 帶有TensorRT的JetPack 2.3加倍Jetson TX1深度學習推理
帶有TensorRT的JetPack 2.3加倍Jetson TX1深度學習推理
深度神經網絡(DNN)是實現強大的計算機視覺和人工智能應用的強大方法。今天發布的NVIDIA Jetpack 2.3使用NVIDIATensorRT(以前稱為GPU推理引擎或GIE)將嵌入式應用中的DNN的運行性能提高了兩倍以上。NVIDIA推出的1 TFLOP / s嵌入式Jetson TX1模塊可以部署在無人機和智能機器上,與推理工作負載相比,功耗高出Intel i7 CPU 20倍。Jetson和深度學習力量 - 自主性和數據分析方面的最新進展,如超高性能Teal無人機如圖1所示。JetPack包含全面的工具和SDK,可簡化為主機和嵌入式目標平臺部署核心軟件組件和深度學習框架的過程。
圖1:能夠飛行85英里每小時,輕量級Teal無人機采用NVIDIA Jetson TX1和即時深入學習。
JetPack 2.3具有新的API,可用于使用Jetson TX1進行高效的低級相機和多媒體流式傳輸,以及Linux For Tegra(L4T)R24.2與Ubuntu 16.04 aarch64和Linux內核3.10.96的更新。JetPack 2.3還包括CUDA Toolkit 8.0和cuDNN 5.1,它們為卷積神經網絡(CNN)和高級網絡(如RNN和LSTM)提供GPU加速支持。為了高效地將數據流入和流出算法流水線,JetPack 2.3添加了新的Jetson Multimedia API包,以支持基于KhronosOpenKCam的低級硬件V4L2編解碼器和每幀相機/ ISP API。
JetPack中包含的這些工具為部署實時深度學習應用程序及其后續工作奠定了基礎。請參閱下面的完整軟件列表。為了讓您入門,JetPack還包含深度學習示例和關于培訓和部署DNN的端到端教程。
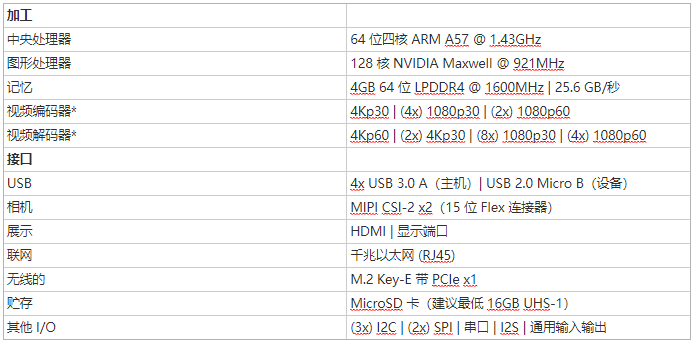
JetPack 2.3組件
Linux4Tegra R24.2TensorRT 1.0.2 RCVisionWorks 1.5.2.14Ubuntu 16.04 64位LTSCUDA工具包8.0.34OpenCV4Tegra 2.4.13-17Jetson Multimedia API R24.2cuDNN 5.1.5GStreamer 1.8.1Tegra系統分析器3.1.2Tegra圖形調試器2.3.16OpenGL 4.5.0TensorRT
現在通過JetPack 2.3可用于Linux和64位ARM,NVIDIA TensorRT可最大限度地提高神經網絡在Jetson TX1或云中的生產部署的運行性能。通過可訪問的C ++接口提供神經網絡prototext和訓練好的模型權重后,TensorRT執行流水線優化,包括內核融合,層自動調整和半精度(FP16)張量布局,從而提高性能并提高系統效率。關于TensorRT及其圖形優化背后的概念,請參閱此并行Forall文章。圖2中的基準測試結果比較了GPU加速的Caffe和TensorRT之間的谷歌網絡圖像識別網絡的推理性能,這兩種網絡都支持FP16擴展,并且在一系列的批量大小上進行了比較。(與FP32相比,FP16模式不會導致分類精度損失。)
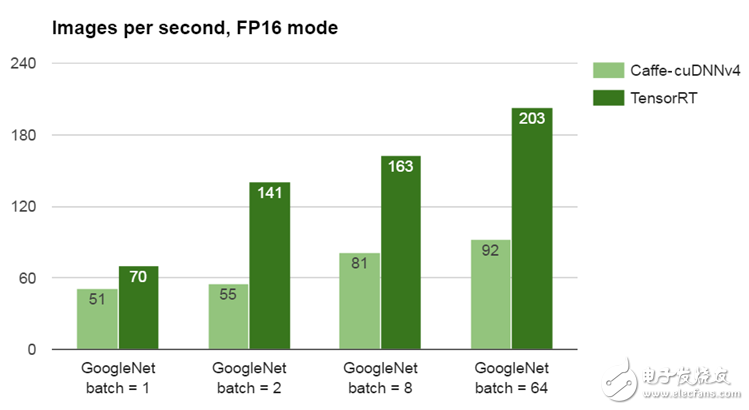 圖2:使用FP16模式和批量大小為2的Jetson TX1上運行GoogleNet時,TensorRT將Caffe的性能提高了一倍以上。
圖2:使用FP16模式和批量大小為2的Jetson TX1上運行GoogleNet時,TensorRT將Caffe的性能提高了一倍以上。
性能的衡量標準是使用TensorRT或Caffe優化的nvcaffe / fp16分支,使用GoogleNet處理的每秒圖像數。測試使用平面BGR 224×224圖像,GPU內核時鐘頻率調節器最高為998MHz。批量大小表示網絡一次處理了多少個圖像。
圖2的基準結果顯示,TensorRT和Caffe之間的推斷性能在批量大小為2時提高了2倍以上,并且單幅圖像的改進大于30%。盡管使用批量大小1可以在單個數據流上提供最低的瞬時延遲,但同時處理多個數據流或傳感器的應用程序,或執行窗口化或感興趣區域(ROI)子采樣的應用程序,可能會使批量大小2.可支持更高批量(例如8,64或128)的應用程序(例如數據中心分析)可實現更高的整體吞吐量。
比較功耗顯示GPU加速的另一個優點。如圖3所示,帶有TensorRT的Jetson TX1在運行Caffe和MKL 2017的英特爾i7-6700K Skylake CPU上進行深度學習推理的效率是其18倍。
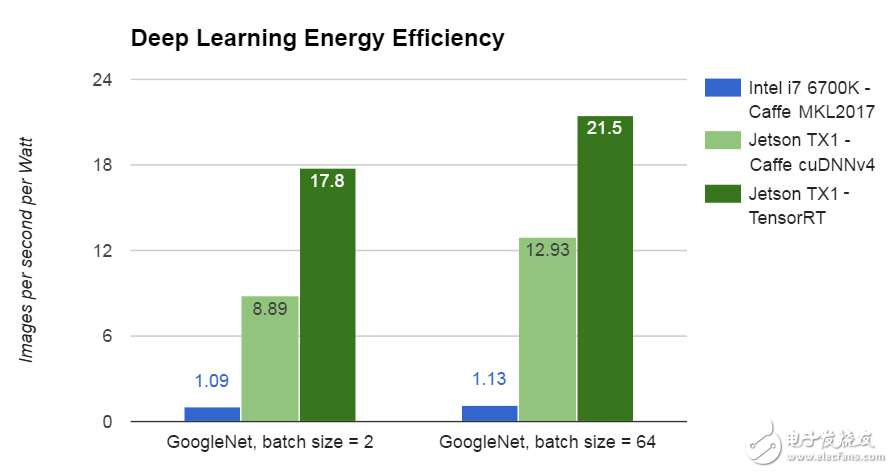 圖3:在深度學習推理中,Jetson TX1的功率效率比CPU高20倍。
圖3:在深度學習推理中,Jetson TX1的功率效率比CPU高20倍。
圖3的結果是通過將測量的每秒處理的GoogleNet圖像除以基準期間處理器的功耗來確定的。這些結果使用批量大小2,盡管批量大小64 Jetson TX1能夠以21.5 GoogleNet圖像/秒/瓦的速度。從網絡層規范(原型文件)開始,TensorRT在網絡層和更高層執行優化;例如,融合內核并每次處理更多層,節省系統資源和內存帶寬。
通過將TensorRT連接到攝像頭和其他傳感器,可以實時評估深度學習網絡的實時數據。對于實現導航,運動控制和其他自治功能很有用,深度學***減少了實現復雜智能機器所需的硬編碼軟件數量。請參閱此GitHub回購,以獲取使用TensorRT快速識別Jetson TX1車載攝像頭的對象以及定位視頻輸入中行人坐標的教程。
除了快速評估神經網絡之外,TensorRT還可以與NVIDIA的DIGITS工作流程一起有效地用于交互式GPU加速網絡培訓(見圖4)。DIGITS可以在云中運行,也可以在桌面本地運行,并且可以使用Caffe或Torch提供簡單的配置和網絡培訓的交互式可視化。有多個DIGITS演練示例可用于開始使用您自己的數據集來培訓網絡。DIGITS在每個訓練時期保存模型快照(通過訓練數據)。所需的模型快照或.caffemodel以及網絡原型文件規范被復制到Jetson TX1,TensorRT加載并解析網絡文件并構建優化的執行計劃。
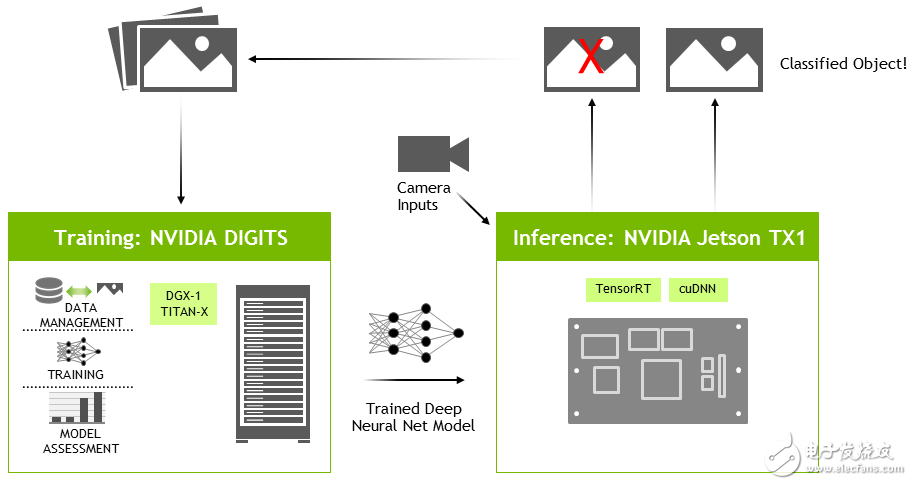 圖4:用于在獨立GPU上訓練網絡并在Jetson TX1上部署TensorRT的DIGITS工作流程。
圖4:用于在獨立GPU上訓練網絡并在Jetson TX1上部署TensorRT的DIGITS工作流程。
使用DIGITS與DGX-1超級計算機進行培訓,以及Jetson上的TensorRT,NVIDIA的完整計算平臺使各地的開發人員能夠利用端到端的深度學習解決方案部署先進的人工智能和科學研究。
CUDA工具包8.0和cuDNN 5.1
CUDA Toolkit 8.0包含針對Jetson TX1的集成NVIDIA GPU的CUDA的最新更新。主機編譯器支持已更新為包含GCC 5.x,NVCC CUDA編譯器已進行了優化,編譯速度提高了2倍。CUDA 8包含nvGRAPH,這是GPU加速圖形算法的新庫,如PageRank和單源最短路徑。CUDA 8還包含新的API,用于在CUDA內核以及cuBLAS和cuFFT等庫中使用半精度浮點運算(FP16)。cuDNN,CUDA深度神經網絡庫5.1版支持最新的高級網絡模型,如LSTM(長期短期記憶)和RNN(循環神經網絡)。看到這個并行Forall現在支持cuDNN的RNN模式,包括ReLU,門控循環單元(GRU)和LSTM。
cuDNN已被納入所有最流行的深度學習框架,包括Caffe,Torch,CNTK,TensorFlow等。使用與cuDNN綁定編譯的Torch,最近可用的網絡(如LSTM)支持深層強化學習等領域的功能,其中人工智能代理學習如何基于傳感器狀態和來自獎勵功能的反饋在現實世界或虛擬環境中聯機運行。通過釋放深度強化學習者來探索他們的環境并適應不斷變化的條件,人工智能代理開發理解并采用復雜的預測和直觀的類人行為。該OpenAI健身房項目中有許多虛擬環境用于訓練AI代理的例子。在具有非常復雜的狀態空間的環境中(如許多真實世界場景中的情景),深度神經網絡被強化學習者用來通過估計未來來選擇下一個動作基于感官輸入的潛在獎勵(通常稱為Q學習和深度Q學習網絡:DQN)。由于為了將傳感器狀態(如高分辨率攝像機和LIDAR數據)映射為代理可以執行的每個潛在動作的輸出,DQN通常非常大,因此cuDNN對于加速強化學習網絡至關重要,因此AI代理保持交互性并且可以實時學習。圖5顯示了我為在Jetson TX1上實時學習而編寫的DQN的輸出。這個例子的代碼,可在GitHub上獲得,使用cuDNN綁定在Torch中實現,并具有用于集成到機器人操作系統(ROS)等機器人平臺的C ++庫API。
圖5:深層強化Q-learning Network(DQN)在Jetson TX1上運行游戲和模擬時學習。
在許多現實世界的機器人應用和傳感器配置中,完全可觀察的狀態空間可能無法使用,因此網絡無法保持對整個環境狀態的即時感知訪問。來自cuDNN的GPU加速LSTM在解決部分可觀測性問題方面特別有效,依賴于LSTM編碼的存儲器來記憶先前的經驗并將觀測連鎖在一起。LSTM在具有語法結構的自然語言處理(NLP)應用程序中也很有用。
Jetson多媒體SDK
JetPack 2.3還包含新的Jetson Multimedia API軟件包,為開發人員提供低級API訪問,以便在使用Tegra X1硬件編解碼器,MIPI CSI Video Ingest(VI)和圖像信號處理器(ISP)時靈活地開發應用程序。這是以前版本中提供的GStreamer媒體框架的補充。Jetson多媒體API包括攝像頭攝取和ISP控制,以及Video4Linux2(V4L2),用于編碼,解碼,縮放等功能。這些較低級別的API可以更好地控制底層硬件塊。
V4L2支持可訪問視頻編碼和解碼設備,格式轉換和縮放功能,包括支持EGL和高效內存流。用于編碼的V4L2打開了許多功能,如比特率控制,質量預設,低延遲編碼,時間折衷,提供運動矢量地圖等等,以實現靈活而豐富的應用程序開發。通過添加強大的錯誤和信息報告,跳幀支持,EGL圖像輸出等,解碼器功能得到顯著增強。VL42公開了Jetson TX1強大的視頻硬件功能,用于圖像格式轉換,縮放,裁剪,旋轉,濾波和多個同步流編碼。
為了幫助開發人員將深度學習應用程序與數據流源快速集成,Jetson Multimedia API包含了與TensorRT一起使用V4L2編解碼器的強大實例。多媒體API包中包含圖6中的對象檢測網絡示例,該示例源自GoogleNet,并通過V4L2解碼器和TensorRT傳輸預編碼的H.264視頻數據。
圖6:Jetson Multimedia SDK附帶的修改后的GoogleNet網絡以全動態視頻檢測汽車邊框。
與核心圖像識別相比,除了分類以外,物體檢測還提供了圖像內的邊界位置,使其對追蹤和避障有用。多媒體API示例網絡源自GoogleNet,具有用于提取邊界框的附加圖層。在960×540半高清輸入分辨率下,物體檢測網絡捕獲的分辨率高于原始GoogleNet,同時使用TensorRT在Jetson TX1上保留實時性能。
Jetson Multimedia API包中的其他功能包括ROI編碼,它允許定義一個幀中最多6個感興趣的區域。這通過允許僅為感興趣的區域分配較高的比特率來實現傳輸和存儲帶寬優化。為了進一步促進CUDA和OpenGL之類的API與EGLStreams之間的高效流式傳輸,NV dma_buf結構在Multimedia API中公開。
相機ISP API
基于Khronos OpenKCam,低級攝像機/ ISP API libargus提供針對攝像機參數和EGL流輸出的細粒度的每幀控制,以實現與GStreamer和V4L2流水線的有效互操作。相機API為開發人員提供了對MIPI CSI相機視頻攝取和ISP引擎配置的低級訪問。樣本C ++代碼和API參考也包含在內。以下示例代碼片段搜索可用攝像頭,初始化攝像頭流并捕獲視頻幀。
#包括<阿格斯/?Argus.h>#include #include #包括#包括使用名稱空間Argus;使用名稱空間Argus;//列舉相機設備并創建Argus會話//列舉相機設備并創建Argus會話UniqueObjcameraProvider(CameraProvider::create());UniqueObjcameraProvider(CameraProvider::create());CameraProvider*iCameraProvider=interface_cast(cameraProvider);CameraProvider*iCameraProvider=interface_cast(cameraProvider);std::vector 相機;::vector相機;狀態狀態=iCameraProvider->getCameraDevices(&cameras);狀態狀態=iCameraProvider->getCameraDevices(&cameras);UniqueObjcaptureSession(iCameraProvider->createCaptureSession(cameras[0],UniqueObjcaptureSession(iCameraProvider->createCaptureSession(cameras[0], &狀態));&status));ICaptureSession*iSession=interface_cast(captureSession);ICaptureSession*iSession=interface_cast(captureSession);//配置攝像機輸出流參數//配置攝像機輸出流參數UniqueObjstreamSettings(iSession->createOutputStreamSettings());UniqueObjstreamSettings(iSession->createOutputStreamSettings());IOutputStreamSettings*iStreamSettings=interface_cast(streamSettings);IOutputStreamSettings*iStreamSettings=interface_cast(streamSettings); iStreamSettings->setPixelFormat(PIXEL_FMT_YCbCr_420_888);->setPixelFormat(PIXEL_FMT_YCbCr_420_888);iStreamSettings->setResolution(Size(640,480));->setResolution(大小(640,480));//將相機輸出連接到EGLStream//將相機輸出連接到EGLStreamUniqueObj流(iSession->createOutputStream(streamSettings.get()));UniqueObj流(的Isession->createOutputStream(streamSettings。獲得()));UniqueObj使用者(EGLStream::FrameConsumer::create(stream.get()));UniqueObj消費者(EGLStream::FrameConsumer::創建(流。獲得()));EGLStream::IFrameConsumer*iFrameConsumer=interface_cast(consumer);EGLStream::IFrameConsumer*iFrameConsumer=interface_cast(consumer);//從EGLStream獲取一幀//從EGLStream獲取一幀constuint64_tFIVE_SECONDS_IN_NANOSECONDS=5000000000;constuint64_tFIVE_SECONDS_IN_NANOSECONDS=5000000000;UniqueObj框架(iFrameConsumer->acquireFrame(FIVE_SECONDS_IN_NANOSECONDS,UniqueObj框架(iFrameConsumer->acquireFrame(FIVE_SECONDS_IN_NANOSECONDS, &狀態));&status));EGLStream::IFrame*iFrame=interface_cast(frame);EGLStream::IFrame*iFrame=interface_cast(frame);EGLStream::Image*image=iFrame->getImage();EGLStream::Image*image=iFrame->getImage();
所述杰特森TX1開發工具包包括與所述豪威OV5693 RAW圖像傳感器的5MP相機模塊。現在通過相機API或GStreamer插件啟用對該模塊的ISP支持。Leopard Imaging公司的IMX185可以通過相機/ ISP API(見Leopard Imaging的Jetson相機套件)完全支持來自Leopard Imaging的IMX185的2.1MP相機。ISP通過首選合作伙伴服務支持額外的傳感器。此外,USB攝像頭,集成了ISP的CSI攝像頭和ISP旁路模式下的RAW輸出CSI攝像頭可用于V4L2 API。
展望未來,所有相機設備驅動程序都應該使用V4L2介質控制器傳感器內核驅動程序API - 請參閱V4L2傳感器驅動程序編程指南了解詳細信息以及基于Developer Kit相機模塊的完整示例。
智能機器無處不在
JetPack 2.3包含用于部署使用NVIDIA Jetson TX1和GPU技術的生產級高性能嵌入式系統的所有最新工具和組件。NVIDIA GPU借助深度學習和人工智能的最新突破,用于解決日常面臨的重大挑戰。使用JetPack 2.3中的GPU和工具,任何人都可以開始設計高級AI來解決實際問題。訪問NVIDIA的深度學習研究院,獲取實踐培訓課程以及這些Jetsonwiki資源的深度學習資源。NVIDIA的JetsonTX1DevTalk論壇也可用于與社區開發人員進行技術支持和討論。下載JetPack今天并為Jetson和PC安裝最新的NVIDIA工具。
-
NVIDIA
+關注
關注
14文章
4978瀏覽量
102990 -
深度神經網絡
+關注
關注
0文章
61瀏覽量
4524
發布評論請先 登錄
相關推薦
機器人平臺JetPack 3.1使Jetson的低延遲推斷性能翻了一番

TX1接收模塊
NVIDIA 3D視覺技術硬件設計開發:Jetson TX1
發送有SPI_TX0/SPI_TX1/TDATA寄存器,先寫TX0再寫TX1表示發送完TX0數據再發送TX1數據嗎?
NVIDIA Jetson TX2將智能提升兩倍
NVIDIA TensorRT 8.2將推理速度提高6倍
如何使用框架訓練網絡加速深度學習推理

Jetson Nano開發者套件面向所有人的人工智能
NVIDIA Isaac Initiative應用在領域訓練和部署高級AI中

使用NVIDIA TensorRT部署實時深度學習應用程序
NVIDIA Jetson TX1模塊驅動下一波自主機器
NVIDIA Jetson TX2 將深度學習推理提升至兩倍
學習資源 | NVIDIA TensorRT 全新教程上線

Torch TensorRT是一個優化PyTorch模型推理性能的工具






 工商網監
工商網監
評論