刷新一次百度的頁面,直到刪除了 BDUSS ,刷新后登錄退出了,所以得出結論,它就是與登錄狀態有關的 cookie 。
同理,刪除掉 STOKEN 后,進行轉存操作會提示重新登錄。所以,這兩個就是轉存操作所必須帶上的 cookie 。
弄清楚了 cookie 的情況,可以像下面這樣構造請求頭。
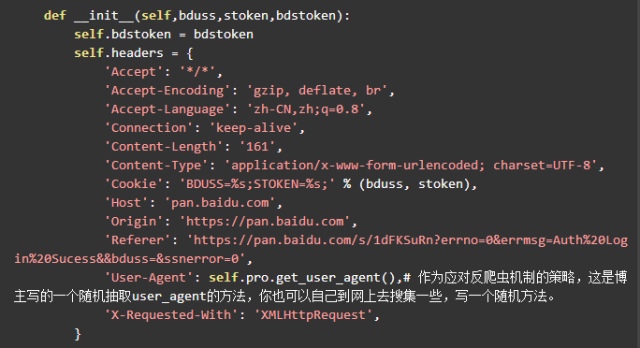
除了上面說到的兩個 cookie ,其他的請求頭參數可以參照手動轉存時抓包的請求頭。這兩個 cookie 預留出來做參數的原因是 cookie 都是有生存周期的,過期了需要更新,不同的賬號登錄也有不同的 cookie 。
參數分析
接下來分析參數,點擊【Cookies】右邊的【Params】查看參數情況。如下:
上面的query string(也就是?后跟的參數)里,除了框起來的shareid、from、bdstoken需要我們填寫以外,其他的都可以不變,模擬請求的時候直接抄下來。
前兩個與分享的資源有關,bdstoken與登錄的賬號有關。下面的form data里的兩個參數分別是資源在分享用戶的網盤的所在目錄和剛剛我們點擊保存指定的目錄。
所以,需要我們另外填寫的參數為:shareid、from、bdstoken、filelist 和 path,bdstoken 可以手動轉存抓包找到,path 根據你的需要自己定義,前提是你的網盤里有這個路徑。其他三個需要從分享鏈接里爬取,這個將在后面的【爬取shareid、from、filelist,發送請求轉存到網盤】部分中進行講解。
搞清楚了參數的問題,可以像下面這樣構造轉存請求的 url 。
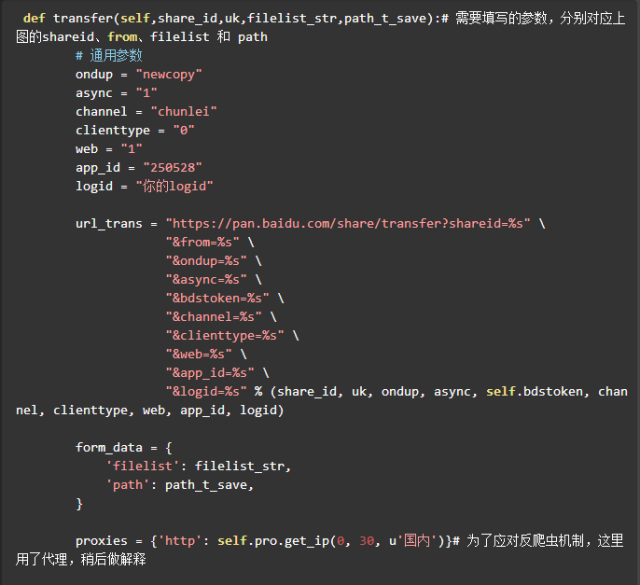
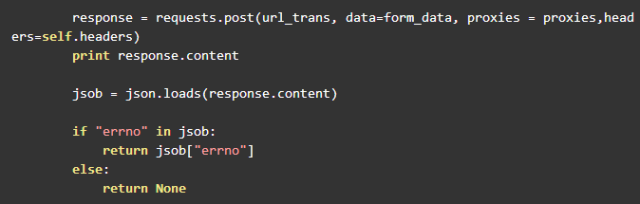
爬取shareid、from、filelist,發送請求轉存到網盤

以上面這個資源鏈接為例(隨時可能被河蟹,但是沒關系,其他鏈接的結構也是一樣的),我們先用瀏覽器手動訪問,F12 打開控制臺先分析一下源碼,看看我們要的資源信息在什么地方。控制臺有搜索功能,直接搜 “shareid”。
定位到4個shareid,前三個與該資源無關,是其他分享資源,最后一個定位到該 html 文件的最后一個標簽塊里。雙擊后可以看到格式化后的 js 代碼,可以發現我們要的信息全都在里邊。如下節選:
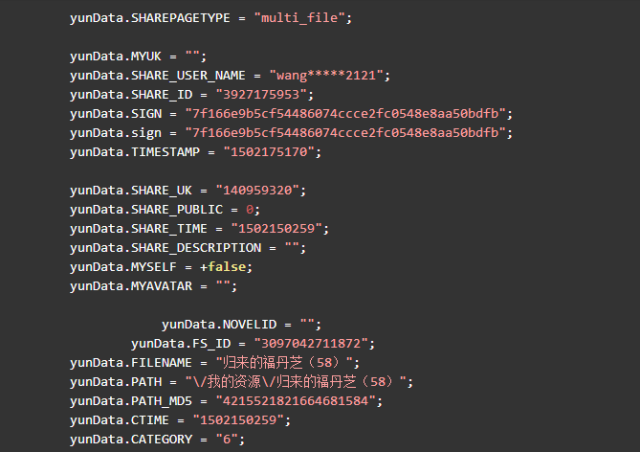
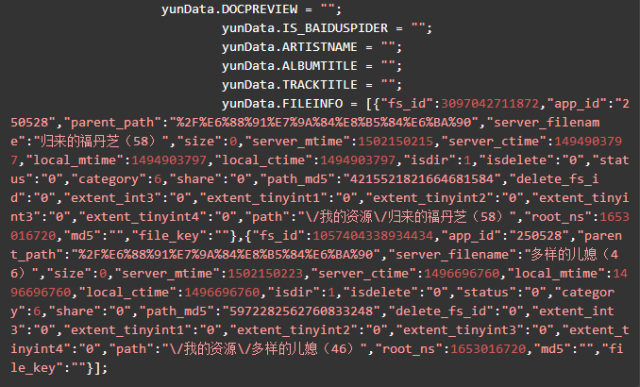
可以看到這兩行

yunData.PATH 只指向了一個路徑信息,完整的 filelist 可以從 yunData.FILEINFO 里提取,它是一個 json ,list 里的信息是Unicode編碼的,所以在控制臺看不到中文,用Python代碼訪問并獲取輸出一下就可以了。
直接用request請求會收獲 404 錯誤,可能是需要構造請求頭參數,不能直接請求,這里博主為了節省時間,直接用selenium的webdriver來get了兩次,就收到了返回信息。第一次get沒有任何 cookie ,但是baidu 會給你返回一個BAIDUID ,在第二次 get 就可以正常訪問了。
yunData.FILEINFO 結構如下,你可以將它復制粘貼到json.cn里,可以看得更清晰。
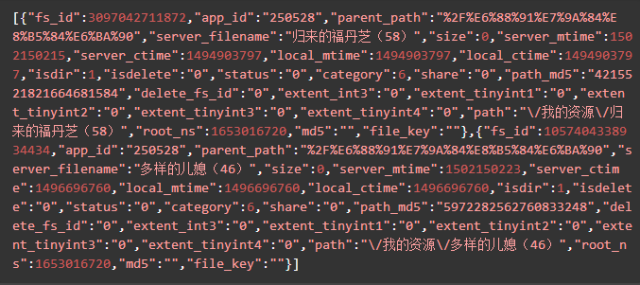
清楚了這三個參數的位置,我們就可以用正則表達式進行提取了。代碼如下:
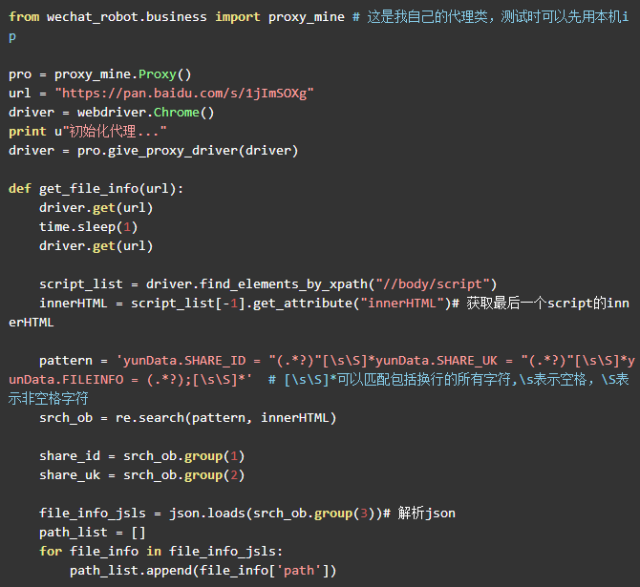
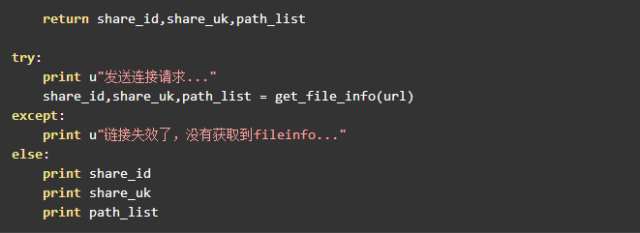
爬取到了這三個參數,就可以調用之前的 transfer 方法進行轉存了。
-
python
+關注
關注
56文章
4828瀏覽量
87052 -
百度云
+關注
關注
0文章
56瀏覽量
8190
原文標題:Python爬蟲實戰:抓取并保存百度云資源(附代碼)
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
百度地圖離線API調用教程
Python數據爬蟲學習內容
Python爬蟲初學者需要準備什么?
0基礎入門Python爬蟲實戰課
百度API調用(三)——語音識別 精選資料推薦
基于互聯網云腦架構,對百度的未來發展趨勢進行分析
百度正式推出百度云ABC 3.0,與各行業結合實現產業變革
百度Apollo高精定位方案分析
新基建時代 百度如何加速百度智能云發展
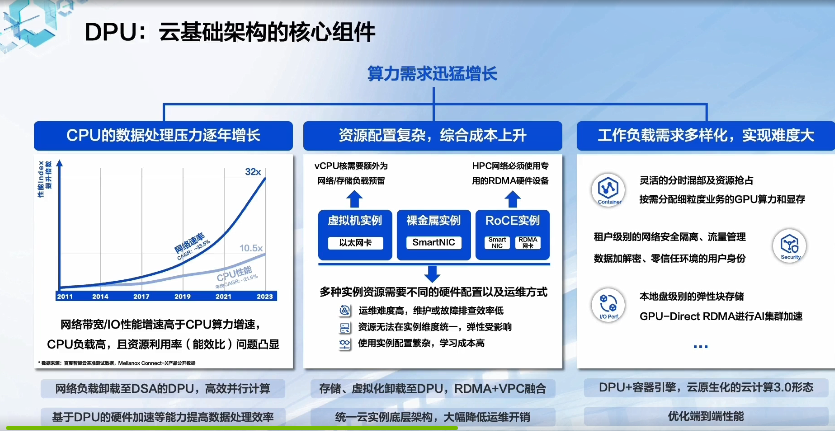
GTC 2023:百度智能云DPU落地實踐





 工商網監
工商網監

評論