


今天的介紹ServiceComb的通信處理詳解。
整體介紹
ServiceComb的底層通信框架依賴Vert.x. vertx標準工作模式為高性能的Reactive模式,其工作方式如下圖所示:
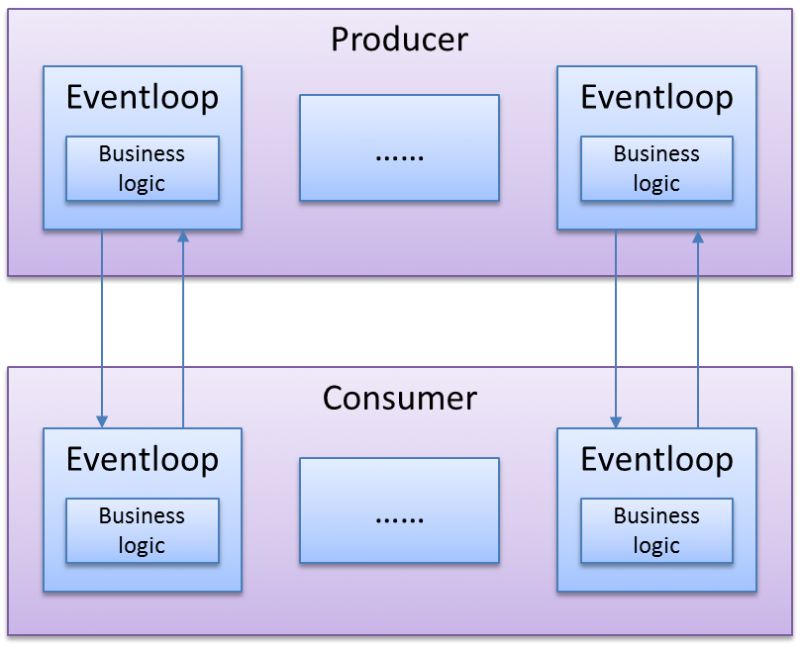
圖 Reactive模式工作方式
業務邏輯直接在Eventloop中執行,整個業務流程中沒有線程切換,所有的等待邏輯都是異步的,只要有任務,則不會讓線程停下來,充分、有效地利用系統資源。
vertx生態中包含了業界常用各種組件的Reactive封裝,包括jdbc、zookeeper、各種mq等等。但是Reactive模式對業務的要求相當高,業務主流程中不允許有任何的阻塞行為。因此,為了簡化上層業務邏輯,方便開發人員的使用,在Vertx之上提供同步模式的開發接口還是必不可少的,例如:
各種安全加固的組件,只提供了同步工作模式,比如redis、zookeeper等等;
一些存量代碼工作于同步模式,需要低成本遷移;
開發人員技能不足以控制Reactive邏輯。
所以ServiceComb底層基于vertx,但在vertx之上進行了進一步封裝,同時支持Reactive及同步模式。
工作于Reactive模式時,利用Vertx原生的能力,不必做什么額外的優化,僅需要注意不要在業務代碼中阻塞整個進程。
而同步模式則會遭遇各種并發性能問題。,本文描述同步模式下的各種問題以及解決方案。
RESTful流程中,連接由vertx管理,當前沒有特別的優化,所以本文中,連接都是指highway流程中的tcp連接。
同步模式下的整體線程模型
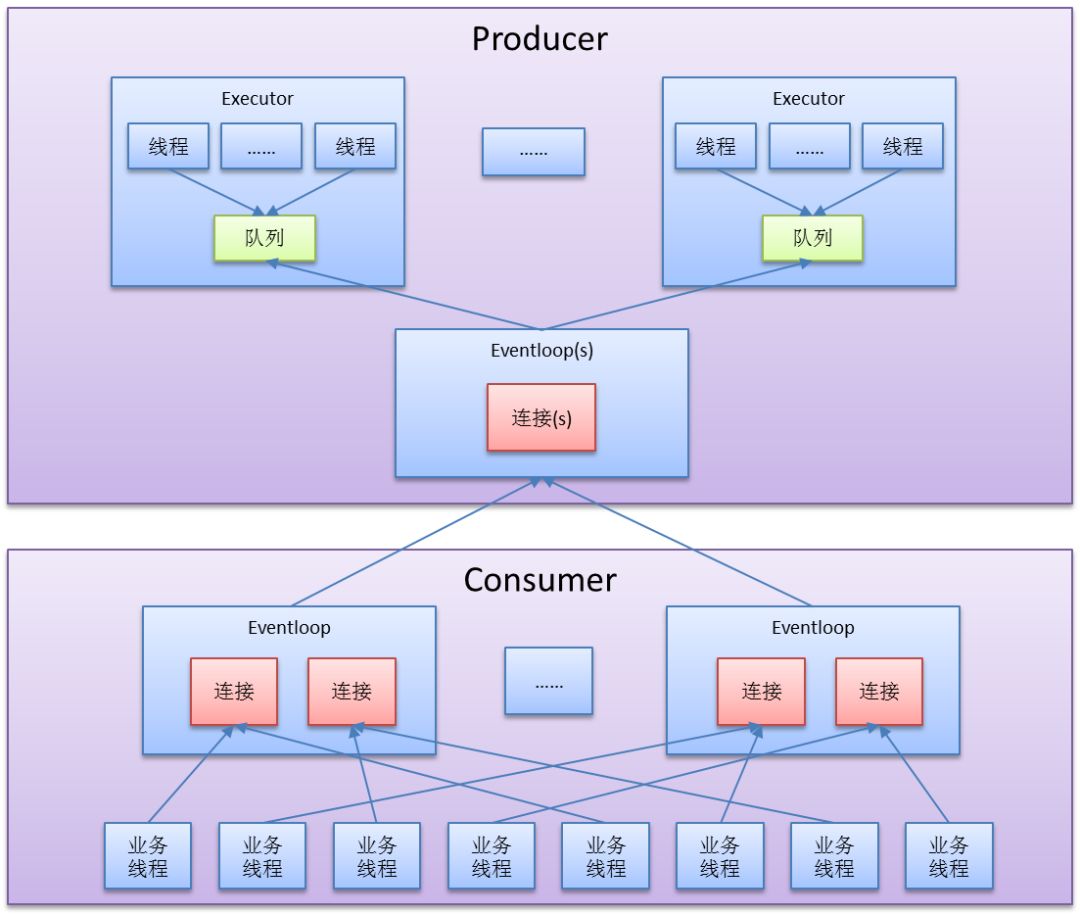
圖 同步模式下的整體線程模型
一個微服務進程中,為transport創建了一個獨立的vertx實例;
Eventloop是vertx中的網絡、任務線程;
一個vertx實例默認的Eventloop數為:
2 * Runtime.getRuntime().availableProcessors()
服務消費者端
在服務消費者端,主要需要處理的問題是如何更加高效地把請求推送到服務提供者上去,然后拿到服務提供者的返回信息。所以在這一端我們主要關注“如何更高效的發送數據”這個話題。
單連接模型
1、最簡單的單連接模型
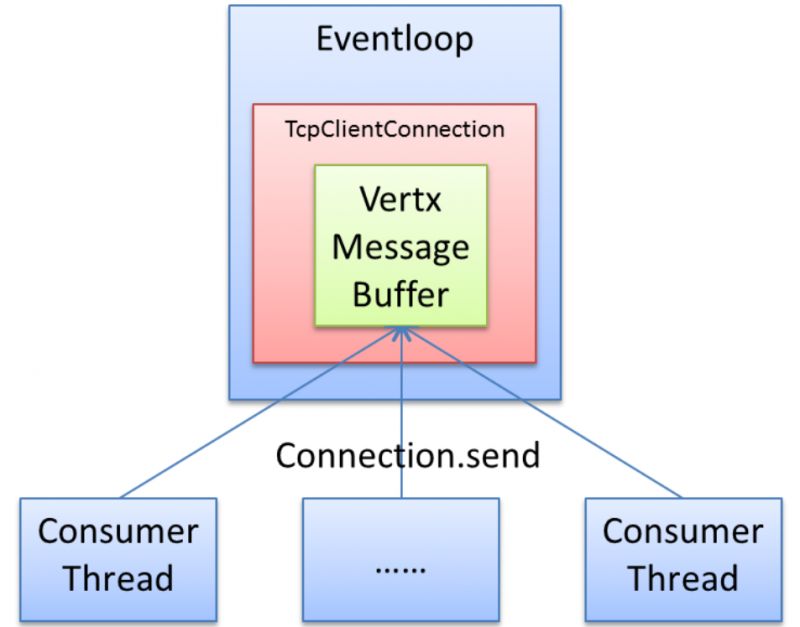
圖 最簡單的單連接模型
從模型圖中,我們可以看到,所有的consumer線程,如果向同一個目標發送數據,必然產生資源競爭,此時實際的處理如下:
Connection.send內部直接調用Vertx的socket.write(buf),是必然加鎖互斥的。
這必然導致大量并發時,大多數consumer線程都無法及時地發送自己的數據。
Socket.write內部會調用netty的channel.write,此時會判斷出執行線程不是Eventloop線程,所以會創建出一個任務并加入到Eventloop任務隊列中,如果Eventloop線程當前在睡眠態,則立即喚醒Eventloop線程,異步執行任務。
這導致頻繁的任務下發及線程喚醒,無謂地增加cpu占用,降低性能。
2、優化的單連接模型
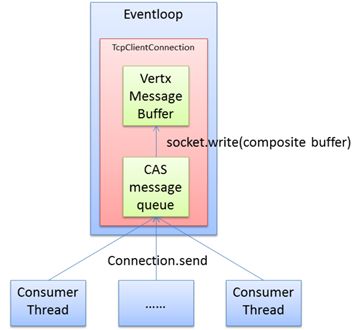
圖 優化的單連接模型
在優化模型中:
每個TcpClientConnection額外配備一個CAS消息隊列;
Connection.send不再直接調用vertx的write方法,而是:
所有消息保存到CAS隊列中,減少入隊競爭;
通過原子變量判定,只有入隊前CAS隊列為空,才向Eventloop下發write任務,喚醒Eventloop線程;
在Eventloop中處理write任務時,將多個請求數據包裝為composite buffer,批量發送,減少進入os內核的次數,提高tcp發送效率。
代碼參見:
https://github.com/ServiceComb/ServiceComb-Java-Chassis/blob/master/foundations/foundation-vertx/src/main/java/io/servicecomb/foundation/vertx/client/tcp/TcpClientConnection.java
io.servicecomb.foundation.vertx.client.tcp.TcpClientConnection.packageQueueio.servicecomb.foundation.vertx.client.tcp.TcpClientConnection.send(AbstractTcpClientPackage, long, TcpResponseCallback)
https://github.com/ServiceComb/ServiceComb-Java-Chassis/blob/master/foundations/foundation-vertx/src/main/java/io/servicecomb/foundation/vertx/tcp/TcpConnection.java
io.servicecomb.foundation.vertx.tcp.TcpConnection.write(ByteBuf)
io.servicecomb.foundation.vertx.tcp.TcpConnection.writeInContext()
進行此項優化后,在同一環境下測試2組數據,可以看到性能有明顯提升(不同硬件的測試環境,數據可能差異巨大,不具備比較意義):
| TPS | Latency(ms) | CPU | TPS提升比例 | 時延提升比例 | ||
| Consumer | Producer | (新-舊)/舊 | (舊-新)/新 | |||
| 優化前 | 81986 | 1.22 | 290% | 290% | 77.31% | 43.61% |
| 優化后 | 145369 | 0.688 | 270% | 270% |
表:單連接模型優化前后性能對比
多連接模型
在單連接場景下進行相應的優化后,我們發現其實還有更多的優化空間。因為在大多數場景中,實際機器配置足夠高,比如多核、萬兆網絡連接、網卡支持RSS特性等。此時,需要允許一對consumer與producer之間建立多條連接來充分發揮硬件的性能。
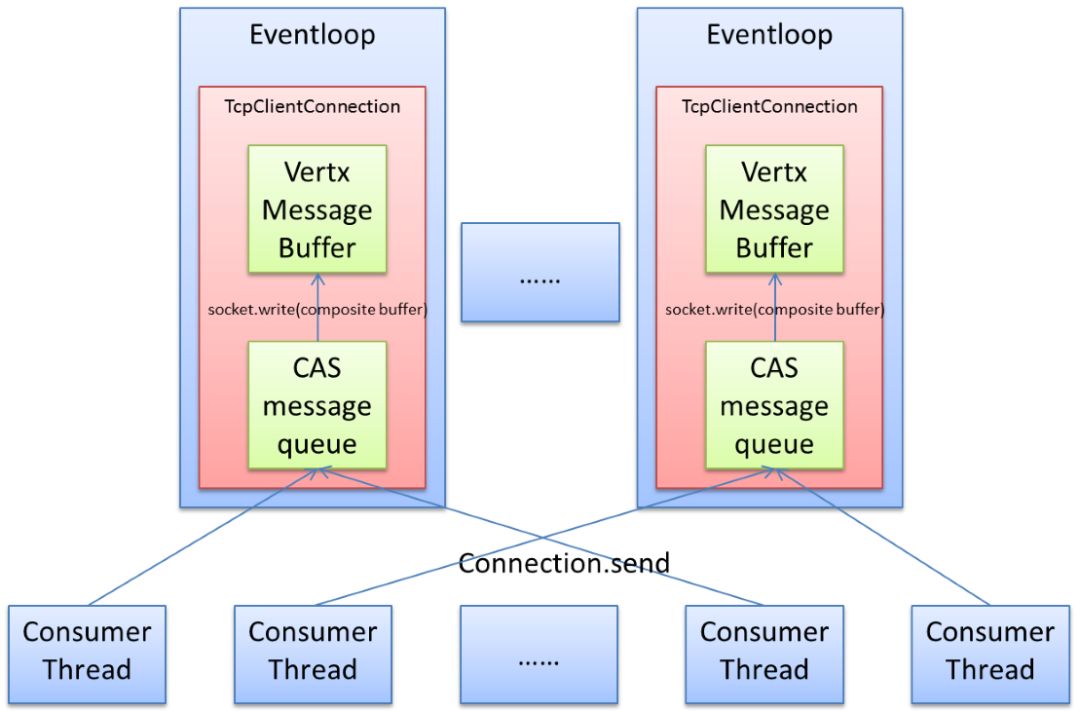
圖 多連接模型
允許配置多個Eventloop線程
在microservice.yaml中進行以下配置:
cse:
highway:
client:
thread-count: 線程數
server:
thread-count: 線程數
Consumer線程與Eventloop線程建立均衡的綁定關系,進一步降低consumer線程的競爭概率。
代碼參見:
https://github.com/ServiceComb/ServiceComb-Java-Chassis/blob/master/foundations/foundation-vertx/src/main/java/io/servicecomb/foundation/vertx/client/ClientPoolManager.java
io.servicecomb.foundation.vertx.client.ClientPoolManager.findThreadBindClientPool()
優化后的性能對比:
| TPS |
Latency (ms) |
CPU | TPS提升比例 | 時延提升比例 | ||
| Consumer | Producer | (新-舊)/舊 | (舊-新)/新 | |||
| 簡單單連接*10 | 543442 | 0.919 | 2305% | 1766% | 72.81% | 42.11% |
| CAS單連接*10 | 939117 | 0.532 | 1960% | 1758% |
表 多連接下線程模型優化前后性能對比
每請求大小為1KB,可以看到萬兆網的帶寬接近吃滿了,可以充分利用硬件性能。
(該測試環境,網卡支持RSS特性。)
服務提供者端
不同于服務消費者,服務提供者主要的工作模式就是等待消費者的請求,然后處理后返回應答的信息。所以在這一端,我們更加關注“如何高效的接收和處理數據”這件事情。
同步模式下,業務邏輯和IO邏輯分開,且根據“隔離倉”原則,為了保證整個系統更加穩定和高效地運行,業務邏輯本身也需要在不同隔離的區域內運行。而這些區域,就是線程池。所以構建服務提供者,就需要對線程池進行精細的管理。
下面是針對線程池的各種管理方式。
1、單線程池(ThreadPoolExecutor)
下圖表示的是將業務邏輯用單獨的線程池實現的方式。在這種方式下,IO仍然采用異步模式,所有接到的請求放入隊列中等待處理。在同一個線程池內的線程消費這個隊列并進行業務處理。
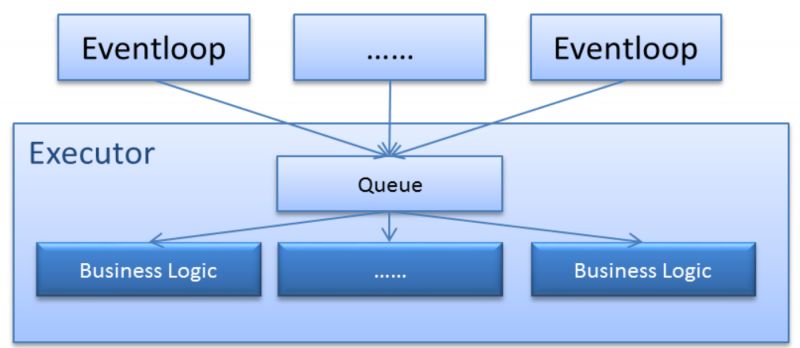
圖 單線程池實現方式
在這種方式下,有以下瓶頸點:
所有的Eventloop向同一個Blocking Queue中提交任務;
線程池中所有線程從同一個Blocking Queue中搶任務執行;
ServiceComb默認不使用這種線程池。
2、多線程池(ThreadPoolExecutor)
為規避線程池中Queue帶來的瓶頸點,我們可以使用一個Executor將多個真正的Executor包起來。
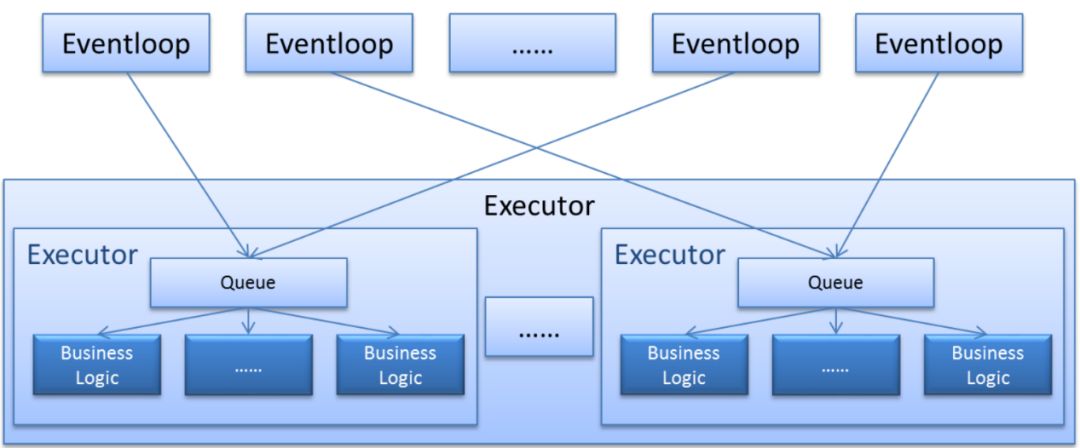
圖 多線程池實現方式
Eventloop線程與線程池建立均衡的綁定關系,降低鎖沖突概率;
相當于將線程分組,不同線程從不同Queue中搶任務,降低沖突概率。
ServiceComb默認所有請求使用同一個線程池實例:
io.servicecomb.core.executor.FixedThreadExecutor
FixedThreadExecutor內部默認創建2個真正的線程池,每個池中有CPU數目的線程,可以通過配置修改默認值:
servicecomb:
executor:
default:
group: 內部真正線程池的數目
thread-per-group: 每個線程池中的線程數
代碼參見:
https://github.com/ServiceComb/ServiceComb-Java-Chassis/blob/master/core/src/main/java/io/servicecomb/core/executor/FixedThreadExecutor.java
3、隔離倉
業務接口的處理速度有快有慢,如果所有的請求統一在同一個Executor中進行處理,則可能每個線程都在處理慢速請求,導致其他請求在Queue中排隊。
此時,可以根據業務特征,事先做好規劃,將不同的業務處理按照一定的方式進行分組,每個組用不同的線程池,以達到隔離的目的。
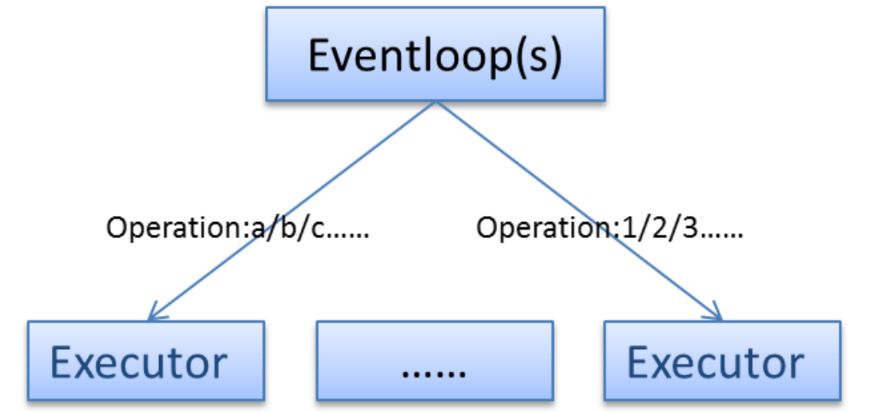
圖 隔離倉
隔離倉的實現依托到ServiceComb靈活的線程池策略,具體在下一節進行描述。
4、靈活的線程池策略
ServiceComb微服務的概念模型如下:
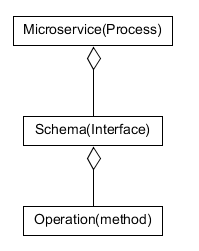
圖 ServiceComb微服務概念模型
可以針對這3個層次進行線程池的配置,operation與線程池之間的對應關系,在啟動階段既完成綁定。
operation與線程池之間的綁定按以下邏輯進行:
查看配置項cse.executors.Provider.[schemaId].[operationId]是否有值;
如果有值,則將值作為beanId從spring中獲取bean實例,該實例即是一個Executor。
如果沒有值,則繼續嘗試下一步:
使用相同的方式,查看配置項cse.executors.Provider.[schemaId]是否有值;
使用相同的方式,查看配置項cse.executors.default是否有值;
以”cse.executor.groupThreadPool”作為beanId,獲取線程池(系統內置的FixedThreadExecutor)。
代碼參見:
https://github.com/ServiceComb/ServiceComb-Java-Chassis/blob/master/core/src/main/java/io/servicecomb/core/executor/ExecutorManager.java
按以上策略,用戶如果需要創建自定義的線程池,需要按以下步驟執行:
實現java.util.concurrent.Executor接口
將實現類定義為一個bean;
在microservice.yaml中將線程池與對應的業務進行綁定。
5、線程池模型總結
如上一節所述,在默認多線程池的基礎上,CSE提供了更為靈活的線程池配置。“隔離倉”模式的核心價值是實現不同業務之間的相互隔離,從而讓一個業務的故障不要影響其他業務。這一點在CSE中可以通過對線程池的配置實現。例如,可以為不同的operation配置各自獨立的線程池。
另外,靈活性也帶來了一定的危險性。要避免將線程池配置為前面提到的“單業務線程池”模式,從而為整個系統引入瓶頸點。
寫在最后:ServiceComb除了在華為云微服務引擎商用之外,也于2017年12月全票通過進入Apache孵化器。歡迎感興趣的讀者前往開源社區和我們討論切磋,希望此文可以給正在進行微服務方案實施的讀者們一些啟發。
-
華為
+關注
關注
216文章
35231瀏覽量
256136 -
無線通信
+關注
關注
58文章
4759瀏覽量
145268 -
TCP
+關注
關注
8文章
1403瀏覽量
81169
原文標題:微服務|打造企業級微服務開發框架(下)
文章出處:【微信號:Huawei_Developer,微信公眾號:華為開發者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
飛思卡爾QorIQ通信處理器內部架構詳解

什么是飛思卡爾運籌帷幄細化QorIQ通信處理器?
飛思卡爾LS1系列通信處理器迎來了哪些機遇?
蘇州求購CP443-1通信處理器卡件/回收西門子通信處理器
QorIQ通信處理器飛思卡爾
LSI推出的最新Axxia通信處理器
LSI推出Axxia 系列通信處理器
LSI推出無需外部存儲器的多核通信處理器-APP3100
LSI推出無需外部存儲器的多核通信處理器APP3100
Marvell發布業界首款單芯片“全球制式”通信處理器
新通信處理器的新能如何
QorIQ通信處理器的詳細介紹






 工商網監
工商網監

評論