 通俗易懂的方式講解深度學習和機器學習算法
通俗易懂的方式講解深度學習和機器學習算法
擅長用通俗易懂的方式講解深度學習和機器學習算法,熟悉Tensorflow,PaddlePaddle等深度學習框架,負責過多個機器學習落地項目,如垃圾評論自動過濾,用戶分級精準營銷,分布式深度學習平臺搭建等,都取了的不錯的效果。
本文寫作于2017年10月26日
昨天看到某位"大牛"寫了篇文章,上了首頁推薦,叫做"跟著弦哥學人工智能",看到標題還挺驚喜,畢竟在博客園這個以.net文章為主的技術論壇居然還有大佬愿意寫AI方面的文章,于是點擊去仔細看了看,發現文風浮夸,恩,沒關系,有干貨就行,結果翻到最后也沒發現啥干貨,看到了參考書目,挺有意思的。放個圖在這:

當時看到這個參考書目挺迷的,數學類從高中數學推薦到數學專業學生看的數學分析,計算機算法類一上來就推薦大塊頭的《算法導論》和理論性偏強的《數據挖掘:概念與技術》,認為這樣入門的人來說并不合適。看書應當是有階梯型的,不能一口吃成個大胖子,基于不想"大牛"誤人子弟,于是我給出了如下建議:

我的回復很平和,也給出了一些對新手比較友好的建議,并且有6個人支持我,想想算了,然而,今天,在首頁中又看到了這位"大牛"在博文罵我是噴子:
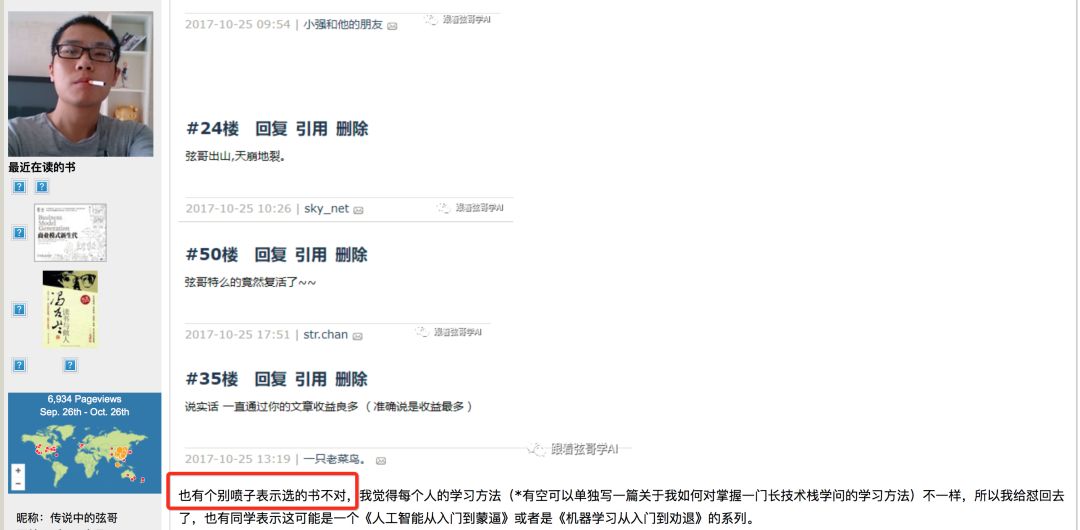
這我就不贊同而且不能忍了。對于任何人,不管你是大牛還是小白,我的原則都是,你可以反駁我的建議,有理有據就行,如果我錯了,那就改,沒有錯,那就互相討論,交流一下,氣場合說不定還能成為個朋友呢。但是對于別人真誠的建議您回以"噴子"是一個有教養的人的表現嗎?仗著自己是"大牛",這樣沒有素質的懟不覺得臉紅嗎?并且,我之所以給出這個建議,有以下三點:
1.作為一個數學系的學生,學了四年數學,對于你胡亂給的參考書目非常的不贊同。一沒有階梯式,對新手不友好,您的標題和寫這個系列的目的大概都是準備給小白看的,那么請問,一個小白需要看數學分析原理??學習人工智能有必要需要看普林斯頓微積分原理??以鄙人淺薄的認識來說,數學分析與高等數學最大的區別是同一個定理,高數只要求會用即可,數學分析本著嚴謹性,一定會給出證明。然而對于大多數人工智能里所需要的數學,您在工作中需要證明這個定理的正確性和完備性??等你證出來恐怕項目早就結了。您回復我說這只是參考書目不是推薦書目,但是下面的評論大多數是看到書單就決定放棄。您把這些書放出來,就對看您文章的人有一定的引導性,我認為您這是在誤人子弟。二是我通過您參考的數目粗略的推導您自己可能都沒有對整個人工智能的數學有個框架式的梳理,不然不會有如此不負責任的推薦。但是出于對您的尊重,我并沒有質疑您的能力,僅僅在評論里對于新手適合的數學書目給了一個簡短的推薦。
2.作為一個從事機器學習這一行兩年多的程序媛,看到您推薦的計算機系列也認為非常的不靠譜。您推薦的這些書,我大部分都看過。尤其不推薦新手看的就是《算法導論》和《數據挖掘:概念與技術》,這兩本書又厚又重,雖然內容全面講的也不錯,但是等你看完都不知道猴年馬月了。新手需要的是什么?是上手!其次,《Python核心編程》您真的看完了嗎?這本書并不是給Python新人讀的,非常厚,而且有一定的難度,對于新手非常不友好。而且如果只是想做AI,那這本書的很多地方都不需要用到,web開發,Django框架對于我們AI工程師來說真的是必須的嗎?不是。小白對于一本書沒有重點和非重點的區分,花了大量的時間學了不需要的知識,真是得不償失。給出引導性,針對性的推薦才是負責任的推薦。
3.對于深度學習方面書籍的推薦我就不吐槽了。槽點太多,無力吐槽。省點力氣后面推薦真正適合不同階段的新手閱讀的書籍好了。
總結:這位大牛,我認為您可能在.net方面積累非常深,做的很好,吸引了一大波粉絲,這點我很佩服您。然而對于深度學習這一塊您可能并不是很了解。對于一個您并不是很了解的領域,在這里毫不謙虛,對于別人的建議充耳不聞,還很得意的罵人“噴子”,恐怕您還是要多謙虛一點,多學習學習。從從業年齡來看,我是您的后輩,但從從事深度學習這個領域來看,您可能還是個新人,您說呢?并且到目前為止,您發了兩篇文章在首頁,都沒有任何干貨,希望您趕緊拿干貨來打我的臉^_^
下面,開始輸出干貨。
AI處于目前的風口,于是很多人想要渾水摸魚,都來分一杯羹,然而可能很多人連AI是什么都不知道。AI,深度學習,機器學習,數據挖掘,數據分析這幾點的聯系和區別也搞不清楚。
我認為,深度學習這塊,有幾個層次:(自己胡亂起的名字,忽略吧 - -)
demo俠--->調參俠--->懂原理俠--->懂原理+能改模型細節俠--->超大數據操控俠--->模型/框架架構師
demo俠:下載了目前所有流行的框架,對不同框里的例子都跑一跑,看看結果,覺得不錯就行了,進而覺得,嘛,深度學習也不過如此嘛,沒有多難啊。這種人,我在面試的時候遇到了不少,很多學生或者剛轉行的上來就是講一個demo,手寫數字識別,cifar10數據的圖像分類等等,然而你問他這個手寫數字識別的具體過程如何實現的?現在效果是不是目前做好的,可以再優化一下嗎?為什么激活函數要選這個,可以選別的嗎?CNN的原理能簡單講講嗎?懵逼了。
調參俠:此類人可能不局限于跑了幾個demo,對于模型里的參數也做了一些調整,不管調的好不好,先試了再說,每個都試一下,學習率調大了準確率下降了,那就調小一點,那個參數不知道啥意思,隨便改一下值測一下準確率吧。這是大多數初級深度學習工程師的現狀。當然,并不是這樣不好,對于demo俠來說,已經進步了不少了,起碼有思考。然而如果你問,你調整的這個參數為什么會對模型的準確率帶來這些影響,這個參數調大調小對結果又會有哪些影響,就又是一問三不知了。
懂原理俠:抱歉我起了個這么蠢的名字。但是,進階到這一步,已經可以算是入門了,可以找一份能養活自己的工作了。CNN,RNN,LSTM信手拈來,原理講的溜的飛起,對于不同的參數對模型的影響也是說的有理有據,然而,如果你要問,你可以手動寫一個CNN嗎?不用調包,實現一個最基礎的網絡結構即可,又gg了。
懂原理+能改模型細節俠:如果你到了這一步,恭喜你,入門了。對于任何一個做機器學習/深度學習的人來說,只懂原理是遠遠不夠的,因為公司不是招你來做研究員的,來了就要干活,干活就要落地。既然要落地,那就對于每一個你熟悉的,常見的模型能夠自己手動寫代碼運行出來,這樣對于公司的一些業務,可以對模型進行適當的調整和改動,來適應不同的業務場景。這也是大多數一二線公司的工程師們的現狀。然而,對于模型的整體架構能力,超大數據的分布式運行能力,方案設計可能還有所欠缺,本人也一直在這個階段不停努力,希望能夠更進一步。
超大數據操控俠:到這一階段,基本上開始考慮超大數據的分布式運行方案,對整體架構有一個宏觀的了解,對不同的框架也能指點一二。海量數據的分布式運行如何避免網絡通信的延遲,如何更高效更迅速的訓練都有一定經驗。這類人,一般就是我這種蝦米的領導了。
模型/框架架構師:前面說了一堆都是對現有的框架/模型處理的經驗,這個階段的大俠,哦,不對,是大師可以獨立設計開發一套新框架/算法來應對現有的業務場景,或者解決一直未解決的歷史遺留問題。沒啥好說了,膜拜!
說了這么多,希望大家對自己找個清洗準確的定位,這樣才能針對性的學習。下面基于我個人的經驗對不同階段的學習者做一些推薦:
demo俠+調參俠:這兩個放在一起說,畢竟五十步笑百步,誰也沒有比誰強多少。當然也不要妄自菲薄,大家都是從這個階段過來的。這個階段編程不好的就好好練編程,原理不懂的就好好看書理解原理。動手做是第一位,然后不斷改一些模型的參數,看效果變化,再看背后的數學推導,理解原因,這樣比先看一大堆數學公式的推導,把自己繞的暈暈乎乎在開始寫代碼要好得多。
推薦書目:
數學類:
高等數學(同濟第七版):沒錯我說的就是考研的那本參考書,真心不錯,難易適中,配合相應的視頻或者國外的一些基礎課程的視頻看,高數理解極限,導數,微分,積分就差不多了
高等數學(北大第三版):線性代數的書我看的不多,原來上學的時候學的是高等數學,不過不要緊,看前五章就行了。配合相應的視頻,掌握矩陣,行列式相關知識即可。
概率論:這個沒有特別推薦的,因為學的并是不很好,所以不做推薦誤人子弟。大家不管看什么書,只要掌握關鍵知識就行了。不能到時候問個貝葉斯你都不知道咋推吧 = =!
信息論:忘記是哪個出版社了的,很薄的一本,講的非常不錯。里面關于信息的度量,熵的理解,馬爾科夫過程都講的不錯(現在公司里沒有,我回去找找再補上來)。掌握這個知識,那么對于你理解交叉熵,相對熵這一大堆名字看起來差不多但是又容易弄混的東東還是不錯的。起碼你知道了為啥很多機器學習算法喜歡用交叉熵來做cost function~
編程類:
笨方法學Python(Learn Python the Hard Way)這本書對于完全沒有接觸過Python,或者說完全沒有接觸過編程的人來說非常適合。雖然很多人說Python這么簡單,一天/周/月就學會了,但是每個人的基礎是不一樣的,所以不要認為自己一天沒學會就很認為自己很蠢,你應該想這樣說的人很壞!不管怎么樣,這是一本真正的從零開始學Python的書
利用Python進行數據分析:這本書是Python的pandas這個包的詳細說明版。學習這個可以掌握一些pandas的基本命令。然而這不是重點,因為pandas出來大量數據實在太慢了,還可能會崩潰(不知道現在有沒有改善 - -!)重點是,通過學習這本書,對數據的操作有點感覺,熟悉基本的數據操作流程,里面所有的操作都可以用原生python來替代,不需要用到pandas這個包。找感覺,非常重要。
Python參考手冊:這本書只是作為一個工具書,當你遇到不會的時候翻翻書,鞏固一下(當然,事實可能是直接去google了),此類書不用全部從頭到尾刷完,查漏補缺即可(電子書就行)
算法類:
Deep Learning with Python:別看這又是一本英文書,但其實非常簡單易讀。這本書其實主要是一個demo例子的集合,用keras寫的,沒有什么深度,主要是消除你對深度學習的畏難情緒,可以開始上手做,對整體能夠做的事做一些宏觀的展現。可以說,這本書是demo俠的最愛啦!
Deep Learning:中文有翻譯版的出來了,不過我其實不太想放在這里,因為這本書其實很偏理論。有些章節講的是真不錯,有些地方你完了又會覺得,這是啥?這玩意有啥用?會把新手繞來繞去的。大家就先買一本鎮場子,有不懂的翻翻看,看不懂的就google,直接看論文,看別人總結的不錯的博客,等等。總之只要你能把不懂的弄懂就行了。
懂原理俠:很不錯,你的經驗值已經提升了不少了。然而還不能開始打怪,畢竟沒有那個怪物可以直接被噴死的。你缺少工具。那么這個階段,就需要多多加強編程能力。先找一個框架下下來,閱讀源碼,什么?你說你不會閱讀源碼,沒關系,網上一大堆閱讀源碼的經驗。當然,這些經驗的基礎無一例外都是:多讀多寫。在此基礎上再找trick。下好框架的源碼后,改動一些代碼在運行,debug一下,再不斷的找原因,看看每個api是怎么寫的,自己試著寫一寫。多謝多練,死磕coding三十年,你一定會有收獲的。
懂原理+能改模型細節俠:看論文看論文看論文!讀源碼讀源碼讀源碼!這里的讀源碼不僅僅局限于讀一個框架的源碼了,可以多看看其他優秀的框架,對于同一個層,同一個功能的實現機制,多比較多思考多總結多寫。時間長了,肯定會有收獲的。看論文是為了直接獲得原作者的思想,避免了從博客解讀論文里獲得二手思想,畢竟每個人的理解都不一樣,而且也不一定對,自己先看一遍,再看看別的理解,多和大牛討論,思路就開闊了。
超大數據操控俠:這個階段我也還在摸索,給不了太多建議,只能給出目前總結的一點點經驗:盡量擴大數據,看如何更快更好的處理。更快--采用分布式機制應該如何訓練?模型并行還是數據并行?多機多卡之間如何減少機器之間的網絡延遲和IO時間等等都是要思考的問題。更好--如何保證在提升速度的同時盡量減少精度的損失?如何改動可以提高模型的準確率、mAP等,也都是值得思考的問題。
模型/框架架構師:抱歉,我不懂,不寫了。
總結:
其實大家從我上面的推薦來看,打好基礎是非常重要的,后續都是不斷的多讀優秀的論文/框架,多比較/實踐和debug,就能一點點進步。打基礎的階段一定不能浮躁。扎扎實實把基礎打好,后面會少走很多彎路。不要跟風盲目崇拜,經典永遠不會過時,自己多看書/視頻/優秀的博客,比無腦跟風要強得多。最后,我之所以今天這么生氣,是因為這個行業目前太浮躁了,很多人太浮夸,誤人子弟,有人說真話還被人罵噴子,真是氣死我了!大家一定要擦亮雙眼,多靠自己多努力。
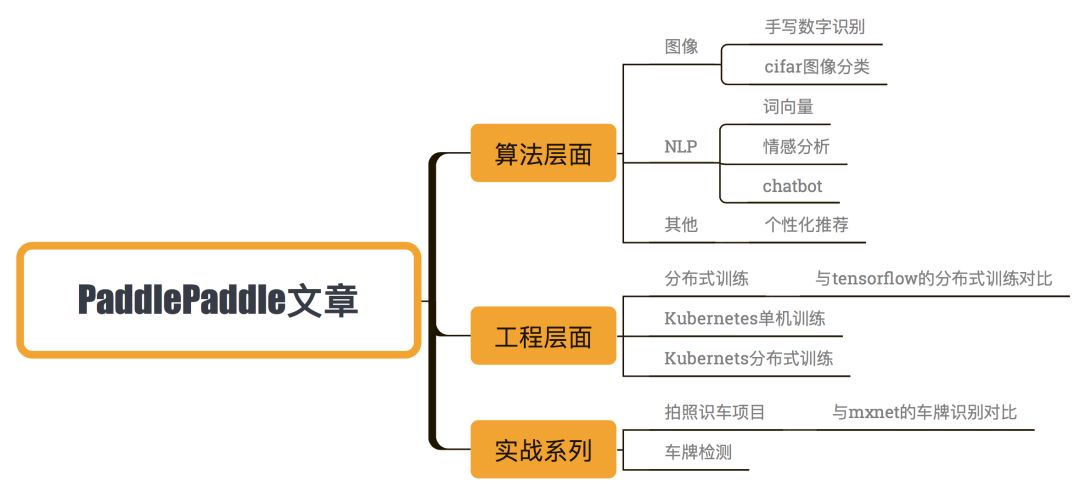
不好意思強行雞湯了一波。本來去年打算寫一個機器學習系列,但是因為工作和身體的原因寫了三篇就沒有更了。今年上半年做了一個大項目又累得要死,下半年才剛剛緩口氣,所以之前欠的后續一定會繼續更。為了不讓大家盲目崇拜,我決定寫一個深度學習系列,每周固定一篇,大概三個月完結。教小白如何入門。并且完!全!免!費!!不是簡單的寫寫網上都有的demo和調參。拒絕demo俠從我做起!有不懂的歡迎大家在我的文章下留言,我看到了會盡量回復的。這個系列主要會采取PaddlaPaddle這個深度學習框架,同時會對比keras,tensorflow和mxnet這三個框架的優劣(因為我只用過這四個,寫tensorflow的人太多了,paddlepaddle我目前用的還不錯,就決定從這個入手),所有代碼會放在github上(鏈接:https://github.com/huxiaoman7/PaddlePaddle_code),歡迎大家提issue和star。目前只寫了第一篇(【深度學習系列】PaddlePaddle之手寫數字識別),后面會有更深入的講解和代碼。目前做了個簡單的大綱,大家如果有感興趣的方向可以給我留言,我會參考加進去的~
最后一句,低調做人,好好學習,大家下期再會^_^!
-
python
+關注
關注
56文章
4792瀏覽量
84628 -
大數據
+關注
關注
64文章
8882瀏覽量
137401 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:【好書推薦&學習階段】三個月教你從零入門深度學習
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
機器學習和深度學習的區別在哪?看完就知道了
通俗易懂的PID教程
通俗易懂系列整合—電源基礎知識講解
FPGA通俗易懂入門書籍教程


通俗易懂的講解FFT的讓你快速了解FFT
關于機器學習通俗易懂的講解






 工商網監
工商網監
評論