") 基因技術(shù)被認(rèn)為是改變未來(lái)的技術(shù)之一
基因技術(shù)被認(rèn)為是改變未來(lái)的技術(shù)之一
基因技術(shù)被認(rèn)為是改變未來(lái)的技術(shù)之一。根據(jù)麥肯錫的報(bào)告,預(yù)計(jì)到2025年,全球?qū)?huì)累計(jì)產(chǎn)生10億人次的全基因組數(shù)據(jù)。基因組學(xué)所需的數(shù)據(jù)量如此巨大,用深度學(xué)習(xí)技術(shù)去探索人類基因組密碼便成為了趨勢(shì)與未來(lái)。本專欄將結(jié)合最新的一篇來(lái)自于卡耐基梅龍大學(xué)的綜述論文,回顧與展望這一交叉學(xué)科的發(fā)展。
自從2013年變分自動(dòng)編碼器(VAEs)被提出,2014年Goodfellow提出生成對(duì)抗網(wǎng)絡(luò)(GANs)起,生成式模型(generative models)深得深度學(xué)習(xí)研究者的青睞。尤其是當(dāng)深度學(xué)習(xí)由于“black box”限制不能充分地推動(dòng)AI在生物學(xué)、基因組學(xué)中的發(fā)展時(shí),很多學(xué)者力求探索生成式模型在其中的應(yīng)用。
比如,前幾日arXiv上一篇來(lái)自斯坦福大學(xué)的論文就展現(xiàn)了如何利用 GANs 去編碼可變長(zhǎng)度蛋白質(zhì)的合成 DNA 序列。面對(duì)合成生物學(xué)這類屬于人類未來(lái)的新興學(xué)科,人工智能在其中能發(fā)揮的巨大作用值得期待。對(duì)于想要了解這一領(lǐng)域的學(xué)者,本專欄介紹的這篇由卡耐基梅龍大學(xué)碩士岳天溦與Eric Xing教授的學(xué)生汪浩瀚合著的論文“Deep Learning for Genomics: A Concise Overview”, 綜述了深度學(xué)習(xí)在基因組學(xué)中的應(yīng)用。文中分析了不同深度模型的優(yōu)劣勢(shì),舉例講解如何利用深度學(xué)習(xí)解決基因?qū)W問(wèn)題,并且指出了當(dāng)前科研所面臨的缺陷和挑戰(zhàn)。

論文鏈接:https://arxiv.org/abs/1802.00810作者GitHub還有一些重要論文的筆記: https://github.com/ThitherShore/DLforGenomics
深度學(xué)習(xí)應(yīng)用于基因組學(xué):解密人類遺傳密碼
自從 James D Watson 于1953年將DNA解釋為人類遺傳信息的載體,人們便致力于研究如何更有效地收集生物信息,以及探索由這些遺傳信息主導(dǎo)的生物學(xué)過(guò)程。于1990年啟動(dòng)的科學(xué)探索巨型工程:人類基因組計(jì)劃(Human Genome Project),其宗旨便在于測(cè)定組成人類染色體所包含的30億個(gè)堿基對(duì)組成的核苷酸序列。其目的在于繪制人類基因組圖譜,辨識(shí)并破譯其載有的人類遺傳信息。至2001年,人類基因組計(jì)劃首次公布了人類基因組工作的草圖。近年來(lái),F(xiàn)ANTOM, ENCODE, Roadmap Epigenomics等,以及不同物種的基因組計(jì)劃被陸續(xù)啟動(dòng)執(zhí)行,使得科學(xué)家們有更多的途徑和信息去探索基因科技。在這個(gè)人工智能技術(shù)全面滲透的時(shí)代,基因科技作為可以改變?nèi)祟愇磥?lái)的科技之一,也備受關(guān)注。
基因組學(xué)不同于傳統(tǒng)的遺傳學(xué),它的數(shù)據(jù)量非常大。遺傳學(xué)研究通常只牽扯到個(gè)別基因,但基因組學(xué)研究需考慮一個(gè)生物體的所有基因,從整體水平上探索全基因組在生命活動(dòng)中發(fā)揮的作用。比如,若對(duì)人類基因序列測(cè)序,那么信息量級(jí)為23對(duì)染色體上的30億對(duì)堿基排序。
由于基因組學(xué)所需信息量巨大,其研究的推動(dòng)依賴于先進(jìn)的基因測(cè)序技術(shù)。Frederick Sanger 發(fā)明了測(cè)序法后,人類才得以對(duì)整個(gè)基因組進(jìn)行測(cè)序。DNA微陣列(macroarray)芯片技術(shù)的誕生,使得大規(guī)模的基因測(cè)序成為可能。隨后,2000年首次商用的高通量測(cè)序(High-throughput Sequencing, THS)是基因測(cè)序領(lǐng)域的一次革命性的技術(shù)變革。HTS 可以大規(guī)模、低成本、快速地獲得任何生物的基因序列。但 HTS 有一個(gè)致命的缺陷,其測(cè)序結(jié)果是不完整的短序列片段,被稱為讀取單位(reads)。如何高效又精準(zhǔn)地拼接這些碎片化的信息,對(duì)于HTS一直以來(lái)是一種挑戰(zhàn)。近期,一款由Google Brain 聯(lián)合 Alphabet旗下公司Verily所開(kāi)發(fā)的開(kāi)源工具DeepVariant,巧妙地將HTS序列片段的拼接問(wèn)題轉(zhuǎn)化為一個(gè)圖像處理分類問(wèn)題。DeepVariant利用了Google Brain 的圖像處理模型Inception,用深度神經(jīng)網(wǎng)絡(luò)來(lái)識(shí)別HTS測(cè)序結(jié)果中DNA堿基變異位點(diǎn),包括基因 組上的單堿基突變(SNP)和小的插入缺失(Indel),從而極大提高了的拼接精度。
另一方面,深度學(xué)習(xí)模型被廣泛應(yīng)用于鑒別基因的不同成分,比如外顯子(exons), 內(nèi)含子( introns), 啟動(dòng)子(promoters), 增強(qiáng)子(enhancers), positioned nucleosomes, 剪接位點(diǎn)( splice sites), 非轉(zhuǎn)錄區(qū) (untranslated region, UTR)等。同時(shí),有豐富的數(shù)據(jù)種類可被用于基因組學(xué)的研究:基因微列陣(microarray),RNA-seq expression,轉(zhuǎn)錄因子(DNA結(jié)合),轉(zhuǎn)錄后修飾(RNA結(jié)合),組蛋白修飾(histone modifications)等。許多信息門戶比如GDC, dbGaP, GEO都為廣大科研工作者提供了這類數(shù)據(jù)來(lái)源。
面對(duì)日益精進(jìn)的生物技術(shù),和飛速發(fā)展的深度學(xué)習(xí)與人工智能技術(shù),用深度學(xué)習(xí)去探索人類基因組密碼便成為了趨勢(shì)與未來(lái)。這篇paper分析了不同深度模型的優(yōu)劣勢(shì),并站在不同生物問(wèn)題的角度,談及深度學(xué)習(xí)在其中的應(yīng)用。文末指出了當(dāng)前科研工作的一些缺陷和挑戰(zhàn)。
深度學(xué)習(xí)模型對(duì)比:CNN、RNN、自動(dòng)編碼器、新興模型結(jié)構(gòu)
深度學(xué)習(xí)發(fā)展至今,CNN, RNN, 前饋神經(jīng)網(wǎng)絡(luò)(feed-forward neural networks),自動(dòng)編碼器(Auto-Encoders)等種類繁多。在實(shí)際應(yīng)用中,如何利用各類模型的優(yōu)勢(shì)去解決不同類型的基因?qū)W問(wèn)題呢?
CNN
近幾年,CNN在計(jì)算機(jī)視覺(jué)領(lǐng)域取得了空前的成功,這得益于其擅長(zhǎng)的捕捉空間信息特征的能力。CNN在圖像處理領(lǐng)域卓越的性能亦可被用于基因組學(xué)研究中。類比于有R, G, B三個(gè)顏色通道的二維圖像,基因序列的一個(gè)窗口可以被看做有4個(gè)頻道(A, T, C, G)的一維序列,由此便可通過(guò)一維卷積核進(jìn)行單序列分析(single sequence assays)。CNN能夠逐步提取圖像特征的能力,可以被用來(lái)鑒別基因圖像中有意義的圖形,從而應(yīng)用于 motif identification 和 binding classification 等問(wèn)題中。
RNN
RNN擅長(zhǎng)于處理序列性數(shù)據(jù),故而成功應(yīng)用于自然語(yǔ)言處理領(lǐng)域。由于基于序列很長(zhǎng),且位點(diǎn)之間有復(fù)雜的相關(guān)性,故RNN類結(jié)構(gòu)(LSTM, bi-LSTM, GRU)也被很多基因組學(xué)研究者青睞,應(yīng)用于通過(guò)基因序列的信息研究非編碼DNA(non-coding DNA)功能,或進(jìn)行亞細(xì)胞定位( subcellular localization)等。
Auto encoders
自動(dòng)編碼器是一個(gè)由來(lái)已久的神經(jīng)網(wǎng)絡(luò)模型,以往常被用于初始化神經(jīng)網(wǎng)絡(luò)參數(shù)。在近年VAE的思路提出后,不少學(xué)者又開(kāi)始應(yīng)用VAE或Autoencoders類(Contractive Autoencoders, Stacked Denoising Autoencoders, Denoising Autoencoders)模型來(lái)進(jìn)行數(shù)據(jù)降維,或試圖借此捕捉基因序列間隱含的依賴關(guān)系。
新興模型結(jié)構(gòu)
由于基因組數(shù)據(jù)量大,生物體各部分間依賴關(guān)系復(fù)雜,單一形式的深度神經(jīng)網(wǎng)絡(luò)模型已經(jīng)不能滿足人們對(duì)效率和精度的高要求,目前在基因組研究中取得突破性成功項(xiàng)目,都運(yùn)用、結(jié)合了多個(gè)深度學(xué)習(xí)網(wǎng)絡(luò)模塊。比較常見(jiàn)的幾種方式包括:
CNN+RNN結(jié)構(gòu),利用CNN初步處理DNA序列局部特征,后結(jié)合RNN挖掘DNA序列間的依賴性,比如DanQ(下圖),在輸入層將DNA序列表示成one-hot編碼,分別經(jīng)過(guò)卷積層和池化層后,用LSTM進(jìn)行進(jìn)一步特征提取;
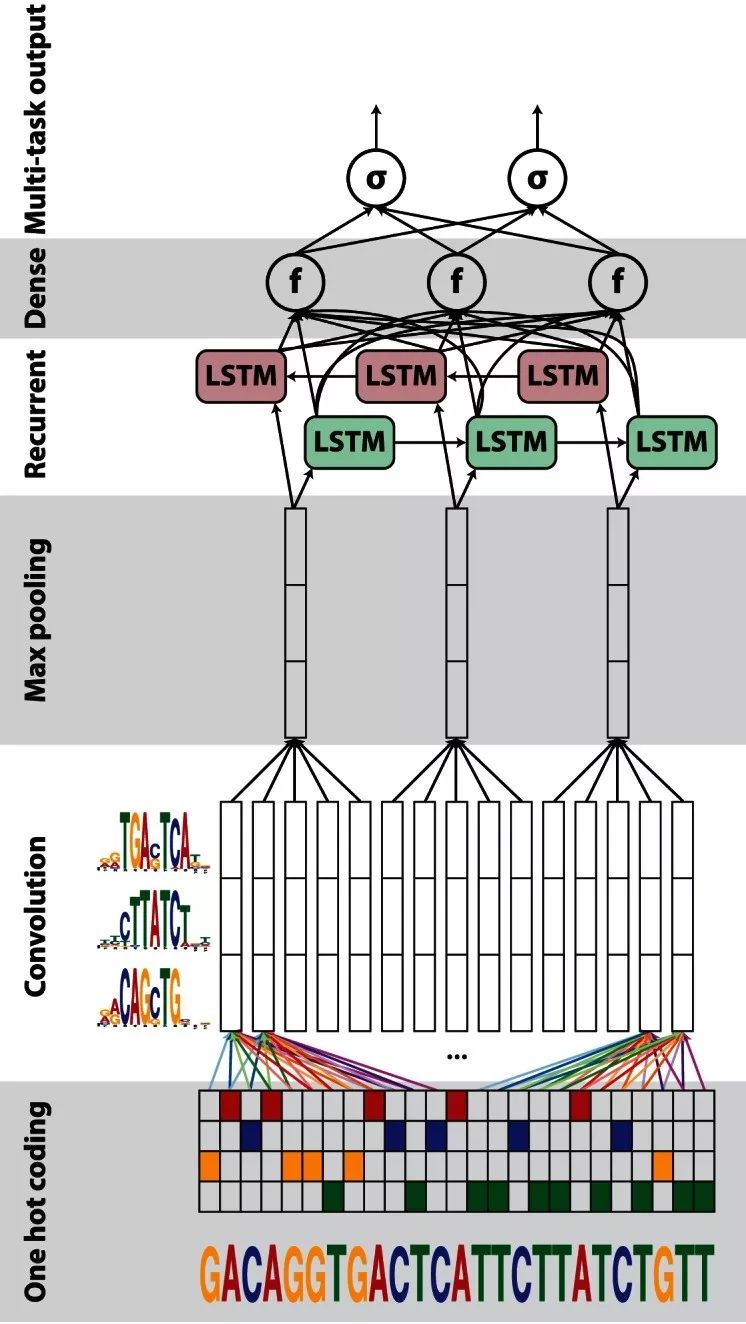
堆疊的(stacked)網(wǎng)絡(luò)結(jié)構(gòu),利用多層網(wǎng)絡(luò)去捕捉深層次的相互依賴關(guān)系,比如 DST-NNs;
同一網(wǎng)絡(luò)結(jié)構(gòu)的并行運(yùn)用,比如DeepCpG,將兩個(gè)CNN各自作為整體模型的兩個(gè)子模塊(sub modules),分別從CpG sites和DNA序列提取特征,并在高層模塊(Fusion Module)融合這兩部分信息;
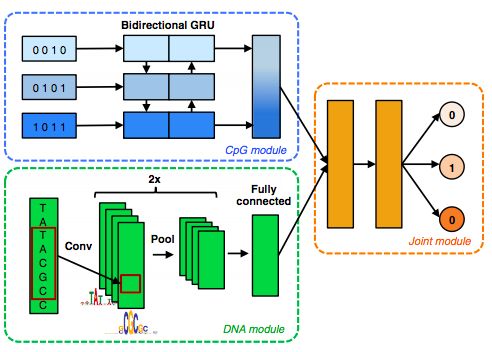
對(duì)于這些新興的,更復(fù)雜的網(wǎng)絡(luò)結(jié)構(gòu),雖然其應(yīng)用效果優(yōu)于傳統(tǒng)統(tǒng)計(jì)或機(jī)器學(xué)習(xí),但其泛化性,可解釋性還亟待探究。
深度學(xué)習(xí)模型的可解釋性和建模方式
模型可解釋性
深度學(xué)習(xí)“黑箱”是人們一直在力求改進(jìn)的一個(gè)缺陷。由于深度學(xué)習(xí)方法本身的這點(diǎn)不足,人們?cè)谥苯訉⑵鋺?yīng)用在基因組學(xué)中,力求解釋基因問(wèn)題時(shí),希望能夠賦予自己的模型適當(dāng)?shù)目山忉屝浴W髡呓榻B了一些經(jīng)典的計(jì)算機(jī)視覺(jué)領(lǐng)域?qū)NN的解釋,和基因組應(yīng)用中人們結(jié)合問(wèn)題對(duì)深度學(xué)習(xí)模型解釋的例子。比如可視化CNN各層提取的特征,或采用saliency map,又比如 Deep GDashboard 模型,它探索比較了CNN和RNN各自在同一個(gè)問(wèn)題中發(fā)揮的性能。
建模方式討論
想要提高深度學(xué)習(xí)在基因組學(xué)中應(yīng)用的效果,除了提升模型結(jié)構(gòu)上的設(shè)計(jì),還可以考慮從模型訓(xùn)練上提高。由于基因組數(shù)據(jù)量之大,完整訓(xùn)練一個(gè)精準(zhǔn)有效的網(wǎng)絡(luò)耗時(shí)且困難,所以可以考慮遷移學(xué)習(xí)(transfer learning)。很將某個(gè)訓(xùn)練好的模型(部分或整體)用作另一個(gè)問(wèn)題的初始化,或用已有模型直接進(jìn)行特征提取分析。這種思路在計(jì)算機(jī)視覺(jué)領(lǐng)域早已應(yīng)用。此外,可以考慮同時(shí)解決兩個(gè)或多個(gè)相關(guān)的問(wèn)題(多任務(wù)學(xué)習(xí), multitask learning),在建模中利用他們共有的信息成分。考慮到基因組數(shù)據(jù)的多樣性,可以考慮multi-view learning,建立模型利用該問(wèn)題的不同數(shù)據(jù)類型。這可以通過(guò)concatenating features, ensemble methods, or multi-modal learning (為不同模塊/不同數(shù)據(jù)類型設(shè)計(jì)相應(yīng)的sub-networks,并在網(wǎng)絡(luò)高層結(jié)構(gòu)中融合各個(gè)子網(wǎng)絡(luò)的信息) 來(lái)實(shí)現(xiàn)。
深度學(xué)習(xí)在基因組學(xué)問(wèn)題中的應(yīng)用
論文中回顧了深度學(xué)習(xí)在以下這些領(lǐng)域中的應(yīng)用,并詳細(xì)介紹了一些近年的值得矚目的研究:
1. 基因表達(dá)(gene expression):特征和預(yù)測(cè)2. 調(diào)控基因組學(xué)(regulatory genomics):
啟動(dòng)子(promoters)和增強(qiáng)子(enhancers)
Functional Activities
Splicing
轉(zhuǎn)錄因子(Transcription Factors) and RNA-binding Proteins
亞細(xì)胞定位(Subcellular Localization)
突變(Mutations) and Variant Calling
3. 結(jié)構(gòu)基因組學(xué)(structural genomics):
蛋白質(zhì)的結(jié)構(gòu)分類(Structural Classification of Proteins)
蛋白質(zhì)二級(jí)結(jié)構(gòu)(Protein Secondary Structure)
Contact Map
挑戰(zhàn)和展望
想要建立深度學(xué)習(xí)模型解決基因組學(xué)問(wèn)題,需要明確現(xiàn)有一些限制和挑戰(zhàn),才能更有全局觀,更有目的性的開(kāi)發(fā)更有效的模型。
數(shù)據(jù)局限性
獲取生物學(xué)數(shù)據(jù)通常耗財(cái)耗時(shí),尤其是當(dāng)我們想通過(guò)基因組學(xué)數(shù)據(jù)研究某種稀有性狀/疾病時(shí),數(shù)據(jù)來(lái)源十分匱乏。
作者介紹了以下幾種情況下應(yīng)對(duì)數(shù)據(jù)所帶來(lái)的局限性的一些對(duì)策和論文:1.數(shù)據(jù)各類之間不平衡(class-imbalanced)或部分?jǐn)?shù)據(jù)沒(méi)有標(biāo)簽(labels)
2.數(shù)據(jù)類型不同(Various Data Sources)3.數(shù)據(jù)來(lái)源混雜(Heterogeneity and Confounding Correlations):heterogeneous datasets是醫(yī)療數(shù)據(jù)中很常見(jiàn)的問(wèn)題。人種的不同,人群的區(qū)域性,數(shù)據(jù)采集的不同批次,都會(huì)造成一些誤導(dǎo)因素(confoundering factors)需要模型去處理。
特征提取
在應(yīng)用中,很多時(shí)候我們會(huì)采用一些人工提取的特征(hand-engineered features),但這通常需要相應(yīng)領(lǐng)域的專家協(xié)助。雖然譬如CNN這樣的模型,可以有效地提取數(shù)據(jù)中的特征,但這對(duì)模型的設(shè)計(jì)和調(diào)參要求較高。故若有好的特征提取方式,可以有效加速模型訓(xùn)練,推動(dòng)科研進(jìn)程。作者談及了幾種基于拓?fù)鋵W(xué)(topology)的特征提取方式,和一些特征表示方式。
如下圖,這是一個(gè)利用了拓?fù)鋵W(xué)中持續(xù)同調(diào)(persistent homolgy)概念提取蛋白質(zhì)三維結(jié)構(gòu)中特征的思路。作者從蛋白質(zhì)出發(fā)建單純復(fù)形(simplicial complex),從其中拓?fù)洳蛔兞刻崛√卣鳎⒊晒Φ貞?yīng)用于包括蛋白質(zhì)superfamily分類,protein-ligand binding等多個(gè)問(wèn)題中。
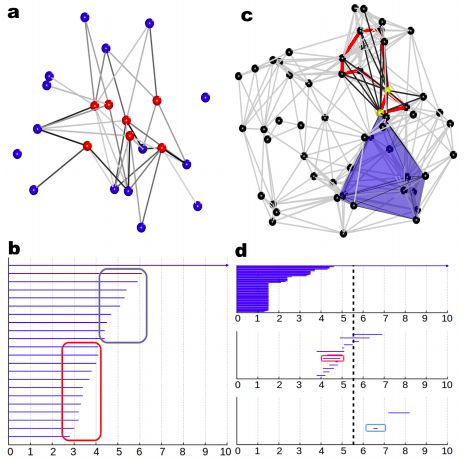
前文討論過(guò)各種模型的優(yōu)劣勢(shì),故而在設(shè)計(jì)模型時(shí),我們應(yīng)根據(jù)問(wèn)題選擇合理的設(shè)計(jì)。同時(shí),也可以在模型參數(shù)中引入一些生物學(xué)背景知識(shí)(prior information),在有限的數(shù)據(jù)下,盡可能有效地利用現(xiàn)有的信息。
最后,想要讓深度學(xué)習(xí)在基因組學(xué)研究中發(fā)揮巨大的作用,我們還有很長(zhǎng)的路要走。從生物科技上客服獲取數(shù)據(jù)的困難,從深度學(xué)習(xí)方面貼合特定問(wèn)題開(kāi)發(fā)合適的模型。我們應(yīng)謹(jǐn)記現(xiàn)有的困難和挑戰(zhàn),繼續(xù)推動(dòng)這個(gè)學(xué)科的發(fā)展。
-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5500瀏覽量
121117
原文標(biāo)題:深度學(xué)習(xí) + 基因組學(xué):破譯人類 30 億堿基對(duì)
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
ARM技術(shù)是什么?國(guó)內(nèi)有哪些ARM廠家呢?一起來(lái)了解一下!
重塑線控底盤技術(shù):自動(dòng)駕駛的未來(lái)支柱
30s高能速遞 | 第三屆 OpenHarmony技術(shù)大會(huì)精彩搶鮮看
單片機(jī)為什么被認(rèn)為是一門簡(jiǎn)單的技術(shù)?

碳化硅器件的應(yīng)用領(lǐng)域和技術(shù)挑戰(zhàn)
3個(gè)技巧揭秘:開(kāi)合屏技術(shù)如何改變未來(lái)!
EVASH Ultra EEPROM:被Google認(rèn)定為五大硬件廠商之一
干貨 | 一文讀懂國(guó)內(nèi)外傳感器技術(shù)及差距
多尺度浸入式3D打印策略,用于人體組織和器官的精準(zhǔn)制造
一文詳解超算中的InfiniBand網(wǎng)絡(luò)、HDR與IB

深圳比創(chuàng)達(dá)電子EMC|EMC電磁兼容技術(shù):原理、應(yīng)用與未來(lái)展望.
知語(yǔ)云智能科技揭秘:光學(xué)干擾技術(shù)全景解讀
請(qǐng)問(wèn)FCX3是認(rèn)到何種MIPI信號(hào),才會(huì)認(rèn)為是V_BLAKING?
小巧智能、低能耗的MEMS傳感器正在引領(lǐng)未來(lái)!





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論