 AI工程師需要懂架構嗎?帶你詳細了解
AI工程師需要懂架構嗎?帶你詳細了解
AI 時代,我們總說做科研的 AI 科學家、研究員、算法工程師離產業應用太遠,這其中的一個含義是說,搞機器學習算法的人,有時候會因為缺乏架構(Infrastructure)方面的知識、能力而難以將一個好的算法落地。我們招的算法工程師里,也有同學說,我發的頂會 paper 一級棒,或者我做 Kaggle 競賽一級棒,拿了不少第一名的,不懂架構就不懂唄,我做出一流算法,自然有其他工程師幫我上線、運行、維護的。
鑒于此,我給創新工場暑期深度學習訓練營 DeeCamp (ps:這個訓練營太火了,只招生 36 名,總共有 1000 多計算機專業同學報名,同學們來自 CMU、北大、清華、交大等最好的大學)設計培訓課程時,就刻意把第一節課安排為《AI 基礎架構:從大數據到深度學習》,后續才給大家講《TensorFlow 實戰》、《自然語言處理》、《機器視覺》、《無人駕駛實戰》等框架和算法方向的課。
為什么我要說,AI 工程師都要懂一點架構呢?大概有四個原因吧:
▌原因一:算法實現 ≠ 問題解決
學生、研究員、科學家關心的大多是學術和實驗性問題,但進入產業界,工程師關心的就是具體的業務問題。簡單來說,AI 工程師扮演的角色是一個問題的解決者,你的最重要任務是在實際環境中、有資源限制的條件下,用最有效的方法解決問題。只給出結果特別好的算法,是遠遠不夠的。
比如一些算法做得特別好,得過 ACM 獎項或者 Kaggle 前幾名的學生到了產業界,會驚奇地發現,原來自己的動手能力還差得這么遠。做深度學習的,不會裝顯卡驅動,不會修復 CUDA 安裝錯誤;搞機器視覺的,沒能力對網上爬來的大規模訓練圖片、視頻做預處理或者格式轉換;精通自然語言處理的,不知道該怎么把自己的語言模型集成在手機聊天 APP 里供大家試用……
當然可以說,做算法的專注做算法,其他做架構、應用的幫算法工程師做封裝、發布和維護工作。但這里的問題不僅僅是分工這么簡單,如果算法工程師完全不懂架構,其實,他根本上就很難在一個團隊里協同工作,很難理解架構、應用層面對自己的算法所提出的需求。
▌原因二:問題解決 ≠ 現場問題解決
有的算法工程師疏于考慮自己的算法在實際環境中的部署和維護問題,這個是很讓人頭疼的一件事。面向 C 端用戶的解決方案,部署的時候要考慮 serving 系統的架構,考慮自己算法所占用的資源、運行的效率、如何升級等實際問題;面向 B 端用戶的解決方案要考慮的因素就更多,因為客戶的現場環境,哪怕是客戶的私有云環境,都會對你的解決方案有具體的接口、格式、操作系統、依賴關系等需求。
有人用 Python 3 做了算法,沒法在客戶的 Python 2 的環境中做測試;有人的算法只支持特定格式的數據輸入,到了客戶現場,還得手忙腳亂地寫數據格式轉換器、適配器;有人做了支持實時更新、自動迭代的機器學習模型,放到客戶現場,卻發現實時接收 feature 的接口與邏輯,跟客戶內部的大數據流程根本不相容……
部署和維護工程師會負責這些麻煩事,但算法工程師如果完全不懂得或不考慮這些邏輯,那只會讓團隊內部合作越來越累。
▌原因三:工程師需要最快、最好、最有可擴展性地解決問題
AI 工程師的首要目的是解決問題,而不是顯擺算法有多先進。很多情況下,AI 工程師起碼要了解一個算法跑在實際環境中的時候,有哪些可能影響算法效率、可用性、可擴展性的因素。
比如做機器視覺的都應該了解,一個包含大量小圖片(比如每個圖片 4KB,一共 1000 萬張圖片)的數據集,用傳統文件形式放在硬盤上是個怎樣的麻煩事,有哪些更高效的可替代存儲方案。做深度學習的有時候也必須了解 CPU 和 GPU 的連接關系,CPU/GPU 緩存和內存的調度方式,等等,否則多半會在系統性能上碰釘子。
擴展性是另一個大問題,用 AI 算法解決一個具體問題是一回事,用 AI 算法實現一個可擴展的解決方案是另一回事。要解決未來可能出現的一大類相似問題,或者把問題的邊界擴展到更大的數據量、更多的應用領域,這就要求 AI 工程師具備最基本的架構知識,在設計算法時,照顧到架構方面的需求了。
▌原因四:架構知識,是工程師進行高效團隊協作的共同語言
AI 工程師的確可以在工作時專注于算法,但不能不懂點兒架構,否則,你跟其他工程師該如何協同工作呢?
別人在 Hadoop 里搭好了 MapReduce 流程,你在其中用 AI 算法解決了一個具體步驟的數據處理問題(比如做了一次 entity 抽取),這時其他工程師里讓你在算法內部輸出一個他們需要監控的 counter——不懂 MapReduce 的話,你總得先去翻查、理解什么是 counter 吧。這個例子是芝麻大點兒的小事,但小麻煩是會日積月累,慢慢成為團隊協作的障礙的。往大一點兒說,系統內部到底該用 protocol buffers 還是該用 JSON 來交換數據,到底該用 RPC 還是該用 message queue 來通信,這些決定,AI 工程師真的都逆來順受、不發表意見了?
▌Google 的逆天架構能力是 Google AI 科技強大的重要原因
這個不用多解釋,大家都知道。幾個現成的例子:
(1)在前 AI 時代,做出 MapReduce 等大神級架構的 Jeff Dean(其實嚴格說,應該是以 Jeff Dean 為代表的 Google 基礎架構團隊),也是現在 AI 時代里的大神級架構 TensorFlow 的開發者。
(2)在 Google 做無人駕駛這類前沿 AI 研發,工程師的幸福感要比其他廠的工程師高至少一個數量級。比如做無人駕駛的團隊,輕易就可以用已有的大數據架構,管理超海量的 raw data,也可以很簡單的在現有架構上用幾千臺、上萬臺機器快速完成一個代碼更新在所有已收集的路況數據上的回歸測試。離開這些基礎架構的支持,Google 這幾年向 AI 的全面轉型哪會有這么快。
▌課件分享:AI 基礎架構——從大數據到深度學習
下面是我給創新工場暑期深度學習訓練營 DeeCamp 講的時長兩小時的內部培訓課程《AI 基礎架構:從大數據到深度學習》的全部課件。全部講解內容過于細致、冗長,這里就不分享了。對每頁課件,我在下面只做一個簡單的文字概括。
注:以下這個課件的講解思路主要是用 Google 的架構發展經驗,對大數據到機器學習再到近年來的深度學習相關的典型系統架構,做一個原理和發展方向上的梳理。因為時間關系,這個課件和講解比較偏重 offline 的大數據和機器學習流程,對 online serving 的架構討論較少——這當然不代表 online serving 不重要,只是必須有所取舍而已。

這個 slides 是最近三四年的時間里,逐漸更新、逐漸補充形成的。最早是英文講的,所以后續補充的內容就都是英文的(英文水平有限,錯漏難免)。

如何認識 AI 基礎架構的問題,直到現在,還是一個見仁見智的領域。這里提的,主要是個人的理解和經驗,不代表任何學術流派或主流觀點。
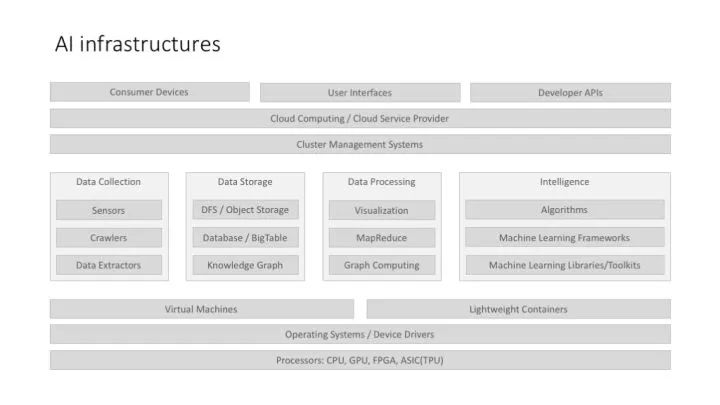
上面這個圖,不是說所有 AI 系統/應用都有這樣的 full stack,而是說,當我們考慮 AI 基礎架構的時候,我們應該考慮哪些因素。而且,更重要的一點,上面這個架構圖,是把大數據架構,和機器學習架構結合在一起來討論的。
架構圖的上層,比較強調云服務的架構,這個主要是因為,目前的 AI 應用有很大一部分是面向 B 端用戶的,這里涉及到私有云的部署、企業云的部署等云計算相關方案。
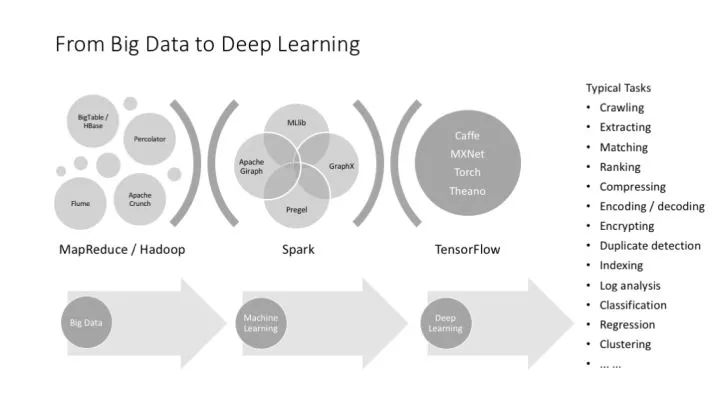
上面這個圖把機器學習和深度學習并列,這在概念上不太好,因為深度學習是機器學習的一部分,但從實踐上講,又只好這樣,因為深度學習已經枝繁葉茂,不得不單提出來介紹了。

先從虛擬化講起,這個是大數據、AI 甚至所有架構的基礎(當然不是說所有應用都需要虛擬化,而是說虛擬化目前已經太普遍了)。
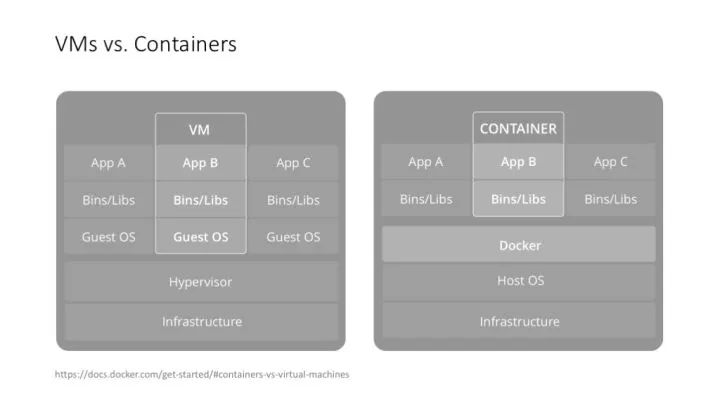
這個是 Docker 自己畫的 VM vs. Container 的圖。我跟 DeeCamp 學員講這一頁的時候,是先從 Linux 的 chroot 命令開始講起的,然后才講到輕量級的 container 和重量級的 VM,講到應用隔離、接口隔離、系統隔離、資源隔離等概念。
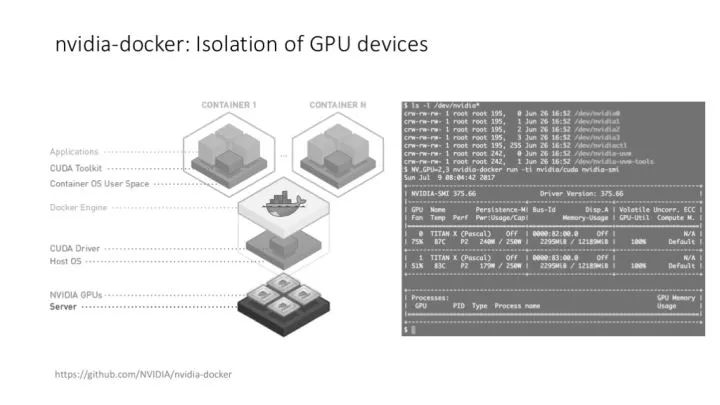
給 DeeCamp 學員展示了一下 docker(嚴格說是 nvidia-docker)在管理 GPU 資源上的靈活度,在搭建、運行和維護 TensorFlow 環境時為什么比裸的系統方便。
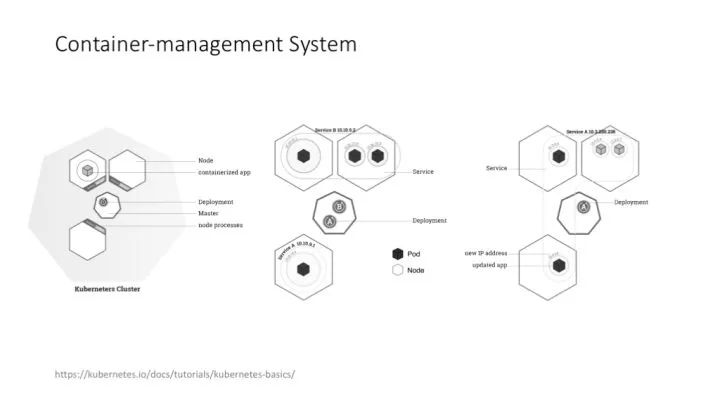
嚴格說,Kubernetes 現在的應用遠沒有 Docker 那么普及,但很多做機器學習、深度學習的公司,包括創業公司,都比較需要類似的 container-management system,需要自動化的集群管理、任務管理和資源調度。

講大數據架構,我基本上會從 Google 的三架馬車(MapReduce、GFS、Bigtable)講起,盡管這三架馬車現在看來都是“老”技術了,但理解這三架馬車背后的設計理念,是更好理解所有“現代”架構的一個基礎。
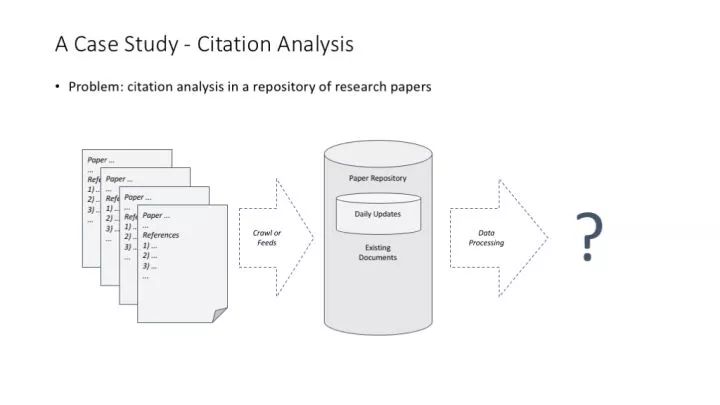
講 MapReduce 理念特別常用的一個例子,論文引用計數(正向計數和反向計數)問題。
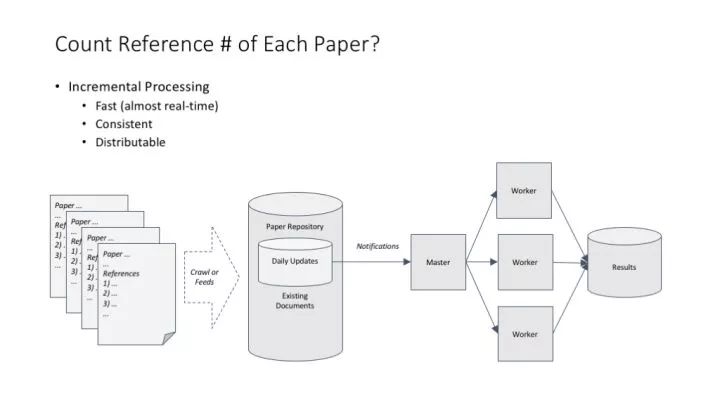
統計一篇論文有多少參考文獻,這個超級簡單的計算問題在分布式環境中帶來兩個思考:(1)可以在不用考慮結果一致性的情況下做簡單的分布式處理;(2)可以非常快地用增量方式處理數據。
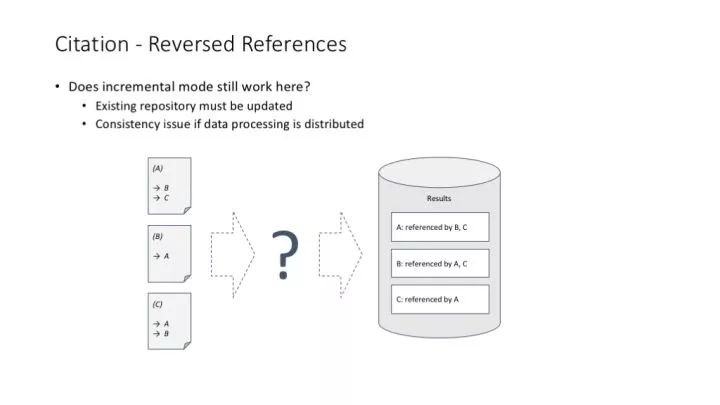
但是,當我們統計一篇文獻被多少篇論文引用的時候,這個事情就不那么簡單了。這主要帶來了一個分布式任務中常見的數據訪問一致性問題(我們說的當然不是單線程環境如何解決這個問題啦)。

很久以前我們是用關系型數據庫來解決數據訪問一致性的問題的,關系型數據庫提供的 Transaction 機制在分布式環境中,可以很方便地滿足 ACID(Atomicity, Consistency, Isolation, Durability) 的要求。但是,關系型數據庫明顯不適合解決大規模數據的分布式計算問題。
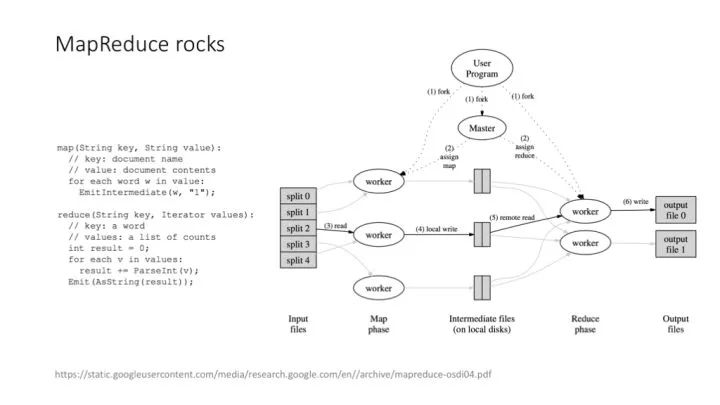
Google 的 MapReduce 解決這個問題的思路非常巧妙,是計算機架構設計歷史上絕對的經典案例:MapReduce 把一個可能帶來 ACID 困擾的事務計算問題,拆解成 Map 和 Reduce 兩個計算階段,每個單獨的計算階段,都特別適合做分布式處理,而且特別適合做大規模的分布式處理。
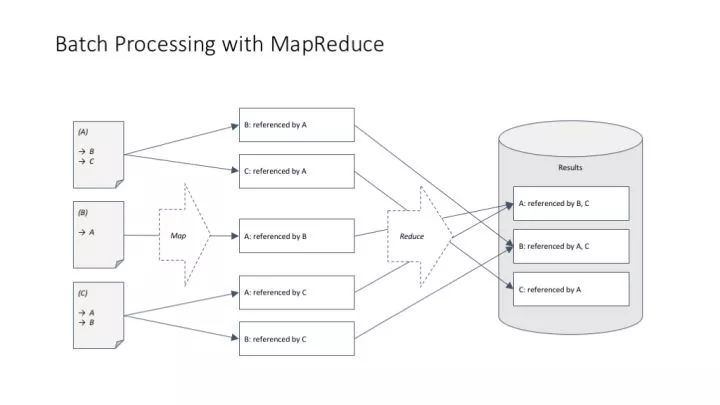
MapReduce 解決引用計數問題的基本框架。
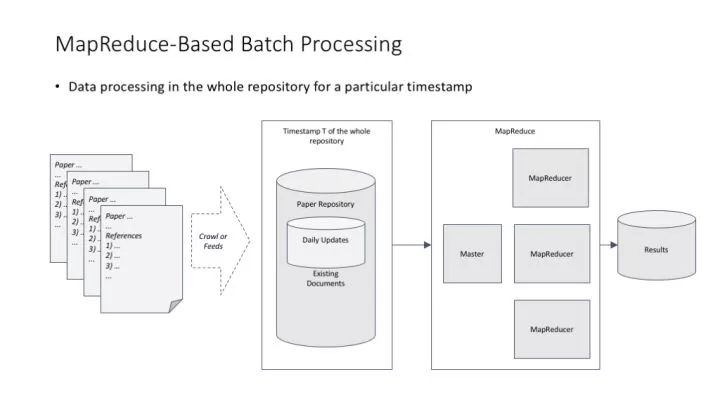
MapReduce 在完美解決分布式計算的同時,其實也帶來了一個不大不小的副作用:MapReduce 最適合對數據進行批量處理,而不是那么適合對數據進行增量處理。比如早期 Google 在維護網頁索引這件事上,就必須批量處理網頁數據,這必然造成一次批量處理的耗時較長。Google 早期的解決方案是把網頁按更新頻度分成不同的庫,每個庫使用不同的批量處理周期。
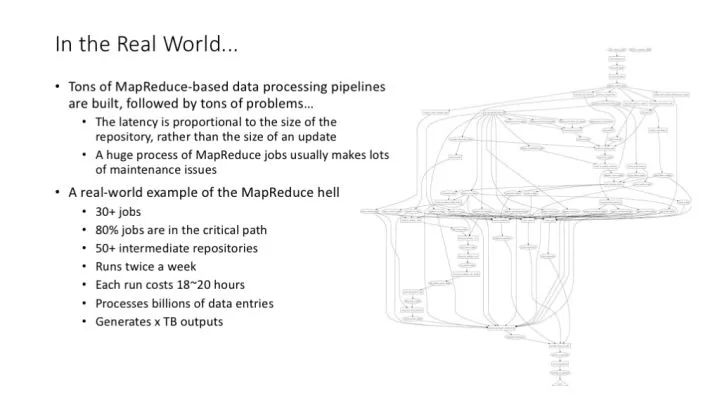
用 MapReduce 帶來的另一個問題是,常見的系統性問題,往往是由一大堆 MapReduce 操作鏈接而成的,這種鏈接關系往往形成了復雜的工作流,整個工作流的運行周期長,管理維護成本高,關鍵路徑上的一個任務失敗就有可能要求整個工作流重新啟動。不過這也是 Google 內部大數據處理的典型流程、常見場景。

Flume 是簡化 MapReduce 復雜流程開發、管理和維護的一個好東東。

Apache 有開源版本的 Flume 實現。Flume 把復雜的 Mapper、Reducer 等底層操作,抽象成上層的、比較純粹的數據模型的操作。PCollection、PTable 這種抽象層,還有基于這些抽象層的相關操作,是大數據處理流程進化道路上的重要一步(在這個角度上,Flume 的思想與 TensorFlow 對于 tensor 以及 tensor 數據流的封裝,有異曲同工的地方)。
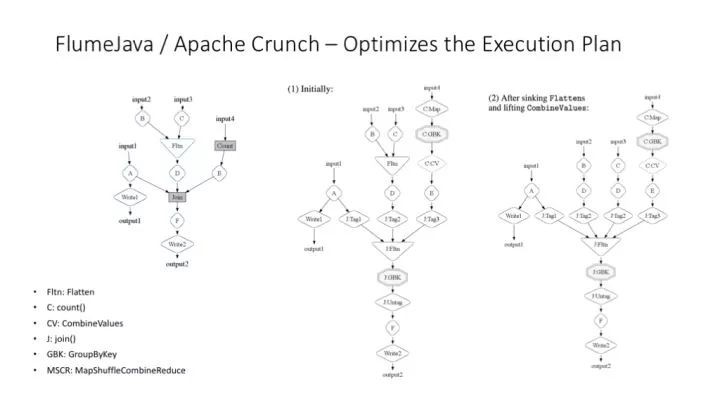
Flume 更重要的功能是可以對 MapReduce 工作流程進行運行時的優化。
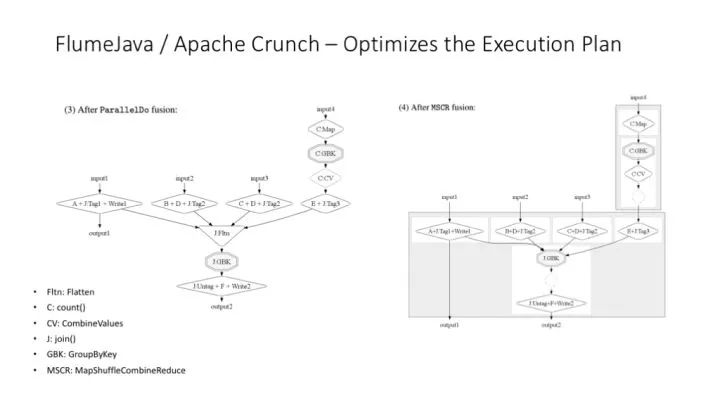
更多關于 Flume 運行時優化的解釋圖。

Flume 并沒有改變 MapReduce 最適合于批處理任務的本質。那么,有沒有適合大規模數據增量(甚至實時)處理的基礎架構呢?
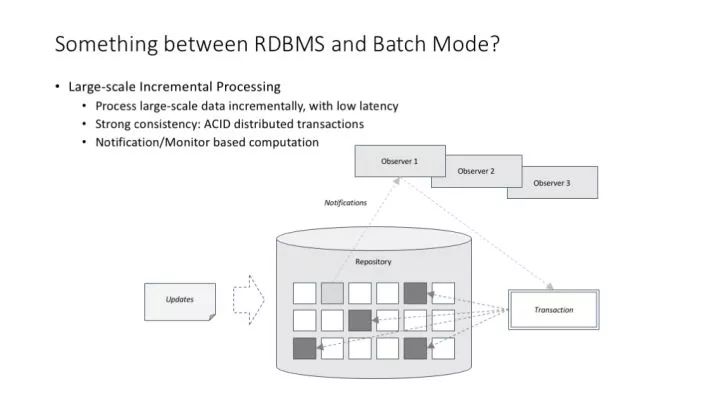
談到大規模數據增量(甚至實時)處理,我們談的其實是一個兼具關系型數據庫的 transaction 機制,以及 MapReduce 的可擴展性的東西。這樣的東西有不同的設計思路,其中一種架構設計思路叫 notification/monitor 模式。
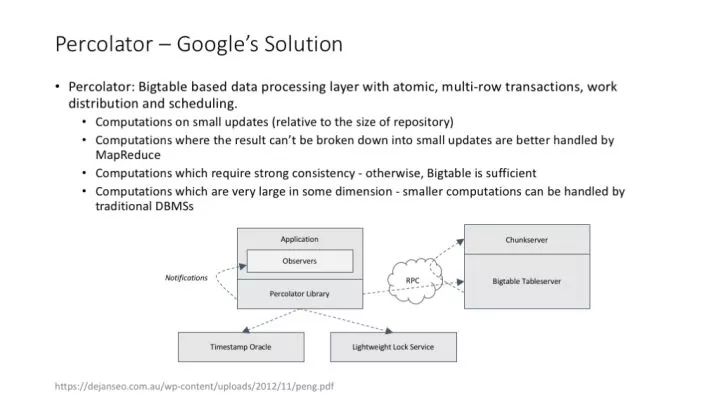
Google percolator 的論文給出了 notification/monitor 模式的一種實現方案。這個方案基于Bigtable,實際上就是在 Bigtable 超靠譜的可擴展性的基礎上,增加了一種非常巧妙實現的跨記錄的 transaction 機制。

percolator 支持類似關系型數據庫的 transaction,可以保證同時發生的分布式任務在數據訪問和結果產出時的一致性。
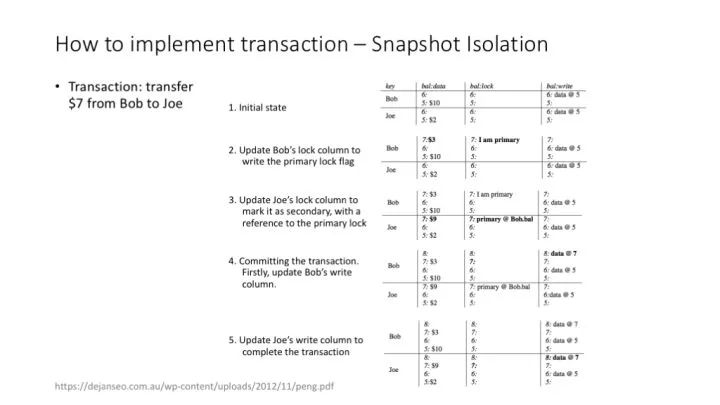
percolator 實現 transaction 的方法:(1)使用 timestamp 隔離不同時間點的操作;(2)使用 write、lock 列實現 transaction 中的鎖功能。詳細的介紹可以參考 percolator 的 paper。
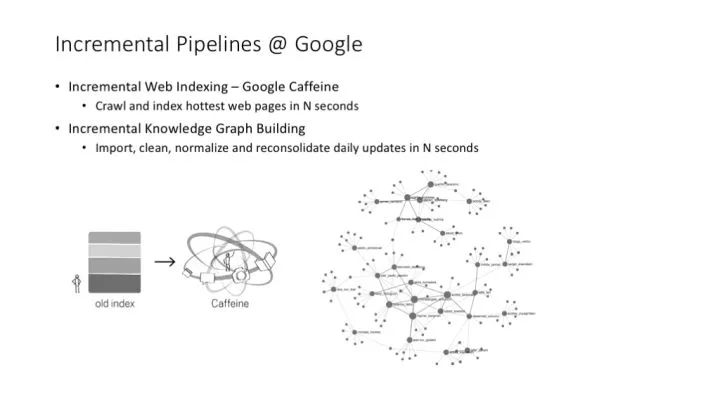
Google 的網頁索引流程、Google Knowledge Graph 的創建與更新流程,都已經完成了增量化處理的改造,與以前的批處理系統相比,可以達到非常快(甚至近乎實時)的更新速度。——這個事情發生在幾年以前,目前 Google 還在持續對這樣的大數據流程進行改造,各種新的大數據處理技術還在不停出現。

大數據流程建立了之后,很自然地就會出現機器學習的需求,需要適應機器學習的系統架構。

MapReduce 這種適合批處理流程的系統,通常并不適合于許多復雜的機器學習任務,比如用 MapReduce 來做圖的算法,特別是需要多次迭代的算法,就特別耗時、費力。
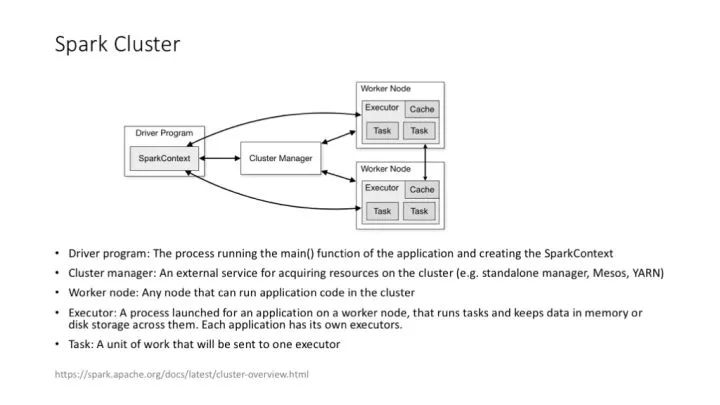
Spark 以及 Spark MLlib 給機器學習提供了更好用的支持框架。Spark 的優勢在于支持對 RDD 的高效、多次訪問,這幾乎是給那些需要多次迭代的機器學習算法量身定做的。
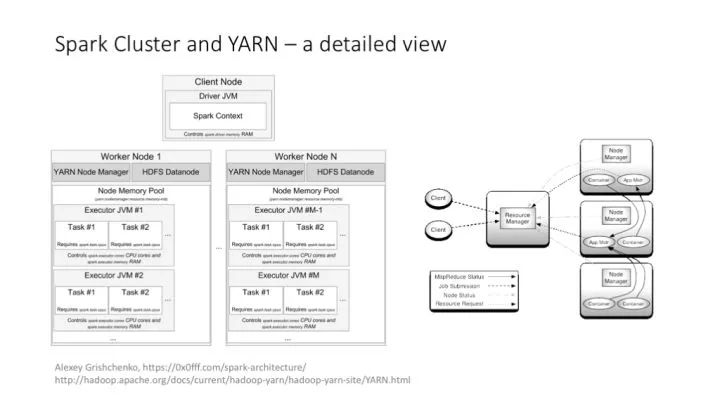
Spark 的集群架構,和 YARN 的集成等。

Google Pregel 的 paper 給出了一種高效完成圖計算的思路。

Spark GraphX 也是圖計算的好用架構。

深度學習的分布式架構,其實是與大數據的分布式架構一脈相承的。——其實在 Google,Jeff Dean 和他的架構團隊,在設計 TensorFlow 的架構時,就在大量使用以往在 MapReduce、Bigtable、Flume 等的實現中積累的經驗。
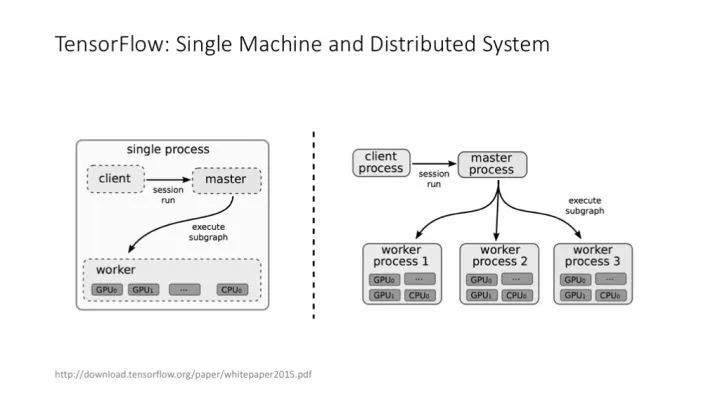
TensorFlow 經典論文中對 TensorFlow 架構的講解。
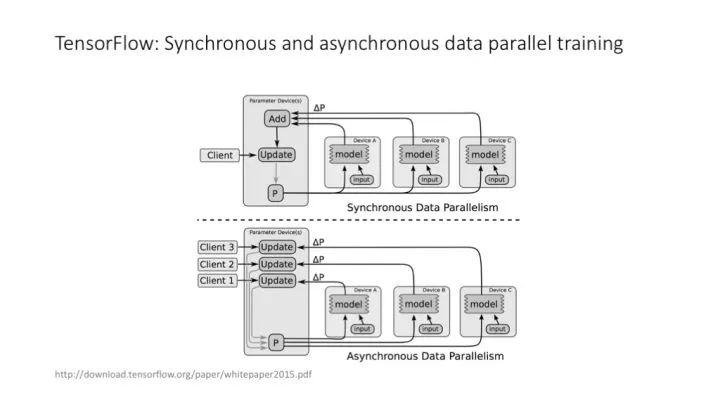
TensorFlow 中的同步訓練和異步訓練。
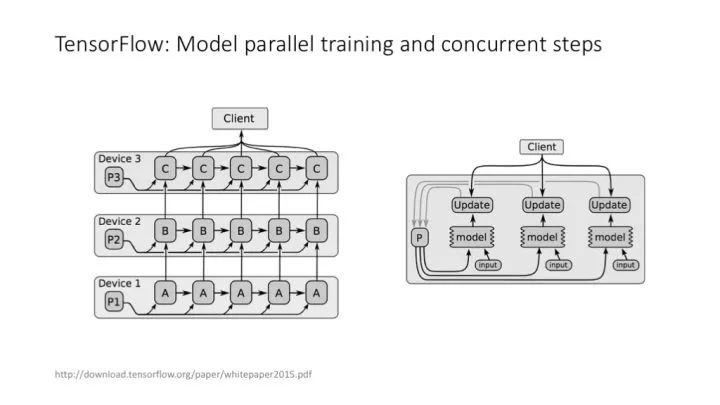
TensorFlow 中的不同的并行策略。

可視化是個與架構有點兒關系,但更像一個 feature 的領域。對機器學習特別是深度學習算法的可視化,未來會變得越來越重要。
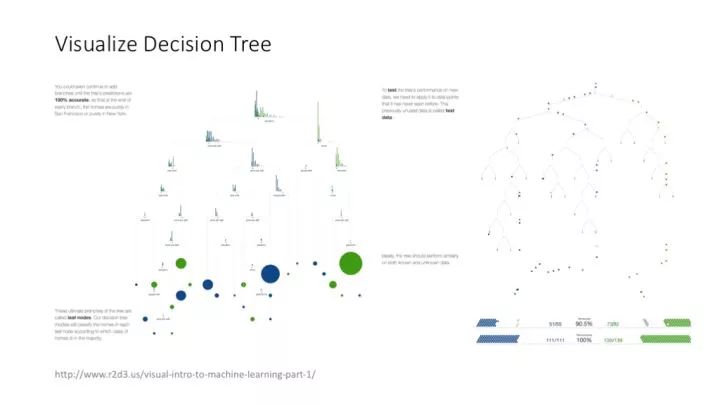
這個對決策樹算法進行可視化的網站,非常好玩。
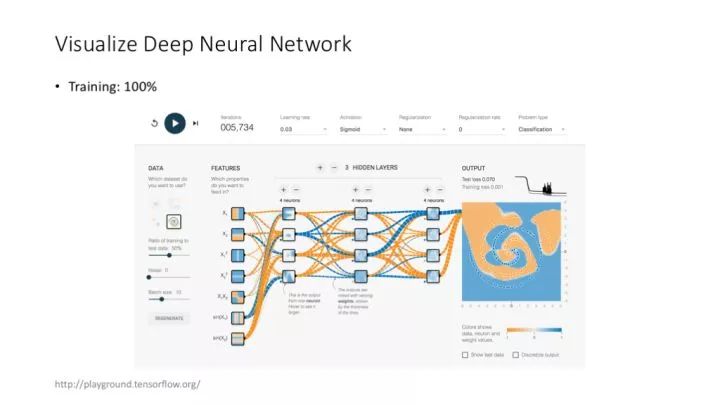
TensorFlow 自己提供的可視化工具,也非常有意思(當然,上圖應用屬于玩具性質,不是真正意義上,將用戶自己的模型可視化的工具)。

-
架構
+關注
關注
1文章
517瀏覽量
25507
原文標題:為什么 AI 工程師要懂一點架構?
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

為什么嵌入式驅動開發工程師可以拿高薪?
詳細了解驍龍8至尊版強大的AI能力




一文帶你詳細了解工業電腦



嵌入式軟件工程師和硬件工程師的區別?








 工商網監
工商網監
評論