 如何在圖形生成過程中處理元素的對稱性和排序,并提供可能的解決方案
如何在圖形生成過程中處理元素的對稱性和排序,并提供可能的解決方案
一般來說,圖形是基本的數據結構,它在諸如知識圖、物理和社會交互、語言和化學等許多重要的實際領域中對關系結構進行簡明地捕捉。在本文中,我們引入了一種強大的新方法,用于學習圖形中的生成式模型,既可以捕捉它們的結構也可以捕捉到屬性。我們的方法使用圖形神經網絡表示圖形節點和邊緣之間的概率依賴關系,并且原則上來說,可以學習任何任意圖形上的分布。經過一系列實驗,我們的結果顯示,一旦經過訓練之后,我們的模型可以生成高質量的合成圖和真實分子圖的樣本,無論是在無條件數據還是條件數據的情況下都是如此。與不使用圖形結構表示的基線相比,我們的模型通常表現得更好。我們還探索了學習圖形生成式模型過程中所存在的關鍵性挑戰,例如,如何在圖形生成過程中處理元素的對稱性和排序,并提供可能的解決方案。可以這樣說,我們的研究是用于學習任意圖形上生成式模型的第一個方法,也是最為通用的方法,并且為從向量和序列式的知識表示,轉向更有表現力和更靈活的關系數據結構,開辟了新的研究方向。
圖形是許多問題域中信息的本質性表示。例如,知識圖表和社交網絡中的實體之間的關系可以很好地用圖形進行表示,而且它們也適用于對物理世界進行建模,例如,分子結構以及物理系統中物體之間的交互。因此,捕捉特定圖形族系分布的能力在實際生活中有很多應用。例如,從圖形模型中進行采樣可以致使發現新的配置,而這些配置所具有的全局屬性與藥物發現中所需要的是一樣的(Gómez-Bombarelli等人于2016年提出)。要想獲得自然語言句子中的圖形結構語義表示(Kuhlmann和Oepen于2016年提出),需要具有能夠在圖上對(條件)分布進行建模的能力。圖形上的分布還可以為圖形模型的貝葉斯結構學習提供先驗(Margaritis于2003年提出)。
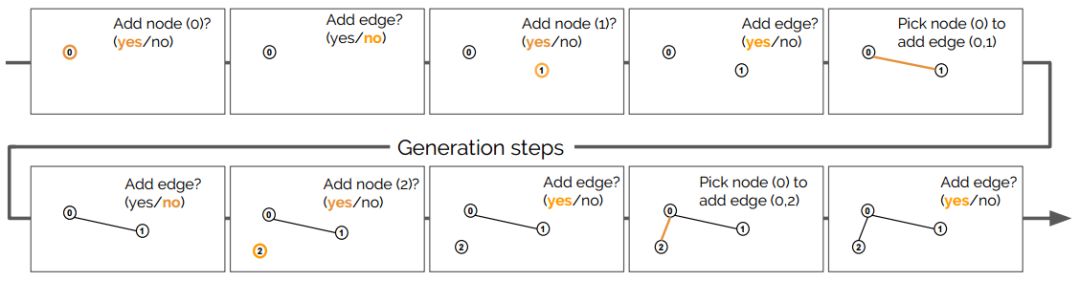
生成過程中所采取步驟的描述
我們至少從兩個角度對圖形的概率模型進行了廣泛研究。一種方法是基于隨機圖形模型,將概率分配給大的圖形類型(Erdos和Rényi于1960年、Barabási和Albert于1999年提出)。這些都具有很強的獨立性假設,并且被設計成僅捕捉某些特定的圖形屬性,例如度數分布(degree distribution)和直徑。雖然這些方法已被證明在對社交網絡等領域進行建模時是有效的,但它們在更加豐富的結構化領域上應用還存在很大的挑戰,其中,細微的結構差異在功能上可能是具有重要意義的,例如在化學中領域或自然語言中所表示的意義。
一個更具表現力但也更為脆弱的方法則是使用圖形語法,它將機制從形式語言理論中泛化到非序列結構模型中(Rozenberg于1997年提出)。圖語法是重寫規則的系統,通過中間圖的一系列轉換遞增地導出輸出圖。雖然符號圖形語法(symbolic graph grammars)可以使用標準技術進行隨機化或加權(Droste和Gastin于2007年提出),但從可學習性的觀點來看,仍然存在兩個需要解決的問題。首先,從一組未經注釋的圖形中引入語法是非常重要的,因為要想對可能用于構建圖形的結構構建操作進行理解在算法上是很難進行的(Lautemann于1988年、Agui?aga等人于2016年提出)。其次,與線性輸出語法一樣,圖形語法在語言內容和要排除內容之間的區分上存在很大的困難,使得這種模型對于一些應用程序來說是不適合應用的,其中,它不適合將0概率分配給某些特定圖形。
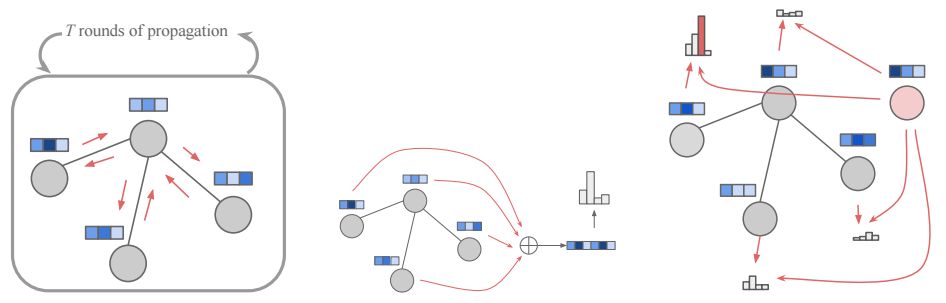
圖形傳播過程的示意圖(左),節點選擇 fnodes模塊(右)
本文引入了一種新的、富有表現力的圖形模型,它不需要做任何結構性假設,也避免了基于語法的技術的脆弱性。我們的模型以類似于圖形語法的方式生成圖形,其中在導出過程中,新結構(特別是新節點或新邊緣)被添加到現有圖形中,并且該添加事件的概率取決于圖形導出的歷史記錄。為了在導出的每個步驟中對圖形進行表示,我們使用一個基于圖形結構的神經網絡(圖形網絡)表示。最近,人們對于用于學習圖形表示和解決圖形預測問題的圖形網絡(graph nets)很感興趣。這些模型是根據所利用的圖形進行構造的,并且以獨立于圖形大小的方式進行參數化,因此針對同構圖形具有不變性,從而為我們的研究目的提供了一個很好的匹配。
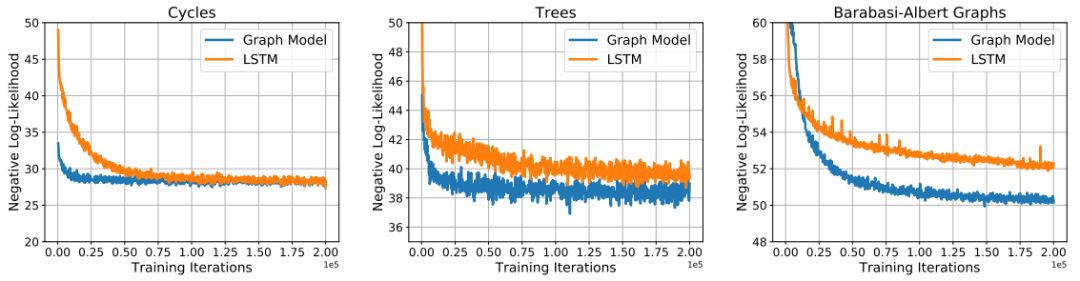
在三組數據集中對圖形模型和LSTM模型進行訓練的曲線
我們在生成具有某些常見拓撲性質(例如:周期性)的隨機圖形,和以非條件或條件的方式生成分子圖形的任務中對我們的模型進行了評估。我們提出的模型在所有的實驗中都表現良好,并且比隨機圖形模型(random graph models)和長短期記憶網絡基線(LSTM baselines)獲得了更好的結果。
本文所提出的是能夠生成任意圖形的強大模型。然而,這些模型依然面臨著許多挑戰。在本文中,我們將討論未來會面臨的一些挑戰及可能的解決方案。
排序
節點和邊緣的排序對于學習和評估而言都很重要,在實驗中,我們總是使用預定義的分配方式排序。然而,通過將排序π視為潛在的變量來學習節點和邊緣的排序也許是可能的,這在未來將是一個有趣的探索方向。
長序列
圖形模型所使用的生成過程通常是一個長的決策序列,如果其他形式的圖形線性化是可用的(例如:SMILES),那么這樣的序列通常會縮短2-3倍。這對于圖形模型而言是一個很大的劣勢,這不僅難以獲得準確的概率,還會使訓練變得更加困難。為了緩解這一問題,我們可以調整圖形模型,以便使其與問題域進行更多地關聯,從而將多個決策步驟和循環轉為單個步驟。
可擴展性
可擴展性是對本文所提出的圖形生成模型的一個挑戰。圖形網絡使用固定的傳播步驟T來上傳圖形中的信息。然而,大的圖形往往需要使用大量的T來獲取足夠的信息,這會限制這些模型的可擴展性。為了解決這一問題,我們可以使用依次掃描邊緣的模型(Parisotto等人于2016年提出),或許采取一些由粗到精的生成方法。
訓練難度
我們發現訓練這樣的圖形模型要比訓練典型的長短期記憶網絡模型更為困難,這些模型所要進行訓練的序列一般比較長,并且模型結構不斷變化還會導致訓練不穩定。降低學習速率可以解決很多不穩定問題,但通過調整模型可以獲得更加令人滿意的解決方案。
本文中,我們提出了一個強大的深度生成模型,其能夠通過一個序列性過程生成任意形。我們在一些圖形生成問題中對它的屬性進行了研究。這一模型已經展現出很大的潛力,并且與標準LSTM模型相比具有獨特的優勢。我們希望我們的研究成果能夠促進這方面的進一步研究,進而獲得更好的圖形生成模型。
-
圖形
+關注
關注
0文章
71瀏覽量
19278 -
DeepMind
+關注
關注
0文章
130瀏覽量
10846
原文標題:DeepMind提出圖形的「深度生成式模型」,可實現「任意」圖形的生成
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
利用對稱性化簡求解對稱電路
運放的哪些參數可以反映出它的不對稱性?
對稱性加密算法
關于電源排序的解決方案你了解嗎
對稱性對傅里葉系數的影響
基于幾何對稱性的顱骨復原技術
對稱性和格點理論在矩量法中的應用
機械結構對稱性實例設計






 工商網監
工商網監
評論