") 使用巧妙的集成方法改進(jìn)了神經(jīng)網(wǎng)絡(luò)的優(yōu)化過(guò)程
使用巧妙的集成方法改進(jìn)了神經(jīng)網(wǎng)絡(luò)的優(yōu)化過(guò)程
傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)集成
傳統(tǒng)上,集成組合若干不同的模型,讓它們基于相同的輸入做出預(yù)測(cè)。接著通過(guò)某種平均化方法決定集成的最終預(yù)測(cè)。可能是通過(guò)簡(jiǎn)單的投票或取均值,也可能是通過(guò)另一個(gè)模型,該模型基于集成模型的結(jié)果學(xué)習(xí)預(yù)測(cè)正確值或標(biāo)簽。嶺回歸是一種組合若干預(yù)測(cè)的特定方法,Kaggle競(jìng)賽冠軍使用過(guò)這一方法。
集成應(yīng)用于深度學(xué)習(xí)時(shí),組合若干網(wǎng)絡(luò)的預(yù)測(cè)以得到最終預(yù)測(cè)。通常,使用不同架構(gòu)的神經(jīng)網(wǎng)絡(luò)比較好,因?yàn)椴煌軜?gòu)的網(wǎng)絡(luò)更可能在不同的訓(xùn)練樣本上犯錯(cuò),因而集成的收益會(huì)更大。
然而,你也可以集成同一架構(gòu)的模型,并得到出乎意料的好效果。比如,在這篇快照集成的論文中,作者在訓(xùn)練同一個(gè)網(wǎng)絡(luò)時(shí)保存了權(quán)重快照,在訓(xùn)練之后,創(chuàng)建了同一架構(gòu)、不同權(quán)重的網(wǎng)絡(luò)集成。這可以提升測(cè)試表現(xiàn),同時(shí)也是一個(gè)非常節(jié)省開銷的方法,因?yàn)槟阒挥?xùn)練一個(gè)模型,訓(xùn)練一次,只不過(guò)不時(shí)地保存權(quán)重。
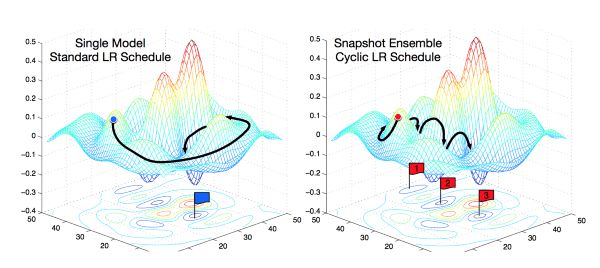
每個(gè)學(xué)習(xí)率周期末尾保存模型;圖片來(lái)源:原論文
你可以閱讀文章開頭提到的Vitaly Bushaev的博客文章了解細(xì)節(jié)。如果你到目前為止還沒(méi)有嘗試過(guò)周期性學(xué)習(xí)率,那你真應(yīng)該嘗試一下,它正在成為當(dāng)前最先進(jìn)的技術(shù),而且非常簡(jiǎn)單,算力負(fù)擔(dān)也不重,可以說(shuō)是在幾乎不增加額外開銷的前提下提供顯著的增益。
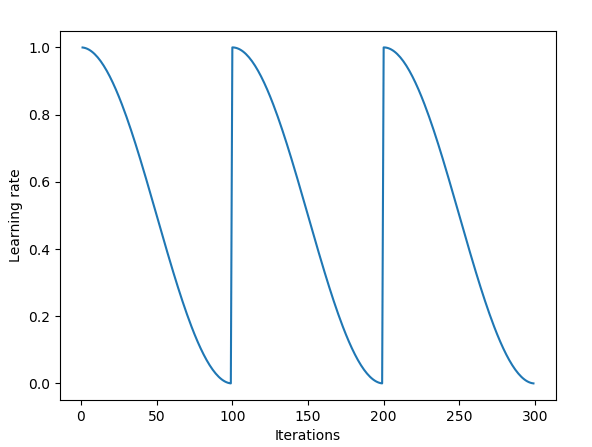
快照集成使用周期性學(xué)習(xí)率退火;圖片來(lái)源:Vitaly Bushaev
上面所有的例子都是模型空間內(nèi)的集成,組合若干模型,接著使用這些模型的預(yù)測(cè)以得到最終模型。
而本文開頭提到的論文,作者提出的是權(quán)重空間內(nèi)的集成。該方法通過(guò)組合同一網(wǎng)絡(luò)在訓(xùn)練的不同階段的權(quán)重得到一個(gè)集成,接著使用組合的權(quán)重做出預(yù)測(cè)。這一方法有兩大優(yōu)勢(shì):
組合權(quán)重后,我們最終仍然得到一個(gè)模型,這有利于加速預(yù)測(cè)。
該方法超過(guò)了當(dāng)前最先進(jìn)的快照集成。
在我們看看這一方法是如何工作之前,我們需要先理解損失平面(loss surface)和概化解(generalizable solution)。
權(quán)重空間的解
第一個(gè)重要的洞見是,一個(gè)訓(xùn)練好的網(wǎng)絡(luò)是多維權(quán)重空間中的一點(diǎn)。對(duì)任何給定的架構(gòu)而言,每個(gè)不同的網(wǎng)絡(luò)權(quán)重組合產(chǎn)生一個(gè)不同的模型。任何給定架構(gòu)都有無(wú)窮的權(quán)重組合,因而有無(wú)窮的解。訓(xùn)練神經(jīng)網(wǎng)絡(luò)的目標(biāo)是找到一個(gè)特定的解(權(quán)重空間中的點(diǎn)),使得訓(xùn)練數(shù)據(jù)集和測(cè)試數(shù)據(jù)集上的損失函數(shù)的值都比較低。
在訓(xùn)練中,訓(xùn)練算法通過(guò)改變權(quán)重來(lái)改變網(wǎng)絡(luò)并在權(quán)重空間中漫游。梯度下降算法在一個(gè)損失平面上漫游,該平面的海拔為損失函數(shù)的值。
狹窄最優(yōu)和平坦最優(yōu)
可視化和理解多維權(quán)重空間的幾何學(xué)非常困難。與此同時(shí),了解它又非常重要,因?yàn)殡S機(jī)梯度下降本質(zhì)上是在訓(xùn)練時(shí)穿過(guò)這一高維空間中的損失平面,試圖找到一個(gè)良好的解——損失平面上的一“點(diǎn)”,那里損失值較低。研究表明,這一平面有很多局部最優(yōu)值。但這些局部最優(yōu)值并不同樣良好。
為了處理一個(gè)14維空間中的超平面,可視化一個(gè)3維空間,然后大聲對(duì)自己說(shuō)“十四”。每個(gè)人都這么做。
-- Hinton (出處:coursera課程)
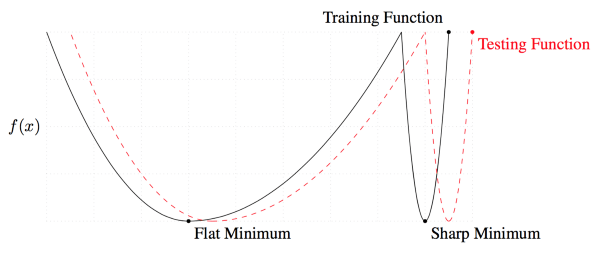
可以區(qū)分良好的解與糟糕的解的一個(gè)量度是平坦性(flatness)。背后的想法是訓(xùn)練數(shù)據(jù)集和測(cè)試數(shù)據(jù)集會(huì)產(chǎn)生相似但不是完全一樣的損失平面。你可以將其想象為測(cè)試平面相對(duì)訓(xùn)練平面平移了一點(diǎn)。對(duì)一個(gè)狹窄的解而言,測(cè)試時(shí)期,損失較低的點(diǎn)可能因?yàn)檫@一平移產(chǎn)生變?yōu)閾p失較高的點(diǎn)。這意味著這一狹窄的解概括性不好——訓(xùn)練損失低,測(cè)試損失高。另一方面,對(duì)于寬而平的解而言,這一平移造成的訓(xùn)練損失和測(cè)試損失間的差異較小。
我解釋了兩種解之間的差異,因?yàn)楸疚年P(guān)注的新方法可以導(dǎo)向良好、寬闊的解。
快照集成
起初,SGD會(huì)在權(quán)重空間中跳一大步。接著,由于余弦退火,學(xué)習(xí)率會(huì)降低,SGD將收斂于某個(gè)局部解,算法將保存一個(gè)模型的“快照”。接著學(xué)習(xí)率重置為高值,SGD再次邁一大步,以此類推。
快照集成的周期長(zhǎng)度為20到40個(gè)epoch。較長(zhǎng)的學(xué)習(xí)率周期是為了在權(quán)重空間中找到足夠不同的模型,以發(fā)揮集成的優(yōu)勢(shì)。
快照集成表現(xiàn)優(yōu)異,提升了模型的表現(xiàn),但是快速幾何集成(Fast Geometric Ensembling)效果更好。
快速幾何集成(FGE)
快速幾何集成和快照集成非常相似。它們的不同主要有兩點(diǎn)。第一,快速幾何集成使用線性分段周期學(xué)習(xí)率規(guī)劃,而不是余弦退火。第二,F(xiàn)GE的周期長(zhǎng)度要短得多——2到4個(gè)epoch。這是因?yàn)樽髡甙l(fā)現(xiàn),在足夠不同的模型之間,存在著損失較低的連通路徑。沿著這些路徑小步前進(jìn)所得的模型差異較大,足夠發(fā)揮集成的優(yōu)勢(shì)。因此,相比快照集成,F(xiàn)GE表現(xiàn)更好,搜尋模型的步調(diào)更小(步調(diào)更小使其訓(xùn)練更快)。
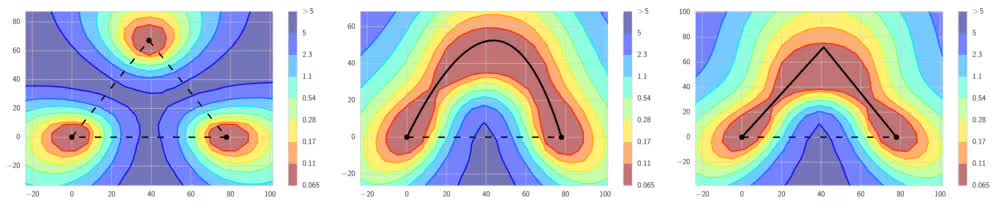
如上圖左側(cè)的圖像所示,根據(jù)傳統(tǒng)的直覺(jué),良好的局部極小值被高損失區(qū)域分隔開來(lái)(圖中虛線)。而上圖中、右的圖像顯示,局部極小值之間存在著路徑,這些路徑上的損失都很低(圖中實(shí)線)。FGE沿著這些路徑保存快照,從而創(chuàng)建快照的集成。
快照集成和FGE都需要儲(chǔ)存多個(gè)模型,接著讓每個(gè)模型做出預(yù)測(cè),之后加以平均以得到最終預(yù)測(cè)。因此,我們?yōu)榧傻念~外表現(xiàn)支付了更高的算力代價(jià)。所以天下沒(méi)有免費(fèi)的午餐。真的沒(méi)有嗎?讓我們看看隨機(jī)加權(quán)平均吧。
隨機(jī)加權(quán)平均(SWA)
隨機(jī)加權(quán)平均只需快速集合集成的一小部分算力,就可以接近其表現(xiàn)。SWA導(dǎo)向我之前提到過(guò)的廣闊的極小值。在經(jīng)典定義下,SWA不算集成,因?yàn)樵谟?xùn)練的最終階段你得到一個(gè)模型,但它的表現(xiàn)超過(guò)了快照集成,接近FGE。
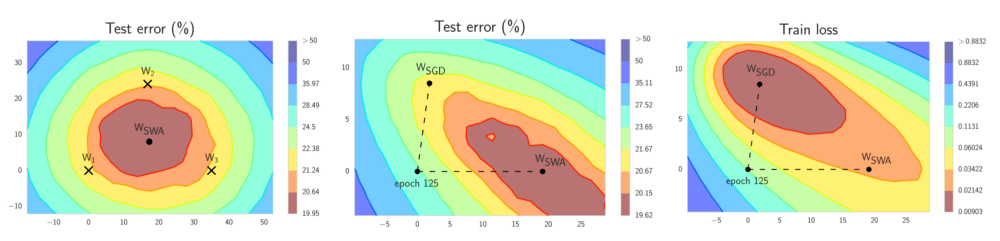
SWA的直覺(jué)來(lái)自以下由經(jīng)驗(yàn)得到的觀察:每個(gè)學(xué)習(xí)率周期得到的局部極小值傾向于堆積在損失平面的低損失值區(qū)域的邊緣(上圖左側(cè)的圖形中,褐色區(qū)域誤差較低,點(diǎn)W1、W2、3分別表示3個(gè)獨(dú)立訓(xùn)練的網(wǎng)絡(luò),位于褐色區(qū)域的邊緣)。對(duì)這些點(diǎn)取平均值,可能得到一個(gè)寬闊的概化解,其損失更低(上圖左側(cè)圖形中的WSWA)。
上圖中間的圖形顯示,WSWA在測(cè)試集上的表現(xiàn)超越了SGD。而上圖右側(cè)的圖形顯示,WSWA在訓(xùn)練時(shí)的損失比SGD要高。結(jié)合WSWA在測(cè)試集上優(yōu)于SGD的表現(xiàn),這意味著盡管WSWA訓(xùn)練時(shí)的損失較高,它的概括性更好。
下面是SWA的工作機(jī)制。SWA只保存兩個(gè)模型,而不是許多模型的集成:
第一個(gè)模型保存模型權(quán)重的平均值(wSWA)。在訓(xùn)練結(jié)束后,它將是用于預(yù)測(cè)的最終模型。
第二個(gè)模型(w)將穿過(guò)權(quán)重空間,基于周期性學(xué)習(xí)率規(guī)劃探索權(quán)重空間。
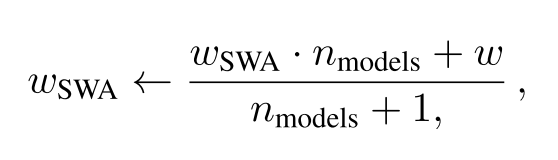
SWA權(quán)重更新公式;
在每個(gè)學(xué)習(xí)率周期的末尾,第二個(gè)模型的當(dāng)前權(quán)重將用來(lái)更新第一個(gè)模型的權(quán)重(公式見上)。因此,訓(xùn)練階段中,只需訓(xùn)練一個(gè)模型,并在內(nèi)存中儲(chǔ)存兩個(gè)模型。預(yù)測(cè)時(shí)只需要平均模型,基于其進(jìn)行預(yù)測(cè)將比之前描述的集成快很多,因?yàn)樵诩芍校阈枰褂枚鄠€(gè)模型進(jìn)行預(yù)測(cè),最后進(jìn)行平均。
-
集成
+關(guān)注
關(guān)注
1文章
176瀏覽量
30231 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100719 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5500瀏覽量
121113
原文標(biāo)題:權(quán)重空間集成學(xué)習(xí)背后的直覺(jué)
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
粒子群優(yōu)化模糊神經(jīng)網(wǎng)絡(luò)在語(yǔ)音識(shí)別中的應(yīng)用
求助基于labview的神經(jīng)網(wǎng)絡(luò)pid控制
如何構(gòu)建神經(jīng)網(wǎng)絡(luò)?
卷積神經(jīng)網(wǎng)絡(luò)一維卷積的處理過(guò)程
圖像預(yù)處理和改進(jìn)神經(jīng)網(wǎng)絡(luò)推理的簡(jiǎn)要介紹
卷積神經(jīng)網(wǎng)絡(luò)模型發(fā)展及應(yīng)用
優(yōu)化神經(jīng)網(wǎng)絡(luò)訓(xùn)練方法有哪些?
基于人工免疫網(wǎng)絡(luò)的神經(jīng)網(wǎng)絡(luò)集成方法
基于免疫聚類的神經(jīng)網(wǎng)絡(luò)集成的研究
改進(jìn)PSO優(yōu)化神經(jīng)網(wǎng)絡(luò)算法的人體姿態(tài)識(shí)別_何佳佳
BP神經(jīng)網(wǎng)絡(luò)風(fēng)速預(yù)測(cè)方法
一種改進(jìn)的自適應(yīng)遺傳算法優(yōu)化BP神經(jīng)網(wǎng)絡(luò)
改進(jìn)人工蜂群算法優(yōu)化RBF神經(jīng)網(wǎng)絡(luò)的短時(shí)交通流預(yù)測(cè)模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論