

初看Xgboost,翻了多篇博客發現關于xgboost原理的描述實在難以忍受,缺乏邏輯性,寫一篇供討論。
觀其大略,而后深入細節,一開始扎進公式反正我是覺得效率不高,還容易打消人的積極性。
首先說下決策樹
決策樹是啥?舉個例子,有一堆人,我讓你分出男女,你依靠頭發長短將人群分為兩撥,長發的為“女”,短發為“男”,你是不是依靠一個指標“頭發長短”將人群進行了劃分,你就形成了一個簡單的決策樹,官方細節版本自行baidu或google
劃分的依據是啥?這個時候,你肯定問,為什么用“頭發長短”劃分啊,我可不可以用“穿的鞋子是否是高跟鞋”,“有沒有喉結”等等這些來劃分啊,Of course!那么肯定就需要判斷了,那就是哪一種分類效果好,我就選哪一種啊。
分類效果如何評價量化呢?怎么判斷“頭發長短”或者“是否有喉結”…是最好的劃分方式,效果怎么量化。直觀來說,如果根據某個標準分裂人群后,純度越高效果越好,比如說你分為兩群,“女”那一群都是女的,“男”那一群全是男的,這個效果是最好的,但事實不可能那么巧合,所以越接近這種情況,我們認為效果越好。于是量化的方式有很多,信息增益(ID3)、信息增益率(C4.5)、基尼系數(CART)等等,來用來量化純度
其他細節如剪枝、過擬合、優缺點、并行情況等自己去查吧。決策樹的靈魂就已經有了,依靠某種指標進行樹的分裂達到分類/回歸的目的(上面的例子是分類),總是希望純度越高越好。
說下Xgboost的建樹過程
Xgboost是很多CART回歸樹集成
概念1:回歸樹與決策樹事實上,分類與回歸是一個型號的東西,只不過分類的結果是離散值,回歸是連續的,本質是一樣的,都是特征(feature)到結果/標簽(label)之間的映射。說說決策樹和回歸樹,在上面決策樹的講解中相信決策樹分類已經很好理解了。
回歸樹是個啥呢?
直接摘抄人家的一句話,分類樹的樣本輸出(即響應值)是類的形式,如判斷蘑菇是有毒還是無毒,周末去看電影還是不去。而回歸樹的樣本輸出是數值的形式,比如給某人發放房屋貸款的數額就是具體的數值,可以是0到120萬元之間的任意值。
那么,這時候你就沒法用上述的信息增益、信息增益率、基尼系數來判定樹的節點分裂了,你就會采用新的方式,預測誤差,常用的有均方誤差、對數誤差等。而且節點不再是類別,是數值(預測值),那么怎么確定呢,有的是節點內樣本均值,有的是最優化算出來的比如Xgboost。細節http://blog.csdn.net/app_12062011/article/details/52136117博主講的不錯
概念2:boosting集成學習,由多個相關聯的決策樹聯合決策,什么叫相關聯,舉個例子,有一個樣本[數據->標簽]是[(2,4,5)-> 4],第一棵決策樹用這個樣本訓練得預測為3.3,那么第二棵決策樹訓練時的輸入,這個樣本就變成了[(2,4,5)-> 0.7],也就是說,下一棵決策樹輸入樣本會與前面決策樹的訓練和預測相關。
與之對比的是random foreast(隨機森林)算法,各個決策樹是獨立的、每個決策樹在樣本堆里隨機選一批樣本,隨機選一批特征進行獨立訓練,各個決策樹之間沒有啥毛線關系。
所以首先Xgboost首先是一個boosting的集成學習,這樣應該很通俗了
這個時候大家就能感覺到一個回歸樹形成的關鍵點:(1)分裂點依據什么來劃分(如前面說的均方誤差最小,loss);(2)分類后的節點預測值是多少(如前面說,有一種是將葉子節點下各樣本實際值得均值作為葉子節點預測誤差,或者計算所得)
是時候看看Xgboost了
首先明確下我們的目標,希望建立K個回歸樹,使得樹群的預測值盡量接近真實值(準確率)而且有盡量大的泛化能力(更為本質的東西),從數學角度看這是一個泛函最優化,多目標,看下目標函數:

直觀上看,目標要求預測誤差盡量小,葉子節點盡量少,節點數值盡量不極端(這個怎么看,如果某個樣本label數值為4,那么第一個回歸樹預測3,第二個預測為1;另外一組回歸樹,一個預測2,一個預測2,那么傾向后一種,為什么呢?前一種情況,第一棵樹學的太多,太接近4,也就意味著有較大的過擬合的風險)
ok,聽起來很美好,可是怎么實現呢,上面這個目標函數跟實際的參數怎么聯系起來,記得我們說過,回歸樹的參數:(1)選取哪個feature分裂節點呢;(2)節點的預測值(總不能靠取平均值這么粗暴不講道理的方式吧,好歹高級一點)。上述形而上的公式并沒有“直接”解決這兩個,那么是如何間接解決的呢?
先說答案:貪心策略+最優化(二次最優化,恩你沒看錯)
通俗解釋貪心策略:就是決策時刻按照當前目標最優化決定,說白了就是眼前利益最大化決定,“目光短淺”策略,他的優缺點細節大家自己去了解,經典背包問題等等。
這里是怎么用貪心策略的呢,剛開始你有一群樣本,放在第一個節點,這時候T=1,w多少呢,不知道,是求出來的,這時候所有樣本的預測值都是w(這個地方自己好好理解,決策樹的節點表示類別,回歸樹的節點表示預測值),帶入樣本的label數值,此時loss function變為

暫停下,這里你發現了沒,二次函數最優化!
要是損失函數不是二次函數咋辦,哦,泰勒展開式會否?,不是二次的想辦法近似為二次。
接著來,接下來要選個feature分裂成兩個節點,變成一棵弱小的樹苗,那么需要:
(1)確定分裂用的feature,how?最簡單的是粗暴的枚舉,選擇loss function效果最好的那個(關于粗暴枚舉,Xgboost的改良并行方式咱們后面看)
(2)如何確立節點的w以及最小的loss function,大聲告訴我怎么做?對,二次函數的求最值(細節的會注意到,計算二次最值是不是有固定套路,導數=0的點,ok)
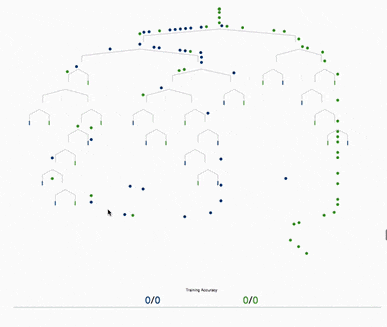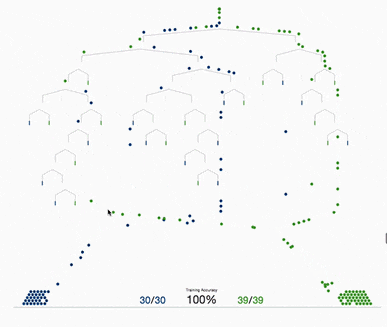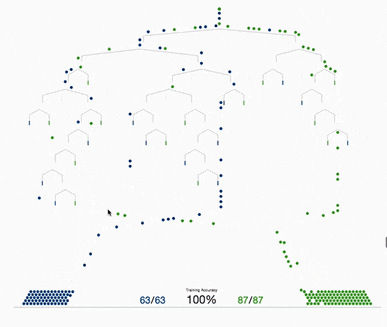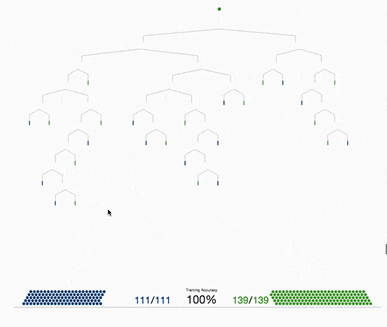
那么節奏是,選擇一個feature分裂,計算loss function最小值,然后再選一個feature分裂,又得到一個loss function最小值…你枚舉完,找一個效果最好的,把樹給分裂,就得到了小樹苗。
在分裂的時候,你可以注意到,每次節點分裂,loss function被影響的只有這個節點的樣本,因而每次分裂,計算分裂的增益(loss function的降低量)只需要關注打算分裂的那個節點的樣本。原論文這里會推導出一個優雅的公式,我不想敲latex公式了,

想研究公式的去這里吧
http://matafight.github.io/2017/03/14/XGBoost-%E7%AE%80%E4%BB%8B/
接下來,繼續分裂,按照上述的方式,形成一棵樹,再形成一棵樹,每次在上一次的預測基礎上取最優進一步分裂/建樹,是不是貪心策略?!
凡是這種循環迭代的方式必定有停止條件,什么時候停止呢:
(1)當引入的分裂帶來的增益小于一個閥值的時候,我們可以剪掉這個分裂,所以并不是每一次分裂loss function整體都會增加的,有點預剪枝的意思(其實我這里有點疑問的,一般后剪枝效果比預剪枝要好點吧,只不過復雜麻煩些,這里大神請指教,為啥這里使用的是預剪枝的思想,當然Xgboost支持后剪枝),閾值參數為γ正則項里葉子節點數T的系數(大神請確認下);
(2)當樹達到最大深度時則停止建立決策樹,設置一個超參數max_depth,這個好理解吧,樹太深很容易出現的情況學習局部樣本,過擬合;
(3)當樣本權重和小于設定閾值時則停止建樹,這個解釋一下,涉及到一個超參數-最小的樣本權重和min_child_weight,和GBM的 min_child_leaf 參數類似,但不完全一樣,大意就是一個葉子節點樣本太少了,也終止同樣是過擬合;
看下Xgboost的一些重點
w是最優化求出來的,不是啥平均值或規則指定的,這個算是一個思路上的新穎吧;
正則化防止過擬合的技術,上述看到了,直接loss function里面就有;
支持自定義loss function,哈哈,不用我多說,只要能泰勒展開(能求一階導和二階導)就行,你開心就好;
支持并行化,這個地方有必要說明下,因為這是xgboost的閃光點,直接的效果是訓練速度快,boosting技術中下一棵樹依賴上述樹的訓練和預測,所以樹與樹之間應該是只能串行!那么大家想想,哪里可以并行?!沒錯,在選擇最佳分裂點,進行枚舉的時候并行!(據說恰好這個也是樹形成最耗時的階段)
Attention:同層級節點可并行。具體的對于某個節點,節點內選擇最佳分裂點,候選分裂點計算增益用多線程并行。—–
較少的離散值作為分割點倒是很簡單,比如“是否是單身”來分裂節點計算增益是很easy,但是“月收入”這種feature,取值很多,從5k~50k都有,總不可能每個分割點都來試一下計算分裂增益吧?(比如月收入feature有1000個取值,難道你把這1000個用作分割候選?缺點1:計算量,缺點2:出現葉子節點樣本過少,過擬合)我們常用的習慣就是劃分區間,那么問題來了,這個區間分割點如何確定(難道平均分割),作者是這么做的:
方法名字:Weighted Quantile Sketch大家還記得每個樣本在節點(將要分裂的節點)處的loss function一階導數gi和二階導數hi,衡量預測值變化帶來的loss function變化,舉例來說,將樣本“月收入”進行升序排列,5k、5.2k、5.3k、…、52k,分割線為“收入1”、“收入2”、…、“收入j”,滿足(每個間隔的樣本的hi之和/總樣本的hi之和)為某個百分比?(我這個是近似的說法),那么可以一共分成大約1/?個分裂點。
數學形式,我再偷懶下(可是latex敲這種公式真的很頭疼):

而且,有適用于分布式的算法設計;
XGBoost還特別設計了針對稀疏數據的算法,假設樣本的第i個特征缺失時,無法利用該特征對樣本進行劃分,這里的做法是將該樣本默認地分到指定的子節點,至于具體地分到哪個節點還需要某算法來計算,
算法的主要思想是,分別假設特征缺失的樣本屬于右子樹和左子樹,而且只在不缺失的樣本上迭代,分別計算缺失樣本屬于右子樹和左子樹的增益,選擇增益最大的方向為缺失數據的默認方向(咋一看如果缺失情況為3個樣本,那么劃分的組合方式豈不是有8種?指數級可能性啊,仔細一看,應該是在不缺失樣本情況下分裂后(有大神的請確認或者修正),把第一個缺失樣本放左邊計算下loss function和放右邊進行比較,同樣對付第二個、第三個…缺失樣本,這么看來又是可以并行的??);
可實現后剪枝
交叉驗證,方便選擇最好的參數,early stop,比如你發現30棵樹預測已經很好了,不用進一步學習殘差了,那么停止建樹。
行采樣、列采樣,隨機森林的套路(防止過擬合)
Shrinkage,你可以是幾個回歸樹的葉子節點之和為預測值,也可以是加權,比如第一棵樹預測值為3.3,label為4.0,第二棵樹才學0.7,….再后面的樹還學個鬼,所以給他打個折扣,比如3折,那么第二棵樹訓練的殘差為4.0-3.3*0.3=3.01,這就可以發揮了啦,以此類推,作用是啥,防止過擬合,如果對于“偽殘差”學習,那更像梯度下降里面的學習率;
xgboost還支持設置樣本權重,這個權重體現在梯度g和二階梯度h上,是不是有點adaboost的意思,重點關注某些樣本。
看下Xgboost的工程優化
這部分因為沒有實戰經驗,都是論文、博客解讀來的,所以也不十分確定,供參考。
Column Block for Parallel Learning總的來說:按列切開,升序存放;方便并行,同時解決一次性樣本讀入炸內存的情況
由于將數據按列存儲,可以同時訪問所有列,那么可以對所有屬性同時執行split finding算法,從而并行化split finding(切分點尋找)-特征間并行可以用多個block(Multiple blocks)分別存儲不同的樣本集,多個block可以并行計算-特征內并行
Blocks for Out-of-core Computation數據大時分成多個block存在磁盤上,在計算過程中,用另外的線程讀取數據,但是由于磁盤IO速度太慢,通常更不上計算的速度,將block按列壓縮,對于行索引,只保存第一個索引值,然后只保存該數據與第一個索引值之差(offset),一共用16個bits來保存 offset,因此,一個block一般有2的16次方個樣本。
與GDBT、深度學習對比下
Xgboost第一感覺就是防止過擬合+各種支持分布式/并行,所以一般傳言這種大殺器效果好(集成學習的高配)+訓練效率高(分布式),與深度學習相比,對樣本量和特征數據類型要求沒那么苛刻,適用范圍廣。
說下GBDT:有兩種描述版本,把GBDT說成一個迭代殘差樹,認為每一棵迭代樹都在學習前N-1棵樹的殘差;把GBDT說成一個梯度迭代樹,使用梯度迭代下降法求解,認為每一棵迭代樹都在學習前N-1棵樹的梯度下降值。有說法說前者是后者在loss function為平方誤差下的特殊情況。這里說下我的理解:第一棵樹形成之

Xgboost和深度學習的關系,陳天奇在Quora上的解答如下:不同的機器學習模型適用于不同類型的任務。深度神經網絡通過對時空位置建模,能夠很好地捕獲圖像、語音、文本等高維數據。而基于樹模型的XGBoost則能很好地處理表格數據,同時還擁有一些深度神經網絡所沒有的特性(如:模型的可解釋性、輸入數據的不變性、更易于調參等)。這兩類模型都很重要,并廣泛用于數據科學競賽和工業界。舉例來說,幾乎所有采用機器學習技術的公司都在使用tree boosting,同時XGBoost已經給業界帶來了很大的影響。
-
算法
+關注
關注
23文章
4650瀏覽量
93790 -
決策樹
+關注
關注
3文章
96瀏覽量
13650
原文標題:通俗的將Xgboost的原理講明白
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于xgboost的風力發電機葉片結冰分類預測 精選資料分享
基于xgboost的風力發電機葉片結冰分類預測 精選資料下載
通過學習PPT地址和xgboost導讀和實戰地址來對xgboost原理和應用分析

面試中出現有關Xgboost總結
如何將原理圖符號畫得通俗易懂,看完你也會啊!資料下載

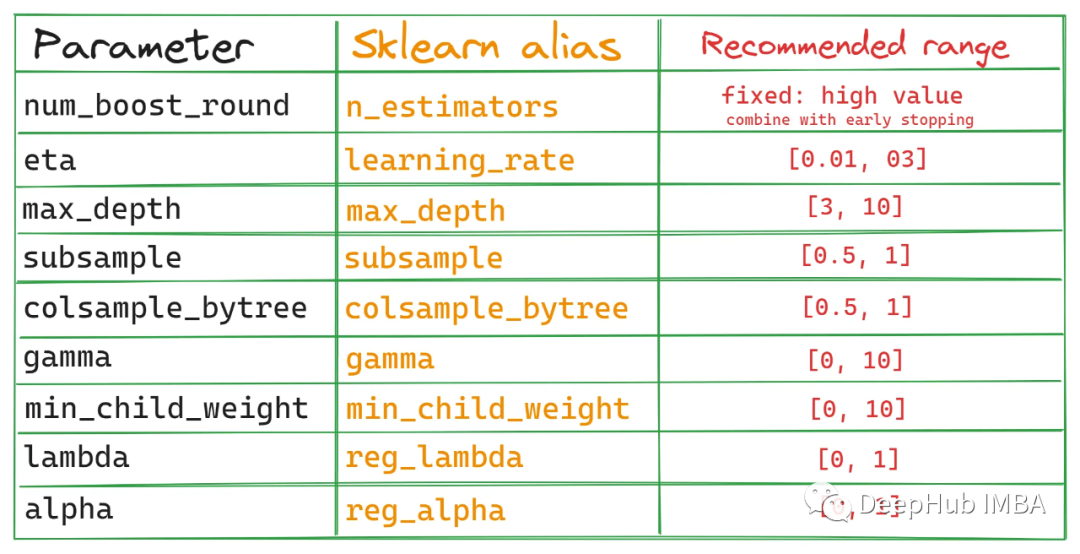
XGBoost超參數調優指南
XGBoost 2.0介紹





 工商網監
工商網監

評論