") 語音識別任務中除了模型以外的可以提升性能的技巧
語音識別任務中除了模型以外的可以提升性能的技巧
端對端語音識別改進的規(guī)則技巧
對于端對端模型來說,通過數(shù)據(jù)增強和Dropout的方法可以提高模型的性能。在語音識別中也是如此,之前,我公眾號沒有寫過關于語音識別任務的數(shù)據(jù)增強的技巧,最近做了大規(guī)模的語音識別實踐發(fā)現(xiàn),數(shù)據(jù)增強對于小數(shù)據(jù)集而言簡直就是雪中送炭,當然,如果你擁有大體量的數(shù)萬小時的語音數(shù)據(jù)庫,而且又能囊括全國各地不同口音風格,那么數(shù)據(jù)增強理論上也能起到錦上添花的作用。今天基于Salesforce Research的這篇文章以及自己平時的實踐經(jīng)驗,來分享一下語音識別任務中除了模型以外的可以提升性能的技巧。
這篇論文中提到,通過對音頻的速度、音調(diào)、音量、時間對齊進行微小的擾動,以及通過增加高斯白噪聲來對音頻進行改動,同時,文章也探討了在每一層神經(jīng)網(wǎng)絡上采用dropout所帶來的效果。實驗結(jié)果表明,通過將數(shù)據(jù)增強技術(shù)與dropout聯(lián)合使用,可以將語音識別模型的性能在WSJ數(shù)據(jù)庫上和LibriSpeech數(shù)據(jù)庫上相比baseline系統(tǒng)提高20%以上,從結(jié)果上看,這些規(guī)則化技巧對語音識別的性能改進有很大的幫助。我們先看一下作者基于什么模型來實踐這些數(shù)據(jù)增強的技巧。
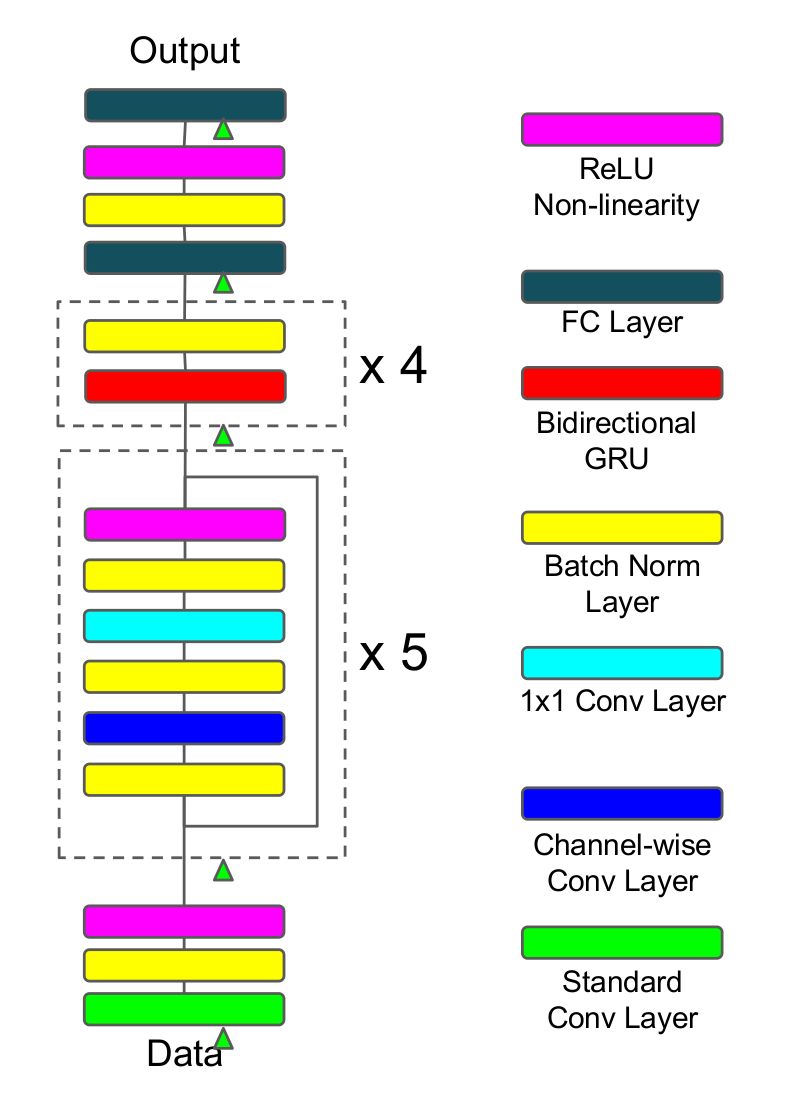
本文使用的端對端模型非常接近于百度提出的Deep Speech2 (DS2),如上圖所示,原始特征數(shù)據(jù)首先經(jīng)過一個較大卷積核的卷積層,卷積核較大的好處就是對原始特征進行降維,降維以后通過5個殘差連接區(qū),而每一個殘差區(qū)都是由批歸一化層、channel-wise卷積層和1×1的卷積層構(gòu)成,并通過relu激活函數(shù),緊接著連上4個雙向GRU網(wǎng)絡,最終通過全連接層得到目標概率分布,并采取端對端的CTC損失函數(shù)作為目標函數(shù),使用隨機梯度下降算法來進行優(yōu)化。這里相比DS2所做的創(chuàng)新主要是channel-wise可分離的卷積層,其實就是depth-wise可分離卷積層,它相比常規(guī)的卷積具有性能好、參數(shù)減少的優(yōu)勢,它們在參數(shù)數(shù)量上的區(qū)別可以通過下面的例子看得出來(具體關于可分離卷積的介紹,可以搜索xception這篇文章):
假設現(xiàn)在要做一個卷積,輸入深度是128,輸出深度是256;常規(guī)的操作使用卷積核3×3進行卷積,那么參數(shù)數(shù)目為128×3×3×256=294912;depth-wise可分離卷積的操作是設置depth multiplier=2得到深度為2×128的中間層,再經(jīng)過1×1的卷積層降維到深度為256,參數(shù)數(shù)目為128×3×3×2+128×2×1×1×256=67840,可以看到相比常規(guī)卷積,參數(shù)減少了77%;
除了使用了depth-wise可分離卷積層以外,殘差連接以及在每一層上都采取了批歸一化的技巧對訓練有促進作用,整個網(wǎng)絡共有約500萬個參數(shù)。參數(shù)太大就容易出現(xiàn)過擬合的問題,為了避免過擬合,作者嘗試探索了數(shù)據(jù)增強和dropout兩種技巧來提升系統(tǒng)的性能。
1. 數(shù)據(jù)增強
在此之前,Hinton曾經(jīng)提出使用Vocal Tract Length Perturbation (VTLP)的方法來提升語音識別的性能,具體的做法就是在訓練階段對每一個音頻的頻譜特征施加一個隨機的扭曲因子,通過這種做法Hinton實現(xiàn)了在TIMIT小數(shù)據(jù)集上的測試集表現(xiàn)提升了0.65%,VTLP是基于特征層面所做的數(shù)據(jù)增強技巧,不過后來也有人發(fā)現(xiàn)通過改變原始音頻的速度所帶來的性能提升要比VTLP好。但是音頻速度的快慢實際上會影響到音調(diào)(pitch),所以提高了音頻的速度必然也就增大了音頻的音調(diào)。反過來也是,降低了音頻的速度就會使得音頻的音調(diào)變小。所以,僅僅通過調(diào)節(jié)速度的方法就不能產(chǎn)生速度快同時音調(diào)低的音頻,這就使得音頻的多樣性有所降低,對語音識別系統(tǒng)的性能提升有限。作者在本文中希望能夠通過數(shù)據(jù)增強來豐富音頻的變化,提升數(shù)據(jù)的數(shù)量和多樣化,于是作者采取將音頻的速度通過兩個單獨的變量來控制,它們分別是tempo和pitch,也就是節(jié)奏和音高,對音頻的節(jié)奏和音高的調(diào)節(jié)可以通過語音的瑞士軍刀——SOX軟件來完成。
除了改變tempo和pitch以外,作者還添加了高斯白噪聲、改變音頻的音量以及隨機對部分原始音頻的采樣點進行扭曲操作。
2. dropout
dropout是Hinton提出來的一種防止深度神經(jīng)網(wǎng)絡出現(xiàn)過擬合的技巧,它的做法是在訓練神經(jīng)網(wǎng)絡的時候隨機地讓某些神經(jīng)元的輸入變?yōu)?,公式如下所示,通過生成一個概率為1-p的伯努利分布再與神經(jīng)元的輸入進行點乘,即可得到dropout以后的輸入;而在推理階段,我們只需要對輸入乘以伯努利分布的期望值1-p即可。dropout對于前向神經(jīng)網(wǎng)絡作用很明顯,但是應用到循環(huán)神經(jīng)網(wǎng)絡中的時候,很難取得較好的效果。
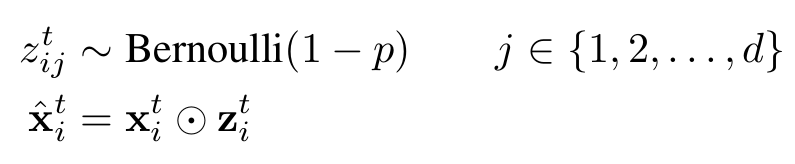
作者在本文中采取的dropout是不隨時間變化的,即對于一個序列的不同時刻,產(chǎn)生dropout的伯努利分布是共享的,而在推理階段,仍然是乘以伯努利分布的期望值1-p。作者在卷積層和循環(huán)層都是采取了這個變種的dropout,而在全連接層則是采取了標準的dropout。
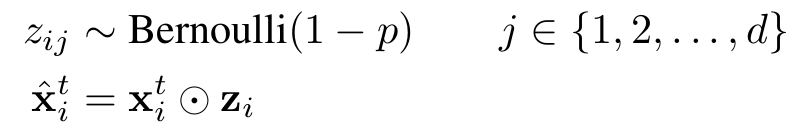
3. 實驗細節(jié)
作者采取的數(shù)據(jù)集是LibriSpeech和WSJ,輸入到模型的特征是語音的頻譜圖(spectrogram),以20ms為一幀,步長設為10ms。同時,作者對特征做了兩個層次的歸一化,分別是把頻譜圖歸一化成均值為0標準差為1的分布,以及對每一個特征維度進行同樣的歸一化,不過這個特征維度的歸一化是基于整體訓練集的統(tǒng)計來做的。
數(shù)據(jù)增強部分,作者基于tempo的增強參數(shù)是取自(0.7, 1.3)的均勻分布,基于pitch的增強參數(shù)是取自(-500, 500)的均勻分布,添加高斯白噪聲的時候?qū)⑿旁氡瓤刂圃?0-15分貝,同時在調(diào)整速度方面,作者分別使用了0.9,1.0和1.1作為調(diào)整的系數(shù)。綜合上面所有數(shù)據(jù)增強技巧,如下圖所示,模型的性能相比沒有這些技巧的baseline提高了20%。
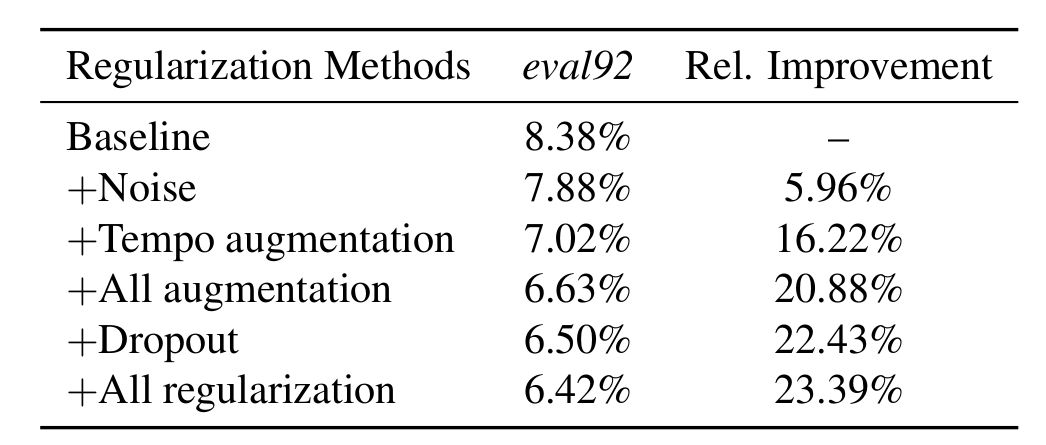
dropout同樣提升了模型的性能,dropout概率作者對數(shù)據(jù)設置了0.1,對卷積層設置了0.2,對所有的循環(huán)層和全連接層設置了0.3,通過dropout,模型性能提高了22.43%,結(jié)合dropout和數(shù)據(jù)增強,模型整體性能提高了23.39%。
4. 總結(jié)
本文應該是對語音識別中的數(shù)據(jù)增強和規(guī)則化技巧做了總結(jié),雖然實驗用的數(shù)據(jù)集是時長比較短的數(shù)據(jù)集,但是這些數(shù)據(jù)集對于我們部署一個實際的語音識別系統(tǒng)也很重要。對于中文普通話語音識別而言,不論是不同人說話的語速、語調(diào),還是不同地方的人說普通話的口音,這些導致語音識別的難度非常大,如果想去采集各個地方不同人所說的普通話語料,對于小公司或者小團隊而言,是非常不現(xiàn)實的一件事情。所以,如何基于有限的普通話語料去使用數(shù)據(jù)增強算法來人工構(gòu)建一個可以模擬全國各個地方不同口音分布的強大語料是一個不得不面對的實際難題,而解決了這個難題實際上也就能極大程度地提升語音識別的魯棒性。
-
端對端
+關注
關注
0文章
3瀏覽量
7856 -
語音識別
+關注
關注
38文章
1739瀏覽量
112635
原文標題:改進語音識別性能的數(shù)據(jù)增強技巧
文章出處:【微信號:DeepLearningDigest,微信公眾號:深度學習每日摘要】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
基于網(wǎng)絡性能的VoIP語音質(zhì)量評價模型
基于labview的語音識別
詳解語音識別技術(shù)原理
離線語音識別及控制是怎樣的技術(shù)?
阿里開源自主研發(fā)AI語音識別模型
在語音處理中,通過使用大數(shù)據(jù)可以輕松解決很多任務
三星無聲語音助手專利解密:可以完成精準語音識別任務
關于多任務學習如何提升模型性能與原則
研討會預告 | 使用 Transducer 模型優(yōu)化語音識別結(jié)果
重塑翻譯與識別技術(shù):開源語音識別模型Whisper的編譯優(yōu)化與部署






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論