 一種相對直接使用的distillation的變體方法
一種相對直接使用的distillation的變體方法
在提出備受矚目的“膠囊網絡”(Capsule networks)之后,深度學習領域的大牛、多倫多大學計算機科學教授Geoffrey Hinton近年在distillation這一想法做了一些前沿工作,包括Distill the Knowledge in a Neural Network等。今天我們介紹的是Hinton作為作者之一,谷歌大腦、DeepMind等的研究人員提交的distillation的更進一步工作:通過online distillation進行大規模分布式神經網絡訓練。該工作提出了Codistillation的概念,通過大規模實驗,發現codistillation方法提高了準確性并加快了訓練速度,并且易于在實踐中使用。
與幾乎任何基本模型配合時,諸如集成(ensembling)和蒸餾(distillation)等技術都可以提升模型的質量。但是,由于增加了測試時間成本(對于ensembling)和訓練pipeline的復雜性(對于distillation),這些技術在工業環境中使用具有挑戰性。
來自谷歌、谷歌大腦、DeepMind的研究人員,包括Geoffrey Hinton等人,在他們提交給ICLR 2018的論文“Large scale distributed neural network training through online distillation”中,探討了一種相對直接使用的distillation的變體方法,該方法不需要復雜的多級設置或非常多的新超參數。

研究者提出的第一個主張是:在線蒸餾(online distillation)使我們能夠使用額外的并行性來適應非常大的數據集,并且速度提高一倍。更重要的是,即使我們已經達到額外的并行性對同步或異步隨機梯度下降沒有好處的程度,我們仍然可以加快訓練速度。在不相交的數據子集上訓練的兩個神經網絡可以通過鼓勵每個模型同意另一個模型的預測來共享知識。這些預測可能來自另一個模型的舊版本,因此可以使用很少被傳輸的權重來安全地計算它們。
論文提出的第二個主張是:online distillation是一種成本效益高的方法,可以使模型的精確預測更具可重復性。研究者通過在Criteo Display Ad Challenge數據集,ImageNet和用于神經語言建模的最大數據集(包含6×1011個tokens)上進行實驗,支持了提出的這些主張。
Codistillation:優于分布式SGD
對于大規模的、具有商業價值的神經網絡訓練問題,如果訓練時間能夠大幅加快,或最終模型的質量能夠大幅提高,從業者會愿意投入更多的機器用于訓練。目前,分布式隨機梯度下降(SGD),包括其同步和異步形式(Chen et al.,2016)是在多個互聯機器上進行大規模神經網絡訓練的主要算法。但是,隨著機器數量的增加,訓練一個高質量模型所需時間的改善程度會降低,直到繼續增加機器卻無法進一步縮短訓練時間。基礎架構的限制,以及優化上的障礙,一起限制了分布式 minibatch SGD的可擴展性。
分布式SGD的精確可擴展性限制將取決于算法的實現細節,基礎架構的具體情況以及硬件的能力,但根據我們的經驗,在實際設置中,在超過100臺GPU workers上進行有效擴展可能非常困難。沒有任何訓練神經網絡的算法可以無限擴展,但即使擴展得比分布式SGD的限制多一點,也是非常有價值的。
一旦我們達到了向分布式SGD添加worker的限制,我們就可以使用額外的機器來訓練模型的另一個副本,并創建一個集成(ensemble)以提高準確性(或通過以更少的step訓練ensemble中的成員來提高訓練時的精度)。ensemble能夠做出更穩定和可重復的預測,這在實際應用中很有用。但是,ensemble增加了測試時的成本,可能會影響延遲或其他成本限制。
為了在不增加測試時間成本的情況下獲得幾乎與ensemble相同的好處,我們可以對一個n-way模型的ensemble進行蒸餾(distill),得到一個單一模型,這包括兩個階段:首先我們使用nM機器來訓練分布式SGD的n-way ensemble,然后使用M機器來訓練student網絡,以模擬n-way ensemble。通過在訓練過程中增加另一個階段并使用更多機器,distill一般會增加訓練時間和復雜性,以換取接近更大的 teacher ensemble 模型的質量改進。
我們認為,從時間和pipeline復雜性兩方面來看,額外的訓練成本阻礙了從業者使用ensemble distillation,盡管這種方法基本上總是能夠改善結果。在這項新的工作中,我們描述了一個簡單的distillation的在線變體,我們稱之為codistillation。Codistillation通過向第i個模型的損失函數添加一個項來匹配其他模型的平均預測值,可以并行訓練n個模型的副本。
通過大規模實驗,我們發現,與分布式SGD相比,通過允許有效利用更多計算資源,codistillation提高了準確性并加快了訓練速度,甚至加速效果超過了給SGD方法添加更多worker。具體來說,codistillation提供了在不增加訓練時間的情況下distill一個模型ensemble的好處。與Multi-phase的distillation訓練過程相比,Codistillation在實踐中使用也相當簡單。
這項工作的主要貢獻是codistillation的大規模實驗驗證。另一個貢獻是,我們探索了不同的設計選擇和codistillation的實現考慮因素,提出了實用的建議。
總的來說,我們認為在實踐中,codistillation比精心調參的offline distillation得到的質量提升是次要的,更有趣的研究方向是將codistillation作為一種分布式訓練算法來研究。
在這篇論文中,我們使用codistillation來指代執行的distillation:
所有模型使用相同的架構;
使用相同的數據集來訓練所有模型;
在任何模型完全收斂之前使用訓練期間的distillation loss。

codistillation算法
實驗與結果
為了研究分布式訓練的可擴展性,我們需要一個代表重要的大規模神經網絡訓練問題的任務。神經語言建模是一個理想的測試平臺,因為網絡上有大量的文本,并且也因為神經語言模型的訓練成本可能非常高。神經語言模型是實現分布式SGD(如機器翻譯和語音識別)常用重要問題的代表,但是語言建模更容易評估和使用更簡單的管線。為了盡可能清晰地提高潛在的可擴展性,我們選擇了一個足夠大的數據集,它完全不可能通過現有的SGD并行化策略來訓練一個表達模型。為了證實我們的結果并不是特定于語言建模的某些特性,我們也驗證了我們在ImageNet (Russakovsky et al., 2015)上的一些大規模的codistillation結果。為了證明在減少預測過程中進行編碼的好處,并研究算法的其他特性,我們可以使用更小的更便宜的實驗,但在研究可擴展性時,真正達到分布式SGD的極限是很重要的。
1. 達到分布式SGD的極限,用于在Common Crawl上訓練RNN
在我們的第一組實驗中,我們的目標是大致確定在我們的Common Crawl神經語言模型設置中可以有效使用SGD的GPU的最大數量。由于我們的數據集比英文維基百科數據量大兩個數量級,因此不用擔心重新訪問數據,即使在相對較大規模的實驗中,這也會使獨立副本更加相似。我們嘗試使用32和128個workers的異步SGD,在必要的情況下,通過增加參數服務器的數量來分配權重,以確保訓練速度被GPU計算時間瓶頸。我們發現很難保持訓練的穩定性,并防止RNNs與大量GPU的異步SGD出現差異。我們嘗試了一些workers提升計劃和不同的學習速率,但最終決定將重點放在同步算法上,使我們的結果更少地依賴于我們的基礎結構和實現的特定特性。梯度的穩定性很難獨立于特定的條件下進行分析,而實現和基礎結構的差異更容易抽象為同步SGD。雖然可能需要更多的努力使異步工作良好,但陳舊的漸變對學習進度的削弱作用是一個眾所周知的問題,Mitliagkas等人(2016)認為,異步可以有效地增加動量,這也是為什么它容易分化的原因。在初步實驗中,從codistillation中獲得的收益似乎與選擇異步或同步SGD作為基本算法無關。
可同時用于同步SGD的最大GPU的數量取決于基礎架構限制、尾延遲和批處理大小的影響。完全同步的SGD相當于批量大得多的單機算法。增加有效的批量大小可減少梯度估計中的噪聲,從而允許更大的步長,并有望實現更高質量的更新,從而實現更快的收斂速度。鑒于有效的無限訓練數據(即使使用256個GPU,我們也不訪問所有常見爬網訓練數據),我們直觀地預計會增加有效批量,最終增加步驟時間。我們采用完全同步的SGD在Common Crawl上訓練了語言模型,并使用128和32,64,128和256GPU的批處理大小。因此,有效的批量大小范圍為4096至32768.一般來說,我們應該期望需要增加學習率,因為我們增加了有效的批量大小,所以對于每個GPU我們嘗試的學習率為0.1,0.2和0.4。對于32和64GPU,0.1表現最好,因為原先的三種學習率都沒有對256GPU表現良好,我們還嘗試了0.3的額外中級學習率,這是256的最佳表現學習率。
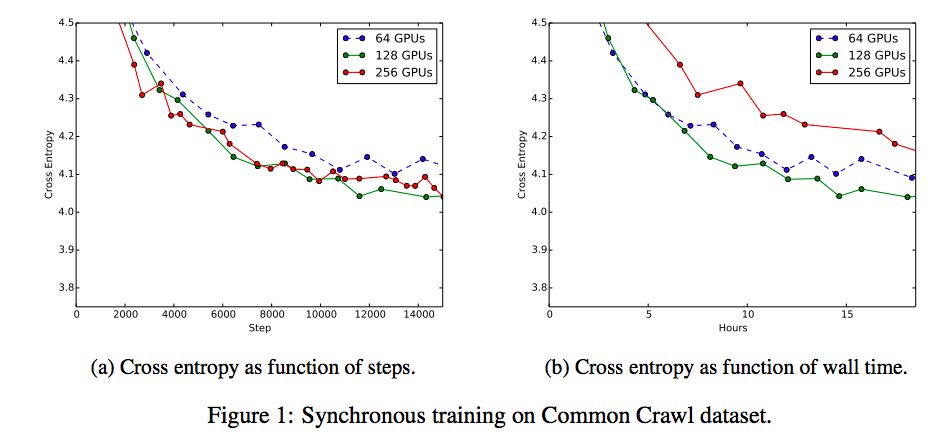
圖1a將驗證誤差作為我們嘗試過的不同數量的GPU的全局步驟的函數,使用了每個GPU數量的最佳學習速率。增加數量(因此有效的批處理大小)減少了達到最佳驗證錯誤所需的步驟數,直到128GPU,在這一點上沒有額外的改進。圖1b對相同數量的同步GPU的驗證誤差與Wall time進行對比。在這些特殊的實驗中,與128個GPU同步的SGD是訓練時間和最終準確度方面最強的基線。因此,我們將其余實驗集中在與128位同步SGD進行比較,并研究使用同步SGD作為子程序的codistillation,但它也適用于異步算法。
2. 帶同步SGD的CODISTILLATION
對于Common Crawl上的語言建模,具有128GPU的同步SGD實現了標準分布式訓練的最佳結果,至少是我們嘗試過的配置,并且我們無法使用256個GPU來提高訓練時間。雖然額外的GPU似乎不能幫助基本的同步SGD,但我們的假設是,如果我們使用兩組128GPU(使用同步SGD定期交換檢查點)雙向codistillation,那么額外的128GPU將提高訓練時間。
一個問題是,codistillation僅僅是一種懲罰確信輸出分布(penalizing confident output distributions)或平滑標簽的方法,所以我們也將其與兩個標簽平滑基線進行比較。第一個基線用符合統一分配的術語代替codistillation損失術語,第二個基線使用與使用一個與unigram分布相匹配的術語。在初步實驗中手動調整權衡超參數。另一個重要的比較是兩個神經網絡的集成,每個神經網絡都有128GPU和同步SGD。
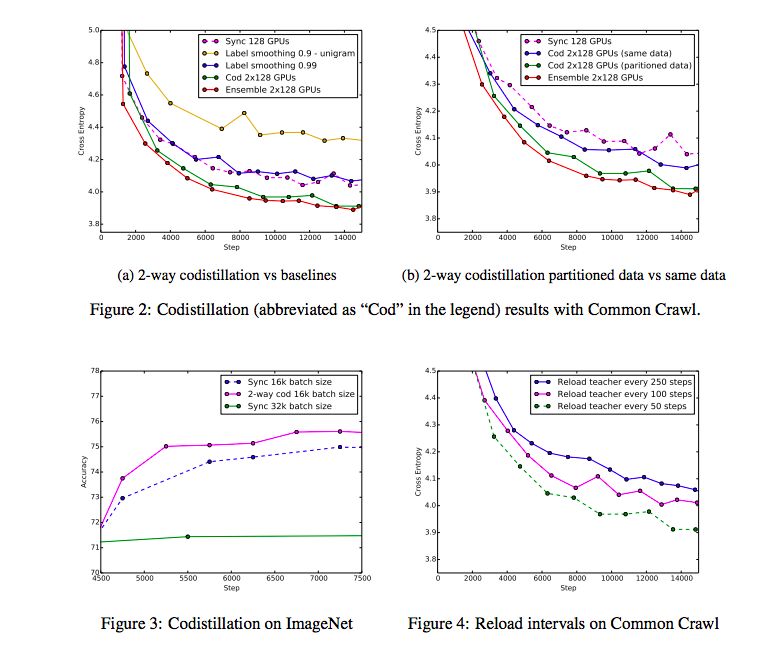
圖2a利用128個GPU的兩個組,以及同步SGD的訓練曲線和標簽平滑基線(每個使用128個GPU)和一個包含128個GPU基線的兩個實例的訓練曲線,繪制了驗證交叉信息和同步訓練的步驟。
討論和未來的工作
Distillation是一種非常靈活的工具,尤其是在模型訓練過程期間而不是之后進行。它可用于加速培訓、提高質量,以新的、更有效的溝通方式下進行訓練,并減少預測的流失。然而,我們仍有許多問題需要探討。例如,我們主要關注對彼此進行codistilling的模型對上。如果成對是有用的,那么其他拓撲也是有用的。完全連接的圖形可能使模型過于相似,太快以至于環形結構也可能變得有趣。我們也沒有探究teacher models預測的準確性的局限性。也許可以對teacher models進行積極的量化,使其在很大程度上與普通訓練一樣廉價,即使是非常大的模型。
有些矛盾的是,壞模型之間codistilling可以比獨立的模型訓練更快地學習。從某種程度上講,teacher models所犯的錯誤可以幫助student model做得更好,而且比僅僅看到數據中的實際標簽要好。描述teacher models的理想特性是未來工作的一個令人興奮的途徑。在這項工作中,我們只從檢查點提取預測,因為預測是可識別的,而且不像網絡的內部結構,沒有虛假的對稱。也就是說,從一個檢查點提取更多信息可能比僅僅預測沒有觸及到工作人員交流梯度的相同問題,允許使用teacher models作為更強的調節者。也許可以用基于codistillation的方法來增強McMahan等人(2017)提出的在帶寬受限的設置環境下的聯合學習。
-
神經網絡
+關注
關注
42文章
4773瀏覽量
100877 -
深度學習
+關注
關注
73文章
5506瀏覽量
121259
原文標題:Hinton膠囊網絡后最新研究:用“在線蒸餾”訓練大規模分布式神經網絡
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
榮小菜補鈣記第19期:數據操作之變體數據提取
一種伺服電機的控制方法
YOLOv6中的用Channel-wise Distillation進行的量化感知訓練
一種實用的電爐控溫方法
一種改進直接轉矩控制性能的方法
Yahalom協議及其變體的時序缺陷分析與改進
一種直接強度解調應用分析

一種自動生成反向傳播方程的方法

一種結合相對信息熵的改進LEACH協議






 工商網監
工商網監
評論