 從深度學習的原理和基礎出發闡述了深度學習的局限性
從深度學習的原理和基礎出發闡述了深度學習的局限性
在過去幾十年中,深度學習作為人工智能領域的頭號種子選手,成為了激動人心的科技創新。在諸如語音識別、癌癥檢測等對于傳統軟件模型難以解決的領域中,深度學習已經初露鋒芒。
深度學習的原理經常被用來與人類學習的過程相類比,專家們相信深度學習過程將會更快,更深入的延伸至更多的領域中。在某些情況下,人們會擔心深度學習會威脅人類在社會和經濟生活中的關鍵地位,造成諸如失業甚至是人類被機器奴役的后果。
毫無疑問,機器學習和深度學習對某些任務而言是十分有效的,然而它并不是可以解決所有問題、凌駕于所有科技之上的萬能鑰匙。事實上,相比于過度炒作夸大的概念,仍有許多的制約和挑戰使得該技術在某些方面仍不足以和人類,甚至無法達到人類孩童的能力。
讓我們回憶兒時的童年經歷:第一次接觸超級瑪麗時只玩了幾個小時便初步形成了粗淺的關于平臺游戲(platform game)的概念。下次玩到類似的游戲(諸如prince of persia, sonic hedgehog, crash bandicoot 或是donkye kong country)時,便可以將之前在超級瑪麗游戲中的實戰經驗應用于它們。如果之后它們升級成了3d版本(正如90年代中期出現的),也可以毫不費力的上手。同時,也可以輕而易舉的將現實生活中的經驗應用于游戲之中,遇到深坑時我馬上知道要操作馬里奧跳過它,遇到有刺的植物時,我馬上知道要避開。
我們算不上優秀的游戲玩家,但對于深度學習算法而言,完成上述過程卻充滿了挑戰,即使是最聰明的游戲算法也要從零開始學起。
人類可以通過抽象、類比、演繹,對不同的概念進行借鑒和學習,達到舉一反三的效果。深度學習的算法卻無法做到如此,它需要大量精準的訓練來實現。
在最近的一篇題為“深度學習的客觀評價”一文中,前Uber人工智能領導,紐約大學教授Gray Marcus講述了深度學習遇到的限制與挑戰,他從深度學習的原理和基礎出發闡述了深度學習的局限性,但也對未來面對的挑戰表達了殷切的期許。
深度學習的原理
通過對人腦處理信息時所采用方法的抽象總結和模擬,提出了神經網絡的概念。未經處理的數據(圖像,聲音信息或者文字信息)被輸入至輸出層的“輸入單元”;輸入信息經過一定的映射輸出至輸出層的“輸出節點”。映射的方法根據用戶定義,比如說,輸入的圖畫中有貓咪,輸入的聲音片段中有“hello”。深度學習是一種通過多層神經網絡對信息進行抽取和表示,并實現分類、檢測等復雜任務的算法架構。深度神經網絡作為深度學習算法的核心組成部分,在輸入與輸出層之間包含有多層隱藏層,使得算法可以完成復雜的分類關系。
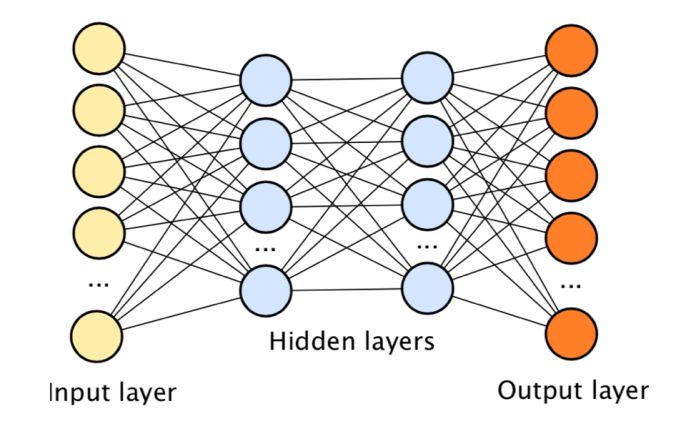
圖:深度神經網絡結構示意圖
深度學習算法需要大量的數據做訓練,比如說如果你想從圖片中準確的識別出是否包含“貓咪”,那么你需要事先用成千上萬張圖片來訓練它。訓練的數據量越大,模型的準確性越高。大公司之間正在不惜一切代價的爭奪數據,甚至愿意免費提供服務以換取數據。擁有越多的數據,就擁有越高的算法準確性和越有效的服務,并將吸引更多的用戶,從而在競爭中形成良性循環。
深度學習需要大量的數據燃料
如果在一個擁有無限數據和計算資源的世界中,除了機器學習之外的其他技術便沒有存在的必要性。但顯而易見的是現實世界并非如此。機器學習算法永遠不可能是全面的,必須要通過插補或推演來對它從未聽到過的聲音或看到過的圖像來給出可能的答案。
對于深度學習算法來說,缺乏“下定義”的過程,既:從特殊到一般的提煉過程,好的效果必須依托于成千上萬甚至更多的訓練樣本之上。
那么如果不能進行大量有效的訓練,會發生什么?答案是:令人瞠目結舌的錯誤!錯誤的算法可能無法分清楚來福搶和直升飛機,大猩猩和人類。
深度學習錯誤識別的例子
對于數據的過度依賴也帶來了使用安全性上的問題。Marcus說過:“深度學習非常善于對特定領域的絕大多數現象作出判斷,另一方面它也會被愚弄。” 這便涉及到對抗樣本對于深度學習算法的攻擊。通過對交通標志很小的涂改,深度學習算法就會誤判停止與限速的交通標記,還有可能無法區分沙堆與肉色針織物。
深度學習并不深刻
深度學習善于建立輸入與輸出之間的映射關系,卻不善于總結發現其中的內在物理聯系。事實上,“深度”這個概念,只是對于多層隱藏層的架構而言,并非指該算法對事物本身的理解有多么深入。Marcus認為:“通過此種算法建構的系統,并不能總結并抽象理解諸如正義,民主,干預之類的概念”。
返回到一開始文章中提到的游戲案例,通過大量的訓練,深度學習算法可以打敗最好的人類超級瑪麗玩家,然而這并不代表人工智能對于游戲有著和人一樣的領悟能力,當一個棒球砸向馬里奧時,游戲玩家都知道通過跳起來躲避,而人工智能只懂得傻傻往前跑,直到被棒球砸中后背。通過反復的試錯實驗,它能夠保證最后的勝率,但是稍微升級以下游戲或改變版本,人工智能卻必須從頭學起。
Marcus的文章中提到谷歌深度學習中的應用案例:在mastering of atari game breakout中,在游戲進行240分鐘后,贏得游戲勝利的最佳方法是在墻上打隧道。然而,它并不明白墻,或者隧道是什么。它只是通過反復的試錯實驗直到,這樣做可以在最短的時間內獲得最高的分數。
深度學習是算法黑箱
依據規則而寫的程序給出的執行結果,可以被追述到最后一個if else。機器學習和深度學習的算法卻不能。這種不透明的性質被定義為“黑箱”問題。深度學習算法在幾千個節點之間建立映射,并給出輸入與輸出之間的關系。即使是開發出此算法的親生工程師也常常會對結果困惑不解。當深度學習應用于容錯率較高的系統時,這個缺點看起來似乎無關緊要。但是想象一下,如果是應用于法庭判決嫌疑人的命運,或者醫療中決定對患者的處理之類的領域之中,任何微小的錯誤都會導致不可逆轉的致命結果。
Marcus認為:”深度學習算法中的透明性問題至今無解,并且嚴重阻礙了它向金融交易、醫療診斷等人們看重并希望了解緣由的領域發展。“
基于對大量數據訓練而得出的結果,使深度學習的方法常常表現出某些偏見,比如:男人比女人的收入更高,白人比黑人更具有外貌優勢。這種錯誤在程序的調試階段很難發現,卻常常會由于其給出的結果,引起社會輿論的廣泛關注和討論。
深度學習注定會失敗嗎?
當然不是!但是需要現實檢驗。
Marcus認為:“深度學習可以作為簡化復雜問題,基于較大的數據量,建立輸入與輸出之間映射關系的完美途徑“。通過合理選擇訓的方法和足夠的訓練樣本,深度學習可以作為一種高效的分類數據的手段。但是它并不擁有魔術般的力量,要認識清楚它的應用局限性和有效性。Marcus 還認為,深度學習還需要和其他的技術結合發展,比如說普通基于規則的編程或者其他的人工智能技術,比如強化學習。Starmind's Pascal Kaufmann 則認為,通過神經科學,從而實現人工智能能夠像人類一樣學習,也許也是行之有效的手段。
最后以Marcus的話來結束全文,并引出對深度學習何去何從的思考:“深度學習不會也不應該消失,但是以五年為期來檢驗深度學習的能與不能,并讓社會各界清醒地接受和認識它的能力與局限性,無論對于技術本身還是社會的發展都具有重要的意義!”
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101047 -
人工智能
+關注
關注
1794文章
47642瀏覽量
239655 -
深度學習
+關注
關注
73文章
5512瀏覽量
121410
原文標題:深度學習鋒芒背后的“能”與“不能”
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
34063的局限性
Nanopi深度學習之路(1)深度學習框架分析
深度學習模型是如何創建的?
什么是深度學習?使用FPGA進行深度學習的好處?
深度學習引發人工智能浪潮同時也加速“AI泡沫”的到來
如何使用深度學習進行視頻行人目標檢測





 工商網監
工商網監
評論