 用深度學習分析電子病歷 進行臨床預測
用深度學習分析電子病歷 進行臨床預測
如今利用機器學習預測事態發展已經非常普遍。我們可以用它預測通勤途中的交通狀況,以及將英文翻譯成西班牙語時需要用到的詞匯。那么,我們是否可以用相同類型的機器學習進行臨床預測呢?我們認為,要做到實用,預測模型必須具備以下兩點特征:
可擴展:該預測模型要能進行多項預測,得出所有我們想要的信息,并且適用于不同醫院的系統。鑒于醫療保健數據十分復雜,需要進行大量數據處理,這一要求并不容易滿足。
精度高:預測結果需能幫助醫生關注真正的問題所在,而不是用誤報警分散醫生的注意力。隨著電子病歷逐漸普及,我們正嘗試用其中的數據建立更加精準的預測模型。
我們聯合加州大學舊金山分校、斯坦福大學醫學院和芝加哥大學醫學院的同事,在《自然》雜志的兄弟期刊——《數字醫學》上發表了題為《可擴展且精準的深度學習與電子健康記錄》的論文。這篇論文對實現前文所述的兩個目標有所幫助。
基于脫敏的電子病歷數據,我們用深度學習模型對住院患者進行了廣泛預測。值得一提的是,該模型可以直接使用原始數據,無需人工對相關變量進行提取、清洗、整理、轉換等一系列費時費力的操作。合作伙伴在將電子病歷數據交給我們之前,先對其進行了脫敏處理。我們也采用了最先進的措施保障數據安全,包括邏輯分隔、嚴格的訪問控制,以及靜態和傳輸中的數據加密。
可擴展性
電子病歷非常復雜。以體溫為例,因測量位置不同(舌頭下方、耳膜或額頭),其往往具有不同含義。而體溫不過是電子病歷眾多參數中最簡單的之一。此外,各個衛生系統都有一套自己定制的電子病例系統,導致各個醫院的采集的數據大不相同。用機器學習處理這些數據之前,需要先將其統一格式。基于開放的FHIR標準,我們構建了一套標準格式。
格式統一后,我們就不需要手動選擇或調整相關變量了。進行各項預測時,深度學習模型會自動掃描過去到現在的所有數據點,并分析其中哪些數據對預測是有價值的。由于這一過程涉及數千個數據點,我們不得不開發了一些基于遞歸神經網絡(RNN)和前饋網絡的新型深度學習建模方法。
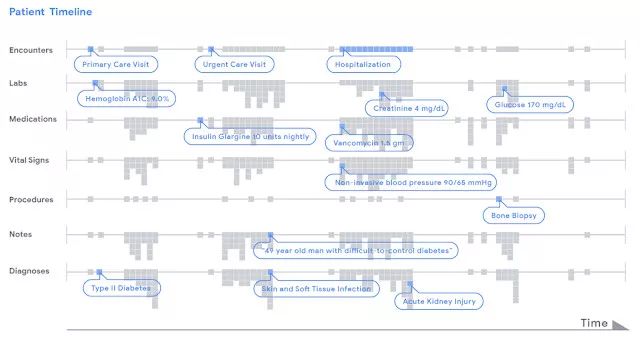
*我們用時間線來展示患者電子病歷中的數據。為方便說明,我們按行顯示各種類型的臨床數據,其中每個數據片段都用灰點表示,它們被存儲在FHIR中。FHIR是一種可供任何醫療機構使用的開放式數據標準。深度學習模型通過從左往右掃描時間表,分析患者從圖標開頭到現在的住院信息,并據此進行不同類型的預測。
就這樣我們設計了一個計算機系統,以可擴展的方式進行預測,而無需為每項預測任務手動制作新的數據集。設置數據只是全部工作中的一部分,保證預測的準確性也十分重要。
準確性
評估準確性的最常見方法是受試者工作曲線下面積,它可以有效評估模型區分特定未來結果患者和非特定未來結果患者的效果。 在這個度量標準中,1.00代表完美,0.50代表不比隨機結果更準確,也就是說得分越高代表模型越準確。通過測試,我們的模型在預測患者是否會在醫院停留很久時,得分為0.86(傳統邏輯回歸模型的評分為0.76);預測住院病死率時的得分為0.95(傳統模型的得分為0.86);預測出院后意外再住院率時得分為0.77(傳統模型得分為0.70)。從得分上看,新方法的準確率提升非常顯著。
我們還用這些模型來確定患者接受的治療,比如醫生為發燒、咳嗽的患者開具頭孢曲松和強力霉素,該模型就會判定患者正在接受肺炎治療。必須強調,該模型并不會給患者做診斷,它只是收集患者的相關信號,以及臨床醫生編寫的治療方案和筆記。因此,它更像是一位優秀的聽眾而不是主診醫生。
深度學習模型的可解釋性是我們工作重點之一。每項預測的“注意圖”會展示模型在進行該項預測時認為重要的那些數據點。我將展示一個例子作為概念驗證,并將其視為讓預測對臨床醫生產生價值的重要部分。
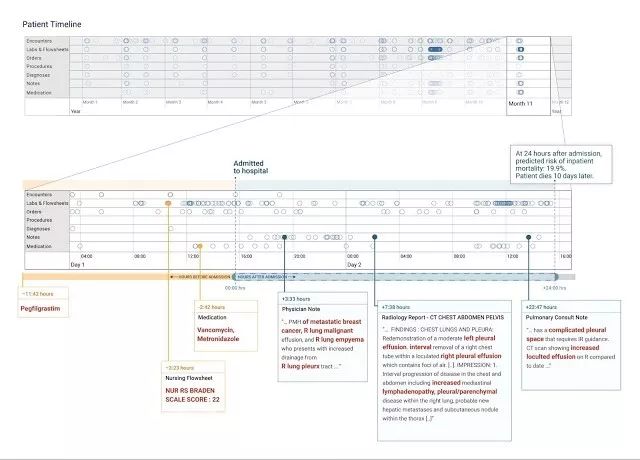
*患者入院24小時后,我們使用深度學習進行預測。上圖頂部的時間表包含了患者幾個月時間的歷史數據,我們將最近的數據做了放大顯示。模型用紅色標識了患者信息圖表中用于“解釋”其預測的信息。在這個研究案例中,模型標注了臨床上有意義的信息片段。
這對患者和臨床醫生意味著什么?
這項研究成果還處于早期階段,而且是基于回顧性數據得出的。事實上,證明機器學習可用于改善醫療保健這一假設還有做很多工作要做,本文不過是個開始。醫生們正窮于應付各種警報和需求,機器學習模型是否能幫助處理繁瑣的管理任務,讓他們更專注于護理有需要的患者?我們是否可以幫助患者獲得高質量的護理,無論他們在哪里尋求治療?我們期待著與醫生和患者合作,找出這些問題的答案。
-
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:GGAI 前沿 | Google醫療AI新成果:用深度學習分析電子病歷 預測患者病情發展
文章出處:【微信號:ggservicerobot,微信公眾號:高工智能未來】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用

FPGA加速深度學習模型的案例
AI大模型與深度學習的關系
FPGA做深度學習能走多遠?
電磁軌跡預測分析系統設計方案
利用Matlab函數實現深度學習算法
深度學習中的時間序列分類方法
深度學習中的無監督學習方法綜述
深度學習常用的Python庫
深度學習模型訓練過程詳解
深度學習與傳統機器學習的對比
電磁軌跡預測分析系統
【技術科普】主流的深度學習模型有哪些?AI開發工程師必備!






 工商網監
工商網監
評論