 對于機器學習/數據科學初學者 應該掌握的七種回歸分析方法
對于機器學習/數據科學初學者 應該掌握的七種回歸分析方法
對于機器學習/數據科學的初學者來說,線性回歸,或者Logistic回歸是許多人在建立預測模型時接觸的第一/第二種方法。由于這兩種算法適用性極廣,有些人甚至在走出校門當上數據分析師后還固執地認為回歸只有這兩種形式,或者換句話說,至少線性回歸和Logistic回歸應該是其中最重要兩個算法。那么事實真的是這樣嗎?
Sunil Ray是一位在印度保險行業擁有豐富經驗的商業分析師和人工智能專家,針對這個問題,他指出其實回歸有無數種形式,每種回歸算法都有自己擅長的領域和各自的特色。在本文中,他將以最簡單的形式介紹7種較為常見的回歸形式,希望讀者們在耐心閱讀完畢后,可以在學習、工作中多做嘗試,而不是無論遇到什么問題都直接上“萬金油”的線性回歸和Logistic回歸。
目錄
1. 什么是回歸分析?
2. 為什么要用回歸分析?
3. 幾種常見的回歸分析方法
線性回歸
Logistic回歸
多項式回歸
逐步回歸
嶺回歸
Lasso回歸
ElasticNet回歸
4. 如何挑選適合的回歸模型?
什么是回歸分析?
回歸分析是一種預測建模技術,它可以被用來研究因變量(目標)和自變量(預測)之間的關系,常見于預測建模、時間序列建模和查找變量間關系等應用。舉個例子,通過回歸分析,我們能得出司機超速駕駛和發生交通事故次數之間的關系。
它是建模和分析數據的重要工具。回歸分析在圖像上表示為一條努力擬合所有數據點的曲線/線段,它的目標是使數據點和曲線間的距離最小化。
為什么要用回歸分析?
如上所述,回歸分析估計的是兩個或兩個以上變量間的關系。我們可以舉這樣一個例子來幫助理解:
假設A想根據公司當前的經濟狀況估算銷售增長率,而最近一份數據表明,公司的銷售額增長約為財務增長的2.5倍。在此基礎上,A就能基于各項數據信息預測公司未來的銷售情況。
使用回歸分析有許多優點,其中最突出的主要是以下兩個:
它能顯示因變量和自變量之間的顯著關系;
它能表現多個獨立變量對因變量的不同影響程度。
除此之外,回歸分析還能揭示同一個變量帶來的不同影響,如價格變動幅度和促銷活動多少。它為市場研究人員/數據分析師/數據科學家構建預測模型提供了評估所用的各種重要變量。
幾種常見的回歸分析方法
回歸分析的方法有很多,但其中出名的沒幾個。綜合來看,所有方法基本上都由這3個重要參數驅動:自變量的數量、因變量的類型和回歸曲線的形狀。
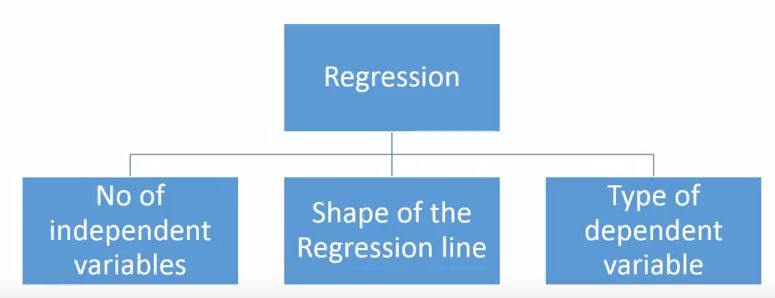
至于為什么是這三點,我們會在后文作出具體解釋。當然,對于那些有創意、能獨立設計參數的人,他們的模型大可不必局限于這些參數。這只是以前大多數人的做法。
1. 線性回歸
線性回歸是知名度最廣的建模方法之一。每當提及建立一個預測模型,它總能占一個首選項名額。對于線性回歸,它的因變量是連續的,自變量則可以是連續的或是離散的。它的回歸線在本質上是線性的。
在一元問題中,如果我們要用線性回歸建立因變量Y和和自變量X之間的關系,這時它的回歸線是一條直線,如下圖所示。
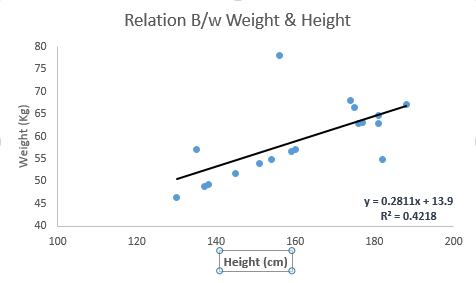
它的相應表達式為:Y = a + b × X + e。其中a是y軸截距,b是回歸線斜率,e是誤差項。
但有時我們可能擁有不止一個自變量X,即多元問題,這時多元線性回歸的回歸方程就是一個平面或是一個超平面。
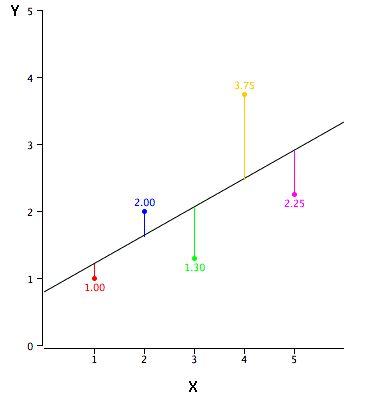
既然有了一條線,那我們如何確定擬合得最好的那條回歸線呢(a和b的值)?對于這個問題,最常規的方法是最小二乘法——最小化每個點到回歸線的歐氏距離平方和。由于做了平方,距離不存在正負差別影響。
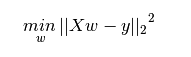
線性回歸重點:
自變量和因變量之間必須存在線性關系;
多元回歸受多重共線性、自相關和異方差影響;
線性回歸對異常值非常敏感。它會嚴重影響回歸線,并最終影響預測值。
多重共線性會使參數估計值的方差增大,可能會過度地影響最小二乘估計值,從而造成消極影響。
在存在多個自變量的情況下,我們可以用前進法、后退法和逐步法選擇最顯著的自變量。
2. Logistic回歸
Logistic回歸一般用于判斷事件成功/失敗的概率,如果因變量是一個二分類(0/1,真/假,是/否),這時我們就應該用Logistic回歸。它的Y是一個值域為[0, 1]的值,可以用下方等式表示:
odds = p/ (1-p) = 事件發生概率 / 事件未發生概率 ln(odds) = ln(p/(1-p)) logit(p) = ln(p/(1-p)) = b0+b1×1+b2×2+b3×3....+bk×k
在上式中,p是目標特征的概率。不同于計算平方和的最小值,這里我們用的是極大似然估計,即找到一組參數θ,使得在這組參數下,樣本數據的似然度(概率)最大。考慮到對數損失函數與極大似然估計的對數似然函數在本質上是等價的,所以Logistic回歸使用了對數函數求解參數。
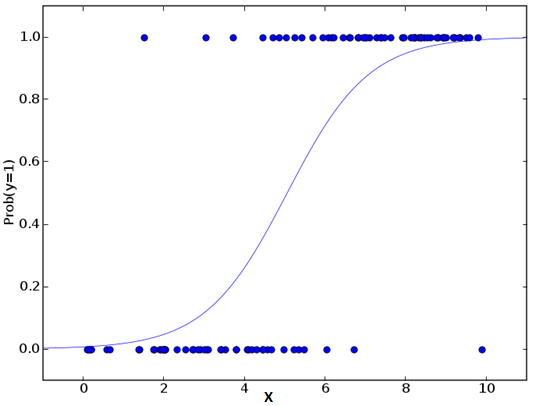
Logistic回歸重點:
Logistic回歸被廣泛用于分類問題。
Logistic回歸無需依賴自變量和因變量之間的線性關系,而是用非線性對數計算用于預測的比值比,因此可以處理各種類型的問題。
為了避免過擬合和欠擬合,Logistic回歸需要包含所有重要變量,然后用逐步回歸方法去估計邏輯回歸。
Logistic回歸對樣本大小有較高要求,因為對于過小的數據集,最大似然估計不如普通最小二乘法。
各自變量間不存在多重共線性。
如果因變量的值是序數,那么它就該被稱為序數Logistic回歸。
如果因變量是多個類別,那么它就該被稱為多項Logistic回歸。
3. 多項式回歸
多項式回歸是對線性回歸的補充。線性回歸假設自變量和因變量之間存在線性關系,但這個假設并不總是成立的,所以我們需要擴展至非線性模型。Logistic回歸采取的方法是用非線性的對數函數,而多項式回歸則是把一次特征轉換成高次特征的線性組合多項式。
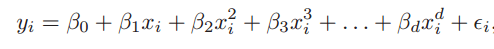
一元多項式回歸
簡而言之,如果自變量的冪大于1,那么該回歸方程是多項式回歸方程,即Y = A + B × X2。在這種回歸方法中,它的回歸線不是一條直線,而是一條力爭擬合所有數據點的曲線。
多項式回歸重點:
盡管更高階的多項式回歸可以獲得更低的誤差,但它導致過擬合的可能性也更高。
要注意曲線的方向,觀察它的形狀和趨勢是否有意義,在此基礎上在逐步提高冪。
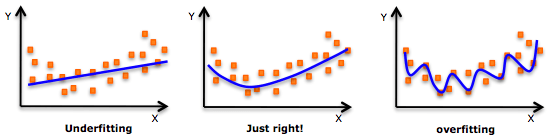
過擬合
4. 逐步回歸
截至目前,上述方法都需要針對因變量Y選擇一個目標自變量X,再用線性的、非線性的方法建立“最優”回歸方程,以便對因變量進行預測或分類。那么當我們在處理多個自變量時,有沒有一種回歸方法能按照對Y的影響大小,自動篩選出那些重要的自變量呢?
這種方法就是本節要介紹的逐步回歸,它利用觀察統計值(如R方,t-stats和AIC度量)來辨別重要變量。作為一種回歸分析方法,它使用的方法是基于給定的水平指標F一次一個地添加/丟棄變量,以下是幾種常用的做法:
標準的逐步回歸只做兩件事:根據每個步驟添加/刪除變量。
前進法:基于模型中最重要的變量,一次一個添加剩下的變量中最重要的變量。
后退法:基于模型中所有變量,一次一個刪除最不重要的變量。
這種建模方法的目的是用盡可能小的變量預測次數來最大化預測能力,它是處理更高維數據集的方法之一。
5. 嶺回歸
在談及線性回歸重點時,我們曾提到多重共線性會使參數估計值的方差增大,并過度地影響最小二乘估計值,從而降低預測精度。因此方差和偏差是導致輸出值偏離真值的罪魁禍首之一。
我們先來回顧一下線性回歸方程:Y = a + b × X + e。
如果涉及多個自變量,那它是:Y = a + Y = a + b1X1+ b2X2+ … + e
上式表現了偏差和誤差對最終預測值的明顯影響。為了找到方差和偏差的折中,一種可行的做法是在平方誤差的基礎上增加一個正則項λ,來解決多重共線性問題。請看以下公式:
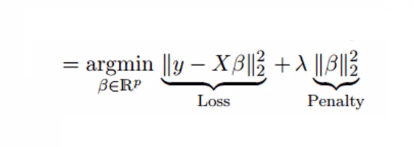
這個代價函數可以被分為兩部分,第一部分是一個最小二乘項,第二部分則是系數β的平方和,再乘以一個調節參數λ作為懲罰項,它能有效控制方差和偏差的變化:隨著λ的增大,模型方差減小而偏差增大。
嶺回歸重點:
嶺回歸的假設與最小二乘法回歸的假設相同,除了假設正態性。
嶺回歸可以縮小系數的值,但因為λ不可能為無窮大,所以它不會等于0。
這實際上是一種正則化方法,使用了l2范數。
6. Lasso回歸
同樣是解決多重共線性問題,嶺回歸是在平方誤差的基礎上增加一個正則項λ,那么Lasso回歸則把二次項改成了一次絕對值。它可以降低異常值對模型的影響,并提高整體準確度。
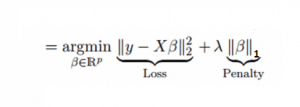
一次項求導可以抹去變量本身,因此Lasso回歸的系數可以為0。這樣可以起來真正的特征篩選效果。
Lasso回歸重點:
Lasso回歸的假設與最小二乘法回歸的假設相同,除了假設正態性。
Lasso回歸的系數可以為0。
這實際上是一種正則化方法,使用了l1范數。
如果一組變量高度相關,Lasso回歸會選擇其中的一個變量,然后把其他的都變為0。
7. ElasticNet回歸
ElasticNet是Lasso和Ridge回歸技術的結合。它使用L1和L2范數作為懲罰項,既能用于權重非零的稀疏模型,又保持了正則化屬性。簡單來說,就是當有多個相關特征時,Lasso回歸只會選擇其中的一個變量,但ElasticNet回歸會選擇兩個。
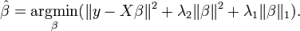
在Lasso和Ridge之間進行權衡的一個實際優勢是,它允許Elastic-Net繼承嶺回歸的一些穩定性。
ElasticNet回歸重點:
它鼓勵在高度相關變量的情況下的群體效應。
在選擇變量的數量上沒有限制。
受雙重收縮影響。
除了這7中常用的回歸分析方法外,貝葉斯回歸、生態學回歸和魯棒回歸也是出鏡率很高的一些選擇。
如何挑選適合的回歸模型?
當你只知道一種或兩種方法時,生活通常很簡單。相信不少讀者都聽到過這種論調:如果結果是連續的,用線性回歸;如果是個二分類,就用Logistic回歸。然而隨著現在我們的選擇越來越多,許多人不免要深受選擇恐懼癥影響,無法做出滿意的決定。
那么面對這么多的回歸分析方法,我們該怎么選擇呢?以下是一些可以考慮的關鍵因素:
數據探索是構建預測模型不可或缺的一部,因此在選擇正確的模型前,我們可以先分析數據,找到變量間的關系。
為了比較不同方法的擬合成都,我們可以分析統計顯著性參數、R方、調整R方、最小信息標準、BIC和誤差準則等統計值,或者是Mallow‘s Cp準則。將模型與所有可能的子模型進行比較來檢查模型中可能存在的偏差。
交叉驗證是評估預測模型最好的方法沒有之一。
如果你的數據集中有多個奇怪變量,你最好手動添加而不要用自動的方法。
殺雞焉用牛刀。根據你的任務選擇強大/不強大的模型。
嶺回歸、Lasso回歸和ElasticNet回歸在高維度、多重共線性情況下有較好的表現。
-
機器學習
+關注
關注
66文章
8406瀏覽量
132566 -
數據科學
+關注
關注
0文章
165瀏覽量
10053
原文標題:初學者應該掌握的七種回歸分析方法
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
DSP5509A這個芯片,對于初學者應該從哪里開始學習啊???
初學者之路—硬件學習經驗
HDL初學者謹記:學習HDL前必知
cad初學者應該注意的問題
九張機器學習和深度學習代碼速查表分享_初學者必備

機器學習的初學者必看指南







 工商網監
工商網監
評論