 深入理解Linux RCU:RCU是讀寫鎖的替代者
深入理解Linux RCU:RCU是讀寫鎖的替代者
一、
RCU的用法
RCU最常用的目的是替換已有的機制,如下所示:
讀寫鎖
受限制的引用計數機制
批量引用計數機制
窮人版的垃圾回收器
存在擔保
類型安全的內存
等待事物結束
1.1 RCU是讀寫鎖的替代者
在Linux內核中,RCU最常見的用途是替換讀寫鎖。在20世紀90年代初期,Paul在實現通用RCU之前,實現了一種輕量級的讀寫鎖。后來,為這個輕量級讀寫鎖原型所設想的每個用途,最終都使用RCU來實現了。
RCU和讀寫鎖最關鍵的相似之處,在于兩者都有可以并行執行讀端臨界區。事實上,在某些情況下,完全可以用對應的讀寫鎖API來替換RCU的API,反之亦然。
RCU的優點在于:性能、不會死鎖,以及良好的實時延遲。當然RCU也有一點缺點,比如:讀者與更新者并發執行,低優先級RCU讀者也可以阻塞正等待優雅周期(Grace Period)結束的高優先級線程,優雅周期的延遲可能達到好幾毫秒。
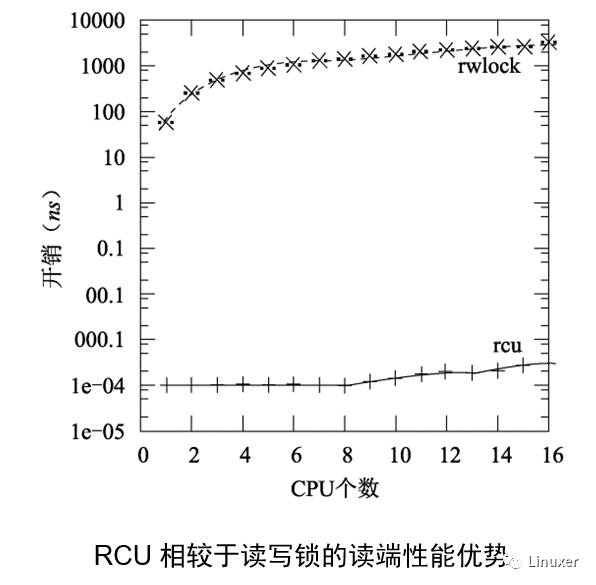
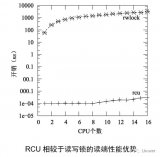
上圖是不是略顯奇怪,RCU讀端延遲竟然小于一個CPU周期?這不是開玩笑,因為有某些實現中(例如,服務器Linux),RCU讀端就完全是一個空操作。當然,在這樣的實現中,它可能會包含一個編譯屏障,因此也會對性能產生那么一點點影響。
請注意,在單個CPU上讀寫鎖比RCU慢一個數量級,在16個CPU上讀寫鎖比RCU幾乎要慢兩個數量級。隨著CPU數量的增加,RCU的擴展性優勢越來越突出。可以這么說,RCU幾乎就是水平擴展,這可以在上圖中看出來。
當內核配置了CONFIG_PREEMPT的時候,RCU仍然超過了讀寫鎖一到三個數量級,如下圖所示。請注意:讀寫鎖在CPU數目很多時的陡峭曲線。
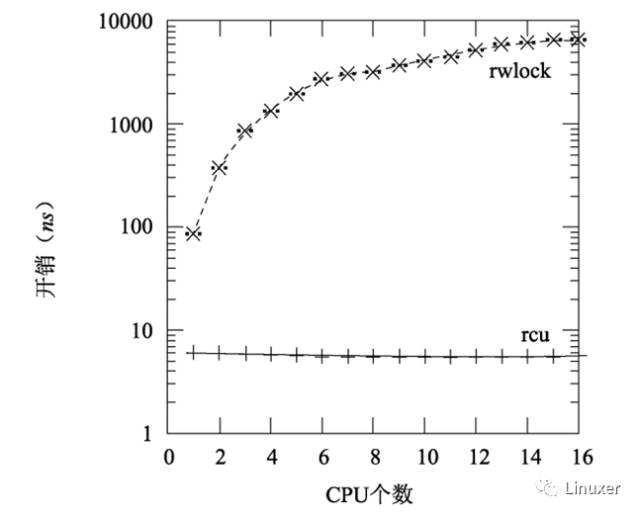
當然,上圖中的臨界區長度為0,這夸大了讀寫鎖的性能劣勢。隨著臨界區的加大,RCU的性能優勢也不再顯著。在下圖中,有16個CPU,y軸代表讀端原語的總開銷,x軸代表臨界區長度。
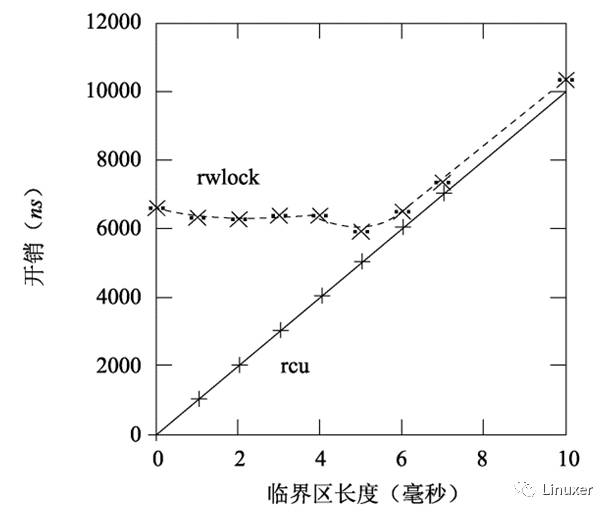
然而,一般說來,臨界區都能在幾個毫秒內完成,所以總的來說,在性能方面,測試結果對RCU是有利的。
另外,RCU讀端原語基本上是不會死鎖的。因為它本身就屬于無鎖編程的范疇。
這種免于死鎖的能力來源于RCU的讀端原語不阻塞、不自旋,甚至不存在向后跳轉語句,所以RCU讀端原語的執行時間是確定的。這使得RCU讀端原語不可能形成死鎖循環。
RCU讀端免于死鎖的能力帶來了一個有趣的后果:RCU讀者可以恣意地升級為RCU更新者。在讀寫鎖中嘗試這種升級則會有可能造成死鎖。進行RCU讀者到更新者升級的代碼片段如下所示:
1 rcu_read_lock();
2 list_for_each_entry_rcu(p, &head, list_field) {
3 do_something_with(p);
4 if (need_update(p)) {
5 spin_lock(my_lock);
6 do_update(p);
7 spin_unlock(&my_lock);
8 }
9 }
10 rcu_read_unlock();
請注意,do_update()是在鎖的保護下執行,也是在RCU讀端的保護下執行。
RCU免于死鎖的特性帶來的另一個有趣后果是RCU不會受優先級反轉問題影響。比如,低優先級的RCU讀者無法阻止高優先級的RCU更新者獲取更新端鎖。類似地,低優先級的更新者也無法阻止高優先級的RCU讀者進入RCU讀端臨界區。
另一方面,因為RCU讀端原語既不自旋也不阻塞,所以這些原語有著極佳的實時延遲。而自旋鎖或者讀寫鎖都存在不確定的實時延遲。
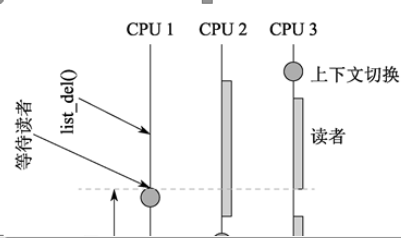
但是,RCU還是會受到更隱晦的優先級反轉問題影響,比如,在等待RCU優雅周期結束而阻塞的高優先級進程,會被-rt內核的低優先級RCU讀者阻塞。這可以用RCU優先級提升來解決。
再一方面,因為RCU讀者既不自旋也不阻塞,RCU更新者也沒有任何類似回滾或者中止的語義,所以RCU讀者和更新者可以并發執行。這意味著RCU讀者有可能訪問舊數據,還有可能發現數據不一致,無論這兩個問題中的哪一個,都讓讀寫鎖有卷土重來的機會。
不過,令人吃驚的是,在大量情景中,數據不一致和舊數據都不是問題。網絡路由表是一個經典例子。因為路由的更新可能要花相當長一段時間才能到達指定系統(幾秒甚至幾分鐘),所以系統可能會在新數據到來后的一段時間內,仍然將報文發到錯誤的地址去。通常,在幾毫秒內將報文發送到錯誤地址并不算什么問題。
簡單地說,讀寫鎖和RCU提供了不同的保證。在讀寫鎖中,任何在寫者之后開始的讀者都“保證”能看到新值。與之相反,在RCU中,在更新者完成后才開始的讀者都“保證”能看見新值,在更新者開始后才完成的讀者有可能看見新值,也有可能看見舊值,這取決于具體的時機。
在實時RCU、SRCU或QRCU中,被搶占的讀者將阻止正在進行中的優雅周期的完成,即使有高優先級的任務在等待優雅周期完成時也是如此。實時RCU可以通過用call_rcu()替換synchronize_rcu()來避免此問題,或者采用RCU優先級提升來避免。
除了那些“玩具”RCU實現,RCU優雅周期可能會延續好幾個毫秒。這使得RCU更適于使用在讀數據占多數的情景。
將讀寫鎖轉換成RCU非常簡單,如下:



1.2 RCU是一種受限制的引用計數機制
因為優雅周期不能在RCU讀端臨界區進行時結束,所以RCU讀端原語可以像受限的引用計數機制一樣使用。比如考慮下面的代碼片段:
1 rcu_read_lock(); /* acquire reference. */
2 p = rcu_dereference(head);
3 /* do something with p. */
4 rcu_read_unlock(); /* release reference. */
rcu_read_lock()原語可以看作是獲取對p的引用,因為相應的優雅周期無法在配對的rcu_read_unlock()之前結束。這種引用計數機制是受限制的,因為我們不允許在RCU讀端臨界區中阻塞,也不允許將一個任務的RCU讀端臨界區傳遞給另一個任務。
不管上述的限制,下列代碼可以安全地刪除p:
1 spin_lock(&mylock);
2 p = head;
3 rcu_assign_pointer(head, NULL);
4 spin_unlock(&mylock);
5 /* Wait for all references to be released. */
6 synchronize_rcu();
7 kfree(p);
當然,RCU也可以與傳統的引用計數結合。但是為什么不直接使用引用計數?部分原因是性能,如下圖所示,圖中顯示了在16個3GHz CPU的Intel x86系統中采集的數據。
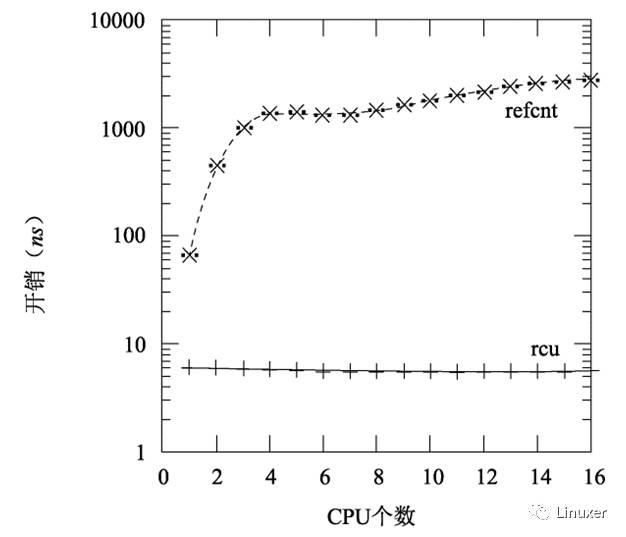
和讀寫鎖一樣,RCU的性能優勢主要來源于較短的臨界區,如下圖所示。

1.3 RCU是一種可大規模使用的引用計數機制
如前所述,傳統的引用計數通常與某種或者一組數據結構有聯系。然而,維護一組數據結構的全局引用計數,通常會導致包含引用計數的緩存行來回“乒乓”。這種緩存行“乒乓”會嚴重影響系統性能。
相反,RCU的輕量級讀端原語允許讀端極其頻繁地調用,卻只帶來微不足道的性能影響,這使得RCU可以作為一種幾乎沒有性能損失的“批量引用計數機制”。當某個任務需要在一大段代碼中持有引用時,可以使用可睡眠RCU(SRCU)。但是,一個任務不能將引用鎖引用傳遞給另一個任務。例如:在開始一次I/O時獲取引用,然后當對應的I/O完成時在中斷處理函數里釋放該引用。
1.4 RCU是窮人版的垃圾回收器
當人們剛開始學習RCU時,有種比較少見的感嘆是“RCU有點像垃圾回收器!”。這種感嘆有一部分是對的,不過還是會給學習造成誤導。
也許思考RCU與垃圾自動回收器(GC)之間關系的最好辦法是,RCU類似自動決定回收時機的GC,但是RCU與GC有幾點不同:(1)程序員必須手動指示何時可以回收指定數據結構,(2)程序員必須手動標出可以合法持有引用的RCU讀端臨界區。
盡管存在這些差異,兩者的相似程度仍然相當高,至少有一篇理論分析RCU的文獻曾經分析過兩者的相似度。
1.5 RCU是一種提供存在擔保的方法
通過鎖來提供存在擔保有其不利之處。與鎖類似,如果任何受RCU保護的數據元素在RCU讀端臨界區中被訪問,那么數據元素在RCU讀端臨界區持續期間保證存在。
1 int delete(int key)
2 {
3 struct element *p;
4 int b;
5 5
6 b = hashfunction(key);
7 rcu_read_lock();
8 p = rcu_dereference(hashtable[b]);
9 if (p == NULL || p->key != key) {
10 rcu_read_unlock();
11 return 0;
12 }
13 spin_lock(&p->lock);
14 if (hashtable[b] == p && p->key == key) {
15 rcu_read_unlock();
16 hashtable[b] = NULL;
17 spin_unlock(&p->lock);
18 synchronize_rcu();
19 kfree(p);
20 return 1;
21 }
22 spin_unlock(&p->lock);
23 rcu_read_unlock();
24 return 0;
25 }
上圖展示了基于RCU的存在擔保如何通過從哈希表刪除元素的函數來實現每數據元素鎖。第6行計算哈希函數,第7行進入RCU讀端臨界區。如果第9行發現哈希表對應的哈希項(bucket)為空,或者數據元素不是我們想要刪除的那個,那么第10行退出RCU讀端臨界區,第11行返回錯誤。
如果第9行判斷為false,第13行獲取更新端的自旋鎖,然后第14行檢查元素是否還是我們想要的。如果是,第15行退出RCU讀端臨界區,第16行從哈希表中刪除找到的元素,第17行釋放鎖,第18行等待所有之前已經存在的RCU讀端臨界區退出,第19行釋放剛被刪除的元素,最后第20行返回成功。如果14行的判斷發現元素不再是我們想要的,那么第22行釋放鎖,第23行退出RCU讀端臨界區,第24行返回錯誤以刪除該關鍵字。
1.6 RCU是一種提供類型安全內存的方法
很多無鎖算法并不需要數據元素在被RCU讀端臨界區引用時保持完全一致,只要數據元素的類型不變就可以了。換句話說,只要數據結構類型不變,無鎖算法可以允許某個數據元素在被其他對象引用時被釋放并重新分配,但是決不允許類型上的改變。這種“保證”,在學術文獻中被稱為“類型安全的內存”,它比前一節提到的存在擔保要弱一些,因此處理起來也要困難一些。類型安全的內存算法在Linux內核中的應用是slab緩存,被SLAB_DESTROY_BY_RCU標記專門標出來的緩存通過RCU將已釋放的slab返回給系統內存。在任何已有的RCU讀端臨界區持續期間,使用RCU可以保證所有帶有SLAB_DESTROY_BY_RCU標記且正在使用的slab元素仍然在該slab中,類型保持一致。
雖然基于類型安全的無鎖算法在特定情景下非常有效,但是最好還是盡量使用存在擔保。畢竟簡單總是更好的。
1.7 RCU是一種等待事物結束的方式
RCU的一個強大之處,就是允許你在等待上千個不同事物結束的同時,又不用顯式地去跟蹤其中每一個事物,因此也就無需擔心性能下降、擴展限制、復雜的死鎖場景、內存泄露等顯式跟蹤機制本身的問題。
下面展示如何實現與不可屏蔽中斷(NMI)處理函數的交互,如果用鎖來實現,這將極其困難。步驟如下:
1.做出改變,比如,OS對一個NMI做出反應。在NMI中使用RCU讀端原語。
2.等待所有已有的讀端臨界區完全退出(比如使用synchronize_sched()原語)。
3.掃尾工作,比如,返回表明改變成功完成的狀態。
下面是一個Linux內核中的例子。在這個例子中,timer_stop()函數使用synchronize_sched()確保在釋放相關資源之前,所有正在處理的NMI處理函數已經完成。
1 struct profile_buffer {
2 long size;
3 atomic_t entry[0];
4 };
5 static struct profile_buffer *buf = NULL;
6
7 void nmi_profile(unsigned long pcvalue)
8 {
9 struct profile_buffer *p =
rcu_dereference(buf);
10
11 if (p == NULL)
12 return;
13 if (pcvalue >= p->size)
14 return;
15 atomic_inc(&p->entry[pcvalue]);
16 }
17
18 void nmi_stop(void)
19 {
20 struct profile_buffer *p = buf;
21
22 if (p == NULL)
23 return;
24 rcu_assign_pointer(buf, NULL);
25 synchronize_sched();
26 kfree(p);
27 }
第1到4行定義了profile_buffer結構,包含一個大小和一個變長數組的入口。第5行定義了指向profile_buffer的指針,這里假設別處對該指針進行了初始化,指向內存的動態分配區。
第7至16行定義了nmi_profile()函數,供NMI中斷處理函數調用。該函數不會被搶占,也不會被普通的中斷處理函數打斷,但是,該函數還是會受高速緩存未命中、ECC錯誤以及被同一個核的其他硬件線程搶占時鐘周期等因素影響。第9行使用rcu_dereference()原語來獲取指向profile_buffer的本地指針,這樣做是為了確保在DECAlpha上的內存順序執行,如果當前沒有分配profile_buffer,第11行和12行退出,如果參數pcvalue超出范圍,第13和14行退出。否則,第15行增加以參數pcvalue為下標的profile_buffer項的值。請注意,profile_buffer結構中的size保證了pcvalue不會超出緩沖區的范圍,即使突然將較大的緩沖區替換成了較小的緩沖區也是如此。
第18至27行定義了nmi_stop()函數,由調用者負責互斥訪問(比如持有正確的鎖)。第20行獲取profile_buffer的指針,如果緩沖區為空,第22和23行退出。否則,第24行將profile_buffer的指針置NULL(使用rcu_assign_pointer()原語在弱順序的機器中保證內存順序訪問),第25行等待RCU Sched的優雅周期結束,尤其是等待所有不可搶占的代碼——包括NMI中斷處理函數——結束。一旦執行到第26行,我們就可以保證所有獲取到指向舊緩沖區指針的nmi_profile()實例都已經返回了。現在可以安全釋放緩沖區,這時使用kfree()原語。
簡而言之,RCU讓profile_buffer動態切換變得更簡單,你可以試試原子操作,也可以用鎖來折磨下自己。注意考慮到如下一點:在大多數CPU架構中,原子操作和鎖都可能存在循環語句,在循環的過程中可能會被NMI中斷。
二、RCU API
2.1等待完成的API族
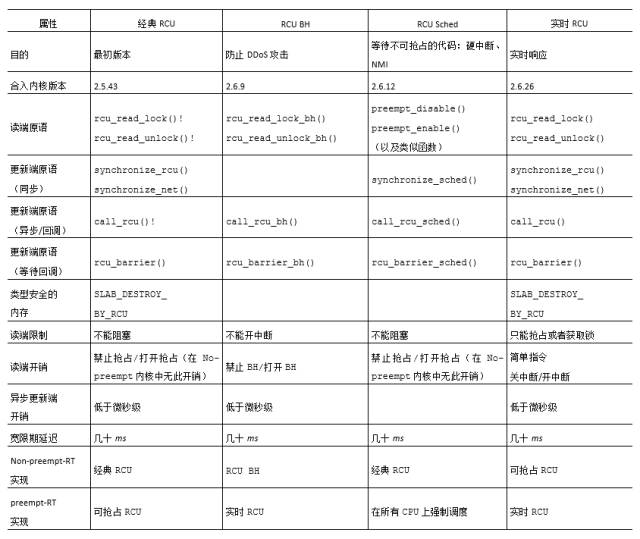
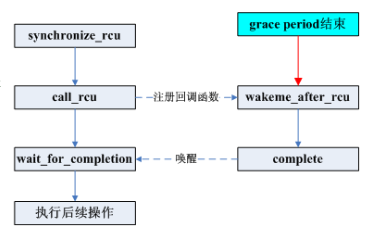
“RCU Classic”一列對應的是RCU的原始實現,rcu_read_lock()和rcu_read_unlock()原語標示出RCU讀端臨界區,可以嵌套使用。對應的同步的更新端原語synchronize_rcu()和synchronize_net()都是等待當前正在執行的RCU讀端臨界區退出。等待時間被稱為“優雅周期”。異步的更新端原語call_rcu()在后續的優雅周期結束后調用由參數指定的函數。比如,call_rcu(p, f);在優雅周期結束后執行RCU回調f(p)。
想要利用基于RCU的類型安全的內存,要將SLAB_DESTROY_BY_RCU傳遞給kmem_cache_create()。有一點很重要,SLAB_DESTROY_BY_RCU不會阻止kmem_cache_alloc()立即重新分配剛被kmem_cache_free()釋放的內存!事實上,由rcu_dereference返回的受SLAB_DESTROY_ BY_RCU標記保護的數據結構可能會釋放——重新分配任意次,甚至在rcu_read_lock()保護下也是如此。但是,SLAB_DESTROY_BY_RCU可以阻止kmem_cache_free()在RCU優雅周期結束之前,它所返回數據結構的完全釋放給SLAB。一句話,雖然數據元素可能被釋放——重新分配N次,但是它的類型是保持不變的。
2.2訂閱和版本維護API
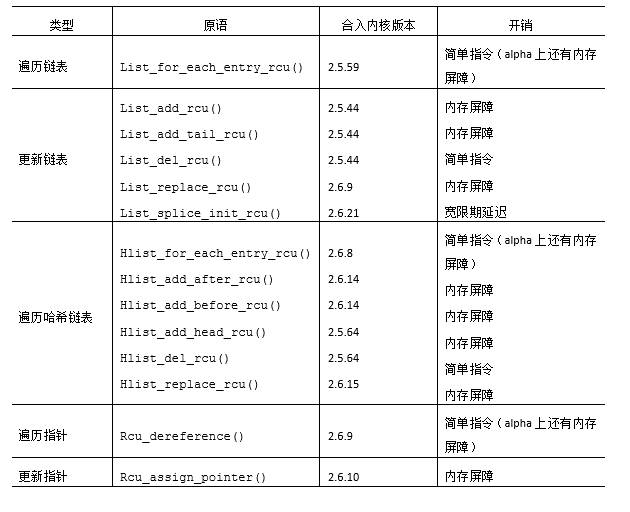
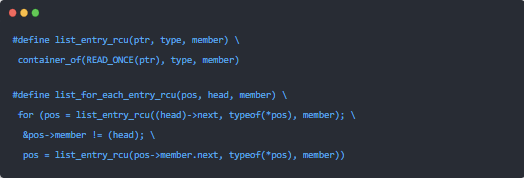
表中的第一類API作用于Linux的struct list_head循環雙鏈表。list_for_each_ entry_rcu()原語以類型安全的方式遍歷受RCU保護的鏈表。在非Alpha的平臺上,該原語相較于list_for_each_entry()原語不產生或者只帶來極低的性能懲罰。list_add_rcu()、list_add_tail_rcu()和list_replace_rcu()原語都是對非RCU版本的模擬,但是在弱順序的機器上回帶來額外的內存屏障開銷。list_del_rcu()原語同樣是非RCU版本的模擬,但是奇怪的是它要比非RCU版本快一點,這是由于list_del_rcu()只毒化prev指針,而list_del()會同時毒化prev和next指針。最后,list_splice_init_rcu()原語和它的非RCU版本類似,但是會帶來一個完整的優雅周期的延遲。
表中的第二類API直接作用于Linux的struct hlist_head線性哈希表。struct hlist_head比structlist_head高級一點的地方是前者只需要一個單指針的鏈表頭部,這在大型哈希表中將節省大量內存。表中的struct hlist_head原語與非RCU版本的關系同struct list_head原語的類似關系一樣。
表中的最后一類API直接作用于指針,這對創建受RCU保護的非鏈表數據元素非常有用,比如受RCU保護的數組和樹。rcu_assign_pointer()原語確保在弱序機器上,任何在給指針賦值之前進行的初始化都將按照順序執行。同樣,rcu_dereferece()原語確保后續指針解引用的代碼可以在Alpha CPU上看見對應的rcu_assign_pointer()之前進行的初始化的結果。
-
cpu
+關注
關注
68文章
10855瀏覽量
211595 -
Linux
+關注
關注
87文章
11295瀏覽量
209345 -
rcu
+關注
關注
0文章
21瀏覽量
5446
原文標題:謝寶友:深入理解RCU之四:用法
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
謝寶友教你學Linux:深入理解Linux RCU之從硬件說起
從硬件引申出內存屏障,帶你深入了解Linux內核RCU
深入理解Linux RCU:經典RCU實現概要
基于Linux內核源碼的RCU實現方案
Linux內核RCU鎖的原理與使用
深入理解RCU:玩具式實現
分級RCU的基礎知識
Linux內核中RCU的用法
linux內核rcu機制詳解
深入了解RCU是怎樣實現的?





 工商網監
工商網監
評論