 一種基于前后信息的糾錯算法
一種基于前后信息的糾錯算法
摘要:針對傳統方法在人體行為識別方面拓展性不強等問題,提出一種序列化的研究思想,提取骨骼圖的特征矢量,用SVM訓練和識別靜態動作,形成序列即可表示動態動作,因此只要豐富靜態動作庫,就可以實現多種動態動作的識別,具有很好的拓展性。為了減少靜態動作識別錯誤產生的影響,提出一種基于前后信息的糾錯算法。實驗表明,該算法具有較高的識別準確率,并且具有很好的魯棒性和實時性。
0引言
隨著科學技術的發展,計算機的運算能力大大提升,針對大數據的處理漸漸得以實現。在此基礎上發展而來的人體行為姿態識別為人機交互、視頻監控和智能家居等方面的應用提供了基礎。近些年,研究人員已經在人體行為識別方面做了大量的研究工作,取得了許多重要的成果,但是對于復雜人體行為的識別準確率較低,仍然有待于提高。
基于視覺的人體行為識別方法[2]可以分為兩類,一類基于模板匹配[3],一類基于機器學習[4]。基于模板匹配的方法通過計算當前動作與模板庫里的模板之間的相似度,把當前模板判定為最相似動作的過程。IBANEZ R和SORIA A等人通過提取人體肢體行為軌跡,分別用動態時間規整(DTW)和隱馬爾科夫(HMM)算法,基于模板匹配進行人體行為識別[5]。基于機器學習的方法通過提取樣本特征對樣本訓練,得到一個分類器,此分類器具有預測未知樣本的能力。TRIGUEIROS P和RIBEIRO F等人就對比了幾種機器學習算法在手勢識別上的應用[6]。但是,這些算法都是為某一具體行為動作所設計,當需要檢測額外的行為動作時,又需要重新設計方案,拓展性較差。
本文使用從Kinect[7]采集的骨骼圖數據(由MSRC-12 Gesture Dataset數據庫[8]提供),Kinect提取的骨骼圖像能夠克服光線強弱等外界因素帶來的干擾,具有較強的魯棒性;提取骨骼特征,并采用機器學習的算法對靜態動作分類,最終形成序列;從序列中找出需要識別的動作序列的過程即可表示動態動作識別過程,此過程具有很好的實時性和拓展性。
1基于骨骼圖的特征提取
選取既能夠充分表示人體某一動作,又不包含過多的冗余信息的人體特征特征提取對行為識別的研究很有價值。根據人體機械學理論,本文通過提取4個關節點向量、5個關節點角度和4個關節點距離系數表示人體行為姿態。
1.1關節點向量提取
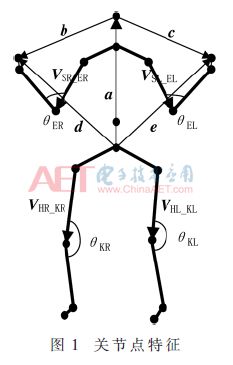
如圖1所示,4個關節點向量分別是左上臂(VSL-EL)、右上臂(VSR-ER)、左大腿(VHL-KL)和右大腿(VHR-KR)。現以左上臂為例,計算左上臂向量。已知左肩膀(ShoulderLeft)關節點坐標為SL(Sx,Sy,Sz),左手肘(ElbowLeft)關節點坐標為EL(Ex,Ey,Ez),則左上臂關節點向量計算方法如式(1)所示。其他關節點向量以此類推。
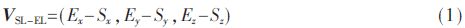
1.2關節點角度提取
在原有向量的基礎上提取4個關節點角度。聯合關節點向量,可以描述人體左小臂、右小臂、左小腿和右小腿的活動狀態。圖1中θEL、θER、θKL和θKR分別表示左肘關節點角度、右肘關節點角度、左膝關節點角度和右膝關節點角度。θHC表示臀部中心到頭部的向量與豎直方向向量之間的夾角,可以表示人體姿態的彎腰程度,描述整體軀干的活動狀態。夾角可以通過式(2)計算獲得。

其中V1、V2分別表示兩個關節點向量,θ表示這兩個關節點向量的夾角。
1.3關節點距離系數提取
為了能夠讓選取特征對上肢手部活動更加敏感,本文加入4個關節點距離系數。圖1中,a為臀部中心到頭部的關節向量,b為頭部到右手的關節向量,c為頭部到左手的關節向量,d為臀部中心到右手的關節向量,e為臀部中心到左手的關節向量。通過式(3)可以獲得頭部到左右手的相對距離系數d1、d2和臀部中心到左右手的相對距離系數d3、d4。

至此,基于骨骼圖的特征可以表示為式(4)所示的特征矩陣,共計4×3+5+4=21維。

2基于SVM的識別算法流程
支持向量機[9](Support Vector Machines,SVM)是一種用于分類的算法,它能夠在多維空間找出完美劃分事物的超平面。本文使用SVM進行動作分類,以二分類支持向量機為例,已知訓練樣本集T:

使用多個二分類器形成多分類器,用豐富的樣本訓練并識別人體靜態姿勢。
2.2動態動作的序列化識別
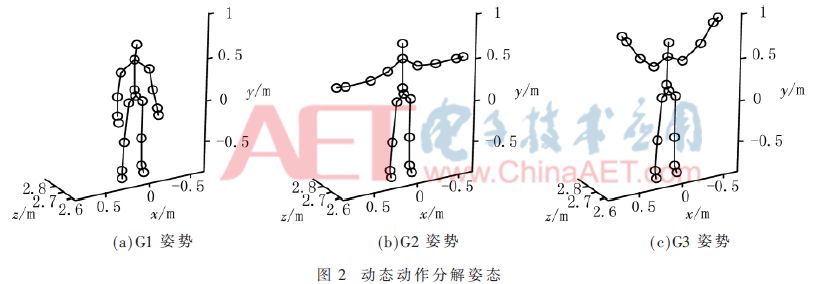
設定某一采樣頻率,所提取到每一幀骨骼圖都以靜態的方式呈現。對每一幀骨骼圖進行靜態動作識別,可以得到一串長序列。在長序列中尋找待識別序列即為動態動作識別。如圖2所示,一組抬起雙手舉高(Start system)的動作可以分解為G1、G2、G3 3個靜態動作,因此只要在長序列中檢測到連續的G1、G2、G3 3個靜態動作即可判定出現“抬起雙手舉高”的動態動作。
2.3分類的糾錯過程
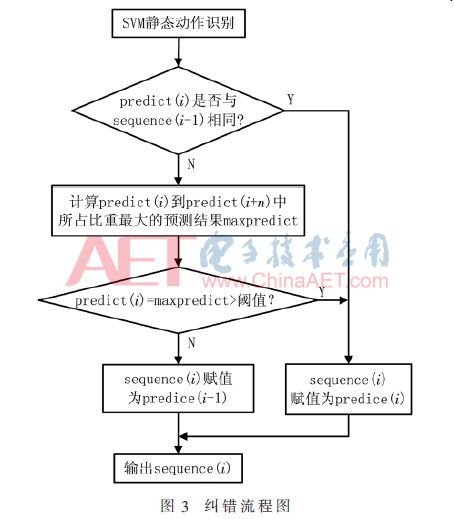
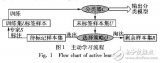
為了減小靜態姿勢識別錯誤對動態動作識別準確率的影響,本文提出一種基于前后信息的姿態糾正算法。一般情況下,相鄰兩幀或者多幀的數據描述的都是同一動作。算法流程圖如圖3所示,其中predict是分類器預測的結果,sequence是最終形成的長序列。首先判斷當前預測結果是否與長序列隊尾數據相同,如果相同,說明當前動作與上一幀動作相同,把預測結果加入長序列隊尾;如果不相同,需要驗證當前預測結果是否出錯。此算法判斷當前動作之后的n(本文選取15)幀預測結果中出現最多的數據是否等于當前動作預測結果,并且其所占比是否大于某一閾值(本文選取0.5),如果是,將當前動作的預測結果加入長序列隊尾;如果否,說明當前動作預測結果出錯,長序列隊尾數據保持不變。
3實驗驗證
3.1訓練靜態動作
MSRC-12 Gesture Dataset是微軟提供的數據庫,共包括12組動作。本文選擇其中3組動作,分別為Start system、Duck和Push right,如圖2、圖4和圖5所示。

顯然,大多數志愿者保持某一靜態動作的時間并不一致。為了合理利用資源和方便處理,把姿勢劃分為進行態和保持態兩種狀態:
(1)進行態是一組動作的中間狀態,即兩種靜態姿態的過度,可包含運動過程中較大范圍的運動姿態,圖2(b)的G2和圖5(b)中的G5即是進行態。因為進行態不能對決策結果起決定性作用,所以進行態并不需要非常高的識別精確度。
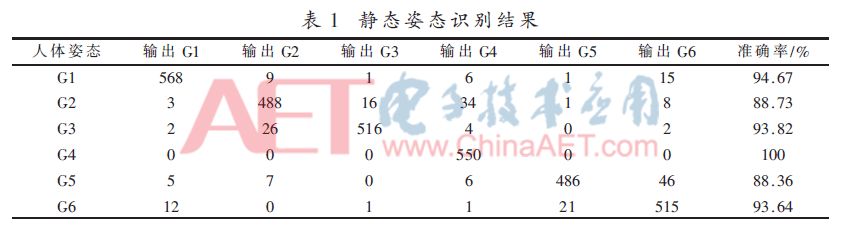
(2)保持態是一組動作中保持時間較長的狀態,能夠對姿勢的識別起決定性作用,因此需要很高的識別準確率。圖2(a)中的G1、圖2(c)中的G3、圖4(b)中的G4以及圖5(c)中的G6都屬于保持態。實驗中,從10人中選取600幀G1姿勢,5人中選取550幀G2、G3、G4、G5和G6姿勢,共3 350幀數據,用于訓練分類器,SVM識別結果見表1。
3.2靜態動作結果分析
采用十折交叉驗證法檢驗分類器的性能,最終得到的平均識別準確度為93.12%。表1為單個姿態的識別準確度。從表1可以看出,位于保持態的姿態識別準確率普遍在90%以上,達到較高的準確率。進行態姿態識別準確率比保持態稍低,但是從前文可知,這對最終的判定結果影響不大。
3.3序列糾錯
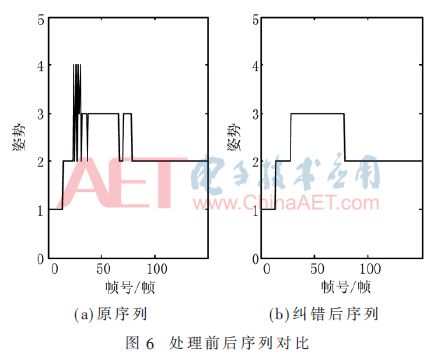
采用2.3節所述的方法進行姿態序列糾錯。不失一般性,從實驗的3 350幀數據中隨機選取150幀數據(原序列)為例,見圖6(a)。在原序列第30幀左右,姿勢2(G2)向姿勢3(G3)過度階段出現了較多錯分類現象。圖6(b)是采用2.3節方法糾錯后序列,可以看出,整個序列變得光滑得多,上述的分類錯誤得到了抑制,大大方便了后續動作識別。
3.4態動作識別驗證
為便利于分析,將經過糾錯處理的數據中連續的n個“1”用一個“1”表示,其他姿態以此類推。以Start system為例,當檢測到連續的1,2,3或者1,3則可以判定出現一組Start system動作,當檢測到連續的1,2,3,2,1、1,2,3,1、1,3,2,1、1,3,1則判定完成Start system動作并回到站姿(G1)。用MSRC-12 Gesture Dataset數據測試,測試結果見表2。為了對比算法的優劣,表2中同時列出了文獻[10]的隨機森林算法的識別情況。

由表2明顯可以看出,與文獻[10]的算法相比,本文提出的算法的識別準確率更高。通過實驗得知,Start system、Duck和Push right 3種動作具體的識別準確率分別是71.82%、80%和76.36%。
4總結
本文算法可以實現實時提取骨骼數據,計算骨骼特征,分類識別并形成序列,具有很好的實時性。序列化的動態動作識別方法可以滿足各種動作的任意組合,具有很好的拓展性。實驗表明,本文算法具有較高的識別準確率。但是,對采集到的每一幀骨骼圖進行分類無疑會增加算法復度。因此,如何降低冗余的分類識別,是下一步研究需要解決的問題。
-
人機交互
+關注
關注
12文章
1218瀏覽量
55677 -
識別算法
+關注
關注
0文章
44瀏覽量
10444
原文標題:【學術論文】人體行為序列化識別算法研究
文章出處:【微信號:ChinaAET,微信公眾號:電子技術應用ChinaAET】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種基于混沌和小波變換的大容量音頻信息隱藏算法
一種實用的數據融合算法
一種新的自糾錯句對齊算法的研究與實現
一種安全的糾錯網絡編碼
一種利用顏色信息的車牌字符分割新算法
用FPGA實現糾錯編碼的一種方法

一種改進的高速鏈路前向糾錯編碼

一種基于全局信息共享的自適應FA算法
一種結合未標簽信息的主動學習算法
一種融合局部紋理信息的改進PRICoLBP算法
一種新聞關鍵信息的提取算法





 工商網監
工商網監
評論