 一種能夠平滑銜接無模型和基于模型策略的強化學習算法
一種能夠平滑銜接無模型和基于模型策略的強化學習算法
試想一下我們希望從伯克利大學騎車到金門大橋,雖然僅僅只有二十公里之遙,但如果卻面臨一個天大的問題:你從來沒有騎過自行車!而且雪上加霜的是,你剛剛來到灣區對于路況很陌生,手頭僅僅只有一張市區的地圖。那我們該如何騎車去看心心念念的金門大橋呢?這個看似十分復雜的任務卻是機器人利用強化學習需要解決的問題。
讓我們先來看看如何學會騎自行車。一種方法是先盡可能多的學習知識并一步步的規劃自己的行為來實現騎車這一目標:通過讀如何騎自行車的書、學習相關的物理知識、規劃騎車時每一塊肌肉的運動...這種一板一眼的方式在研究中還可行,但是要是用來學習自行車那永遠也到不了金門大橋了。學習自行車正確的姿勢是不斷地嘗試不斷地試錯和練習。像學習騎自行車這樣太復雜的問題是不能通過實現規劃實現的。
當你學會騎車之后,下一步便是如果從伯克利到金門大橋了。你可以繼續利用試錯的策略嘗試各種路徑看看終點是不是在金門大橋。但這種方式顯而易見的缺點是我們可能需要十分十分久的時間才能到達。那么對于這樣簡單的問題,基于已有的信息規劃便是一種十分有效的策略了,無需太多真實世界的經驗和試錯便能完成。在強化學習中意味著更加高效采樣的學習過程。
對于一些技能來說試錯學習十分有效,而對于另一些規劃卻來得更好
上面的例子雖然簡單但卻反映了人類智慧的重要特征,對于某些任務我們選擇利用試錯的方式,而某些任務則基于規劃來實現。同樣在強化學習中不同的方法也適用于不同的任務。
然而在上面的例子中兩種方法卻不是完全獨立的,事實上如果用試錯的方法來概括自行車的學習過程就太過于簡單了。當我們利用試錯的方法來學習自行車時,我們也利用了一點點規劃的方法。可能在一開始的時候你的計劃是不要摔倒,而后變為了不要摔倒地騎兩米。最后當你的技術不斷提高后,你的目標會變成更為抽象的概念比如要騎到道路的盡頭哦,這時候需要更多關注的是如何規劃這一目標而不是騎車的細節了。可以看到這是一個逐漸從無模型轉換為基于模型策略的過程。如果能將這種策略移植到強化學習算法中,那么我們就能得到既能表現良好(最初階段的試錯方法)又具有高效采樣特性(在后期轉化為利用規劃實現更為抽象的目標)的優秀算法了。
這篇文章中主要介紹了時域差分模型,這是一種能夠平滑銜接無模型和基于模型策略的強化學習算法。接下來首先要介紹基于模型的算法是如何工作的。
基于模型的強化學習算法
在強化學習中通過動力學模型,在行為at的作用下狀態將從st轉化到st+1,學習的目標是最大化獎勵函數r(st,a,st+1)的和。基于模型的強化學習算法假設事先給定了一個動力學模型,那么我們假設模型的學習目標是最大化一系列狀態的獎勵函數:

這一目標函數意味著在保證目標可行的狀態下選取一系列狀態和行為并最大化獎勵。可行意味著每一個狀態轉移是有效的。例如下圖中只有st+1是可行的狀態。即便其他狀態有更高的獎勵函數但是不可行的轉移也是無效的。
在我們的騎行問題中,優化問題需要規劃一條從伯克利到金門大橋的路線:
上圖中現實的概念很好但是卻不現實。基于模型的方法利用模型f(s,a)來預測下一步的狀態。在機器人中每一步十分的時間十分短暫,更實際的規劃將會是像下圖一樣更為密集的狀態轉移:
回想我們每天騎自行車的過程我們的規劃其實是十分抽象的過程,我們通常都會規劃長期的目標而不是每一步具體的位置。而且我們僅僅在最開始的時候進行一次抽象的規劃。就像剛剛討論的那樣,我們需要一個起點來進行試錯的學習,并需要提供一種機制來逐漸增加計劃的抽象性。于是我們引入了時域差分模型。
時域差分模型
時域差分模型一般形式為Q(s,a,sg,τ),給定當前狀態、行為以及目標狀態后,預測τ時間步長時主體與目標相隔的距離。直觀上TDM回答了這樣的問題:“如果我騎車去市中心,30分鐘后我將會距離市中心多近呢?”對于機器人來說測量距離主要使用歐式距離來度量。
上圖中的灰線代表了TMD算法計算出距離目標的距離。那么在強化學習中,我們可以將TMD視為在有限馬爾科夫決策過程中的條件Q函數。TMD是Q函數的一種,我們可以利用無模型的方法來進行訓練。一般地人們會使用深度置信策略梯度來訓練TDM并對目標和時間進行回溯標記以提高算法的采樣效率。理論上Q學習算法都可以用于訓練TDM,但研究人員發現目前的算法更為有效。更多細節請參看論文。
利用TDM進行規劃
當訓練結束后我們可以利用下面的目標函數進行規劃:

這里與基于模型策略不同的地方在于每K步進行一次規劃,而不是每一步。等式右端的零保證了每一次狀態轉移軌跡的有效性:
規劃就從上面的細碎的步驟變成了下圖整體的,更為抽象和長期的策略:
當我們增加K時,就能獲得更為長期和抽象的規劃。在K步之間利用無模型的方法來選擇行為,使用無模型的策略來抽象達成這些目標的過程,最后在K足夠大的情況下實現了下圖的規劃情況,基于模型的方法用于選擇抽象目標而無模型的方法則用于達到這些目標:
需要注意的是這種方法只能在K步的地方進行優化,而現實情況下卻只關心某些特殊的狀態(如最終狀態)。
實驗
研究人員們利用TMD算法進行了兩個實驗,首先是利用模擬的機械臂將圓柱推到目標位置:
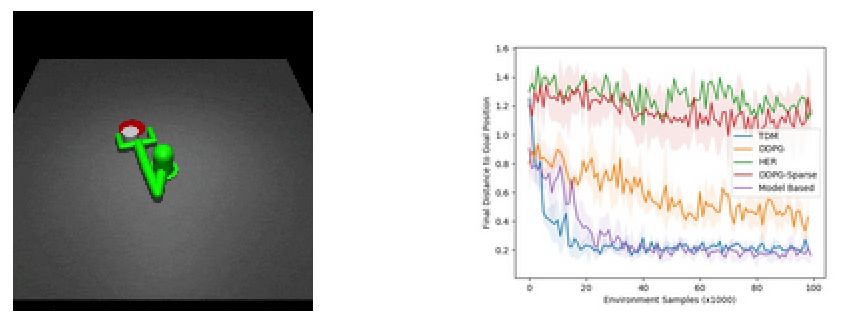
可以發現TMD算法比無模型的DDPG算法和基于模型的算法都下降的快,其快速學習能力來自于之前提到的基于模型的高效采樣。
另一個實驗是利用機器人進行定位的任務,下圖是實驗的示意圖和學習曲線:
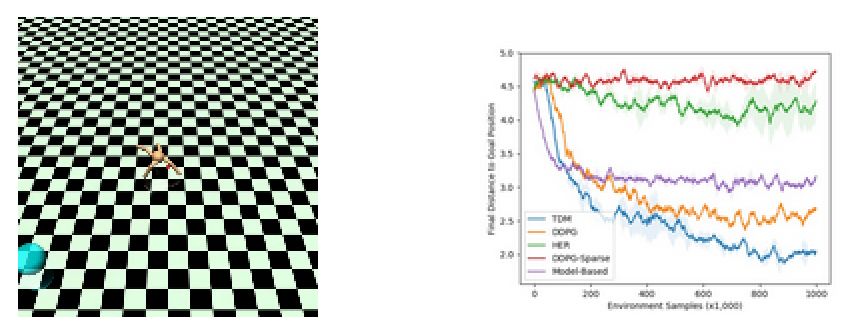
上圖現實基于模型的方法在訓練到一定次數后就停滯了,而基于DDPG的無模型方法則下降緩慢,但最終效果強于基于模型的方法。而TMD方法則即快速有優異,結合了上述兩者的優點。
未來方向
時域差分模型為無模型和基于模型的方法提供了有效的數學描述和實現方法,但還有一系列工作需要完善。首先理論中假設環境和策略是確定的,而實際中卻存在一定的隨機性。這方面的研究將促進TMD對于真實環境的適應性。此外TMD可以和可選擇的基于模型的規劃方法結合優化。最后還希望未來將TMD用于真實機器人的定位、操作任務,甚至騎車到金門大橋去。
-
機器人
+關注
關注
211文章
28380瀏覽量
206918 -
模型
+關注
關注
1文章
3226瀏覽量
48809 -
學習算法
+關注
關注
0文章
15瀏覽量
7467
原文標題:UC Berkeley提出新的時域差分模型策略:從無模型到基于模型的深度強化學習
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
簡單隨機搜索:無模型強化學習的高效途徑

斯坦福提出基于目標的策略強化學習方法——SOORL

深度強化學習到底是什么?它的工作原理是怎么樣的
機器學習中的無模型強化學習算法及研究綜述

模型化深度強化學習應用研究綜述

基于深度強化學習仿真集成的壓邊力控制模型
7個流行的強化學習算法及代碼實現
通過強化學習策略進行特征選擇






 工商網監
工商網監
評論