 SSL方法是否適用于“現實世界”的環境?
SSL方法是否適用于“現實世界”的環境?
半監督學習(Semi-supervised learning,SSL)提供了一個強大的框架,可以在標記有限或昂貴的情況下利用無標記數據。近期,基于深度神經網絡的SSL算法已被證明在標準基準任務上是成功的。然而,我們認為,這些基準無法解決這些算法在實際應用程序中遇到的許多問題。在對各種廣泛使用的SSL技術進行了統一重新實現(unified reimplemention)之后,我們在一組旨在解決這些問題的實驗中對它們進行了測試。我們發現:不使用無標記數據的簡單基線的性能經常被低估;SSL方法對標記數據和無標記數據數量的敏感性不同;當無標記數據集包含類外的樣本時,其性能會大幅降低。為了幫助指導SSL研究在現實世界的實際應用,我們開源了我們的統一重新實現和評估平臺。
深度神經網絡已經一再被表明,可以通過利用大量標記數據,在某些監督學習問題上達到人類水平或超越人類水平的性能。然而,這些成功有著不同的代價;也就是說,創建這些大型數據集通常需要大量的人力(以手工對樣本增添標記)、痛苦或風險(對于涉及侵入性測試的醫療數據集)或財務費用(用于雇傭標記標注者或構建在特定領域收集數據所需的基礎設施)。對于許多實際問題和應用程序來說,沒有足夠的資源來創建足夠大的標記數據集,這限制了深度學習技術的廣泛采用。
有一個具有吸引力的方法可以緩解這個問題,就是半監督學習(semi-supervised learning,SSL)框架。與需要所有樣本都有標記的監督學習(supervised learning)算法相反,SSL算法可以通過使用無標記樣本來提高其性能。SSL算法通常提供一種從無標記樣本中學習數據結構的方法,這可以減輕對標記的需求。最近的一些研究結果表明,在某些情況下,SSL能夠接近純粹監督學習的性能,即使在給定的數據集中有很大一部分的標記被丟棄。
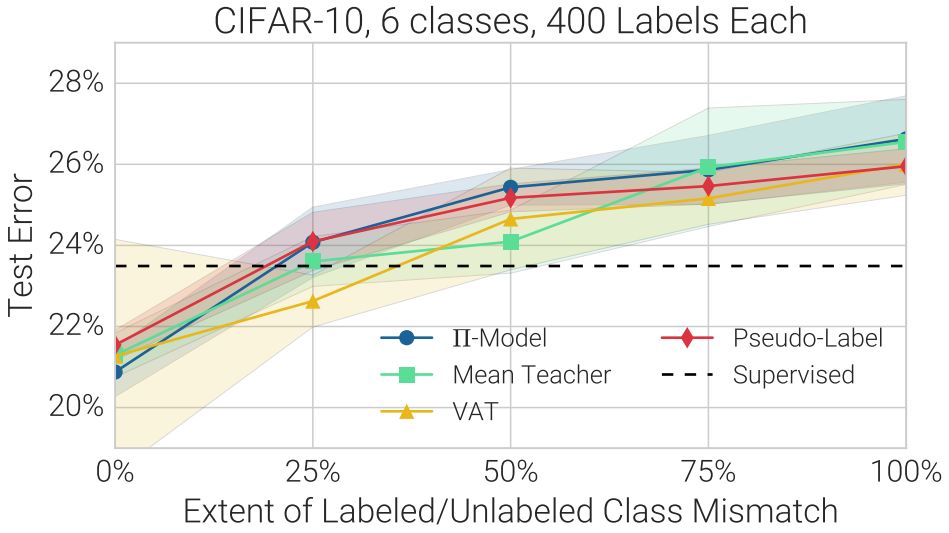
每種SSL技術在CIFAR-10(六類動物)上的測試誤差,其中,在標記數據與無標記數據之間,存在不同程度的重疊。例如,“25%”是指來自不同類的4種無標記數據之一,而非來自標記數據的6類。“監督”是指不使用無標記數據。陰影區域表示5次試驗的標準偏差。
這些最近的成功引出了一個自然的問題:SSL方法是否適用于“現實世界”的環境?在本文中,我們認為,當前評估SSL技術的實際方法并不能以令人滿意的方式解決這個問題。具體而言,采用大型標記數據集并丟棄許多標記的標準評估程序沒有考慮到SSL應用程序的各種常見特征。我們的目標是通過提出一種新的實驗方法來更直接地解決這個問題,我們認為該方法能夠更好地測量對現實世界問題的適應性。我們的一些發現包括:
?當給予調優超參數(hyperparameter)相同預算時,使用SSL和使用標記數據之間的性能差距比通常記錄的差距要小。
?此外,使用無標記數據的大型、高度正則化的分類器的強大性能證明了在同一個基礎模型上評估不同SSL算法的重要性。
?在不同的標記數據集上對分類器進行預先訓練,然后僅在利益相關數據集中的標記數據上進行再訓練,這可以勝過所有我們研究過的SSL算法。
?當無標記數據包含與標記數據不同的類分布時,SSL技術的性能可能會急劇下降。
?不同的方法對標記數據和無標記數據數量的敏感度有很大不同。
?實際的小型驗證集(validation set)會妨礙對不同方法、模型和超參數設置進行可靠的比較。
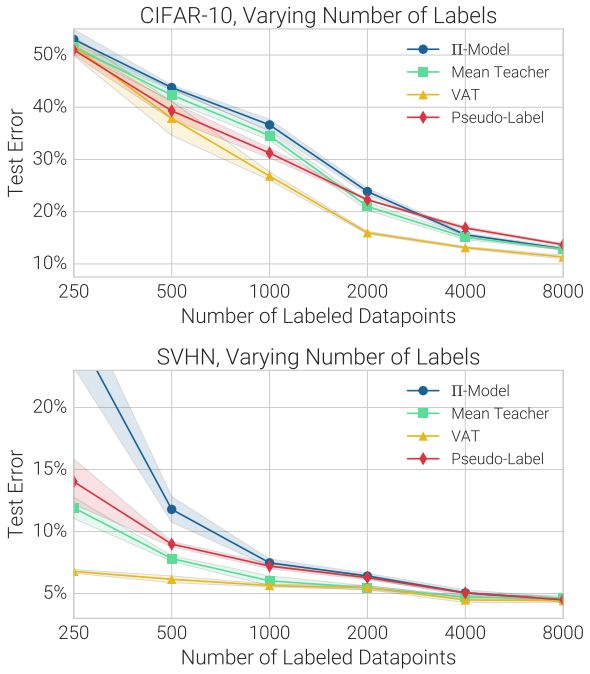
在SVHN和CIFAR-10中,每種SSL技術的測試誤差都隨標記數據量的變化而變化。陰影區域表示5次實驗的標準偏差。X軸采用對數形式表示
此外,與機器學習中的許多領域一樣,對超參數、模型結構及訓練的微小調整,都會對方法的直接比較構成混淆,并對結果產生重大影響。為了改善這一問題,我們提出了關于各種SSL方法的統一的、模塊化的重新實現,這些方法也使得我們的評估技術成為現實。
結論與建議
我們的實驗提供了有力的證據,證明SSL的標準評估實踐是不現實的。為了更好地反應在現實世界中的應用,我們應該對評估進行哪些改進呢?我們對SSL算法的評估有以下建議:
?在比較不同的SSL方法時,使用完全相同的基礎模型。因為模型結構或實現細節的差異會對結果產生很大影響。
?報告需認真評估對完全監督精確度和遷移學習性能的要求,以將其作為基準。SSL的目標應該定為,顯著優于完全監督環境下的綜合表現。
?對類分布失協情況的系統性變化的結果進行報告。 我們表明,當采用是不同類的無標記數據,而非標記數據時,我們對SSL技術的研究受到了影響。據我們了解,這一現實問題被嚴重忽略了。
?在評估性能時,應調整標記數據和無標記數據的數量。理想的SSL算法即使在標記數據很少的情況下也是非常有效的,并且它還可以從額外的無標記數據中受益。具體而言,我們建議將SVHN和SVHN-extract相結合,來測試大型無標記數據機制的性能。
?注意,不要在非真實的大型驗證集上過度調節超參數。如果驗證集非常小,那么為了獲得理想的性能而在每個模型或每個任務基礎上,對超參數進行重大調整的SSL方法將不可用。
我們的研究還表明,面對以下情況時,SSL或許是研究人員最正確的選擇:
?當沒有來自類似域的高質量標記數據集用于微調時。
?當標記數據是通過獨立同分布(i.i.d)采樣,從無標記數據集中采集得到,而不是從不同分布中收集得來時。
?當標記的數據集足夠大,能夠準確計算驗證精確度時(這是進行模型選擇和超參數調優所必須的條件)。
近來,SSL收獲了巨大的成功。我們希望我們的研究成果,以及公開可用的統一實現,能夠讓成功之花在現實世界中遍地綻放。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100714 -
SSL
+關注
關注
0文章
125瀏覽量
25737 -
深度學習
+關注
關注
73文章
5500瀏覽量
121111
原文標題:該如何對「半監督學習算法」實際性應用進行評估?Google給出了新答案
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
是否有適用于CYBT-343026-01的SPICE型號?
適用于所有atmega328p項目的通用板
STM32L073RZ是否適用于近地軌道運行環境?
是否有適用于LPC4357的替代屏幕?
是否有適用于LS1046ARDB上的Secure JTAG的任何應用說明?
泰科電子推出適用于LED印刷電路板上全新的IDC SSL連接
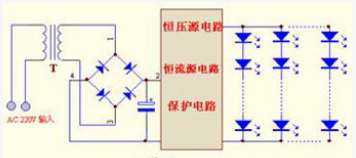
基于一種適用于SSL產品的LED控制電路設計
UltraFAST設計方法指南(適用于Vivado Design Suite)

UltraFAST設計方法指南(適用于Vivado Design Suite)





 工商網監
工商網監
評論