

大語言模型(LLMs)正以革命性的姿態重塑我們與科技的互動模式。然而,由于其龐大的規模,它們往往屬于資源密集型范疇,不僅大幅推高了成本,還造成了能源消耗的激增。本文深入剖析了大語言模型的規模大小、硬件需求以及所涉及的財務影響這三者之間的內在聯系。我們將深入探究現實中大語言模型的發展趨勢,并共同探討如何借助規模更小、效能更高的模型,打造一個更具可持續性的人工智能生態系統。
理解模型規模:參數與性能
不妨將大語言模型視作一個大腦,其中有著數十億個名為“參數”的“細胞”。其“細胞”數量越多,它便越智能,功能也越發強大。從傳統意義上來說,規模更大的模型往往具備更卓越的理解能力,所儲備的知識也更為豐富——這就好比一個大腦,同時擁有了更高的智商和更強大的記憶力。本質上,一個大型的大語言模型就如同一位學識深厚、見解獨到的專家。然而,獲取這種專業能力是需要付出代價的。這些規模更大的模型需要更為強勁的計算機來驅動,能耗也會大幅增加,不僅使成本顯著上升,對環境產生的影響也不容小覷*。
為了能更好地對語言模型進行分類,按照模型規模大小來劃分會很有幫助。這張圖表展示了不同類別的模型,以及與之對應的參數數量和示例:

基于公開可用信息(在可獲取的情況下)和行業對閉源模型的估計。
大語言模型:性能更優,體積更小
我們不妨以 Llama 模型為例。這些模型的迅猛發展,凸顯出人工智能領域的一個關鍵趨勢:對效率與性能的高度重視。
2023年8月,Llama 2 700億參數(70B)版本一經推出,便被視作頂級基礎模型。然而,其龐大的規模對硬件要求極高,只有像 NVIDIA H100 這樣強勁的加速器才能支撐其運行。短短不到九個月后,Meta 公司推出了 Llama 3 80億參數(8B)版本,模型規模銳減近九倍。這一優化使得該模型不僅能夠在更為小巧的人工智能加速器上運行,甚至在經過優化的 CPU 上也能順暢運作,硬件成本與功耗均大幅降低。尤為值得一提的是,在準確性基準測試中,Llama 3 80億參數版本的表現超越了參數更多、體積更大的前代模型。
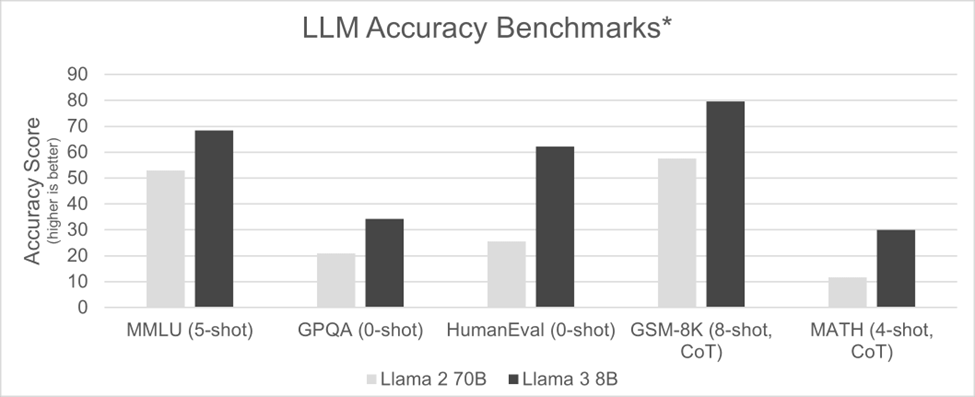
*信息來源及測試方法:出自 “指令微調模型” 部分:
這一趨勢在2024年9月 Llama 3.2發布時得以延續,該版本推出了適用于多種應用場景的10億參數(1B)和30億參數(3B)變體。就連像 Llama 3.2 4050億參數(405B)這樣的大型三類模型也在縮小規模。2024年12月,Llama 3.3 700億參數(70B)版本問世,在 MMLU 聊天測評中取得了86.0的分數*,幾乎與參數規模大得多的前代模型 Llama 3.2 4050億參數(405B)所獲得的88.6分相當。
這表明,如今較小規模類別的模型在使用更少計算資源的情況下,其性能(準確性)已能與上一代較大規模類別的模型相媲美。這種向更小、更高效模型的轉變正在推動人工智能的普及,有助于讓更多人能夠使用人工智能,同時也使其更具可持續性*。更妙的是,這種朝著小型語言模型發展的趨勢在未來很可能會持續下去,因此可以預期,未來發布的新模型其規模可能會比當前一代的模型小很多倍。
模型愈發貼合特定應用場景
我們正見證著一種日益增長的趨勢,即通過一種名為知識蒸餾的過程來創建專門的人工智能模型。這種技術本質上是從大語言模型中“去除冗余”,剔除不必要的信息,并常常針對特定任務對其進行優化。
可以這樣理解:一家大型銷售機構想要分析其內部數據,它并不需要一個能夠寫詩或設計建筑的人工智能模型。同樣,一個需要編碼幫助的工程部門也不需要一個擁有豐富鳥類遷徙知識的模型。
通過知識蒸餾,我們能夠創建出在指定領域表現卓越的高度專業化模型。這些模型更加精簡、運行速度更快且效率更高,因為它們沒有被無關信息所累。
這種朝著特定領域模型發展的趨勢帶來了諸多好處:
? 提高準確性:通過專注于特定領域,這些模型在其專業領域內能夠實現更高的準確性和更好的性能表現。
? 降低資源消耗:規模更小、更具針對性的模型通常所需的計算能力和內存更少,這有助于使其更具成本效益且更加節能。
? 增強可部署性:特定領域的模型可以輕松部署在更廣泛的硬件上,包括直接在經過人工智能優化的 CPU 上進行推理。
隨著人工智能的不斷發展,我們可以預期,這些專門的模型將大量涌現,在從客戶服務、醫學診斷到金融分析、科學研究等各個特定領域中表現出色。我們期待看到在全球范圍內的各個行業和應用中,新的潛力被不斷挖掘出來。
你的人工智能運行速度是不是太快了?
人們往往很容易想要把重點放在最大化人工智能推理速度上(就好比吹噓一輛跑車的最高時速那樣),但一種更為實際的做法是考慮用戶的實際需求。
就像用一輛跑車來滿足日常通勤需求有點大材小用一樣,以閃電般的速度生成文本對于人機交互來說可能也沒有必要。有資料顯示,普通人每分鐘能閱讀200到300個英文單詞。人工智能模型很容易就能超過這個速度,但根據與人工智能平臺聯盟*的合作經驗,每分鐘輸出大約450個單詞(每秒10個詞元,按每個英文單詞約1.3個詞元來算*)的速度通常就足夠了。
一味地追求絕對速度可能會導致不必要的成本增加和流程復雜化。一種更為平衡的方法是注重在不過度消耗資源的前提下,為用戶提供最佳的使用體驗。
云原生處理器:用于推理的靈活解決方案
AmpereOne 云原生處理器,相較于 GPU 具有一項關鍵優勢:靈活性。它們能夠對計算核心進行分配,從而允許多個人工智能推理會話同時運行。雖然 GPU 通常一次只能處理單個
會話(不過也有一些例外情況,比如 NVIDIA H100 具備有限的多實例 GPU(MIG)功能),但一個擁有192個核心的 CPU 可以進行分區,以處理大量較小的任務,其中包括通用型工作負載。
這使得 CPU 在運行規模較小的0類或1類人工智能模型時效率極高。盡管 GPU 憑借其強大的原始計算能力,在處理規模較大的2類或3類模型時仍然表現出色,但對于許多常見的人工智能應用而言,CPU 提供了一種具有成本效益且可擴展的解決方案。
從本質上講,這關乎為任務選擇合適的工具。對于大型、復雜的模型而言,人工智能硬件加速器無疑是最佳選擇。但對于數量較多的小型任務,經過人工智能優化的云原生處理器所具備的靈活性和高效性則展現出了顯著的優勢。
通過合理規劃計算規模,實現每個機架的大語言模型效率最大化
為了讓每個人都能更輕松地使用人工智能推理,我們需要降低其成本。這意味著要選擇規模較小的人工智能模型,并讓它們在高效的硬件上運行,從而最大限度地增加我們能夠同時執行的人工智能任務數量。
大多數數據中心運營商每個機架的電力預算限制在10千瓦到20千瓦之間*。通過優化模型規模和硬件選擇,我們可以提高每個機架上人工智能推理的密度,使這項技術更具成本效益,也更能廣泛普及。
我們以一個功率為12.5千瓦、42U規格的機架為例來進行說明。以下是根據模型規模和硬件配置,在保持每秒至少10個詞元(TPS)的情況下,能夠運行的人工智能推理會話數量:
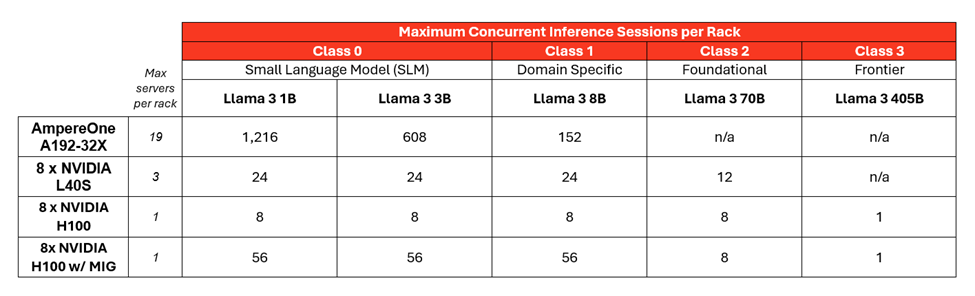
敲黑板劃重點:較小規模的人工智能模型(0類或1類)能夠在一個機架中大幅增加可同時運行的人工智能任務數量,并且還能始終保持令人滿意的用戶體驗。以下是這一情況得以實現的原因:
? 能源效率:AmpereOne 能源利用效率高,能夠在普通機架中實現可運行服務器數量的最大化。
? 分區能力:擁有192個計算核心的 AmpereOne 允許每個機架創建多個并發的推理會話。
? Ampere 人工智能優化器:Ampere 的人工智能優化器(AIO)庫有助于提升諸如Llama 3等大語言模型的性能。
構建更具可持續性的人工智能計算體系通過針對特定的應用場景和行業對人工智能模型進行優化,我們能夠顯著減小模型的規模和復雜程度。這種有的放矢的方法有助于創建出規模更小、效率更高的模型,這些模型所需的計算能力較低,并且可以在成本更低、更易于獲取的云原生硬件上運行。這不僅使個人和小型組織更容易接觸和使用人工智能,還能通過降低能源消耗來促進可持續發展。
這賦予了個人、研究人員以及各種規模的企業利用人工智能潛力的能力,從而在各個領域推動創新并帶來社會效益。若想深入了解 Ampere 在人工智能推理領域的創新成果,可訪問 Ampere 人工智能主頁。
關于 Ampere Computing
Ampere Computing 是一家現代化半導體企業,致力于塑造云計算的未來,并推出了世界上首款云原生處理器。為可持續云而生,Ampere 云原生處理器兼具最高性能和最佳每瓦性能,助力加速多種云計算應用的交付,為云提供行業領先的性能、能效和可擴展性。
-
處理器
+關注
關注
68文章
19759瀏覽量
233017 -
cpu
+關注
關注
68文章
11015瀏覽量
215373 -
人工智能
+關注
關注
1804文章
48503瀏覽量
245284 -
語言模型
+關注
關注
0文章
558瀏覽量
10615 -
Ampere
+關注
關注
1文章
81瀏覽量
4642
原文標題:大語言模型(LLMs):并非越大越好
文章出處:【微信號:AmpereComputing,微信公眾號:安晟培半導體】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
體驗碎片化及安徽信任度將影響大時代人工智能設備的可靠發展
STM32單片機基礎01——初識 STM32Cube 生態系統 精選資料分享
Microchip FPGA 和基于 SoC 的 RISC-V 生態系統簡介
IT的生態系統概述
BAT搶占智能家庭市場入口,打造自家生態系統
如何使用人工智能進行智能家居生態系統設計的研究分析
美軍人工智能的生態系統變化綜述





 工商網監
工商網監

評論