 將從目標和問題的角度去討論每種誤差度量的有效性
將從目標和問題的角度去討論每種誤差度量的有效性
模型的好壞和優劣都是基于一定的角度做出的相對判斷,在這篇文章中,我們將從目標和問題的角度去討論每種誤差度量的有效性。 當有人告訴你“中國是最好的國家”時,你問的首要問題肯定是這個陳述的基礎是什么,我們是根據國家的經濟狀況、文化水平還是他們的衛生設施等來評估比較各個國家的呢? 類似地,每個機器學習模型都用到了不同的數據集來有針對性的解決不同目標的問題,因此,在選擇合適的度量之前,要深刻理解上下文。
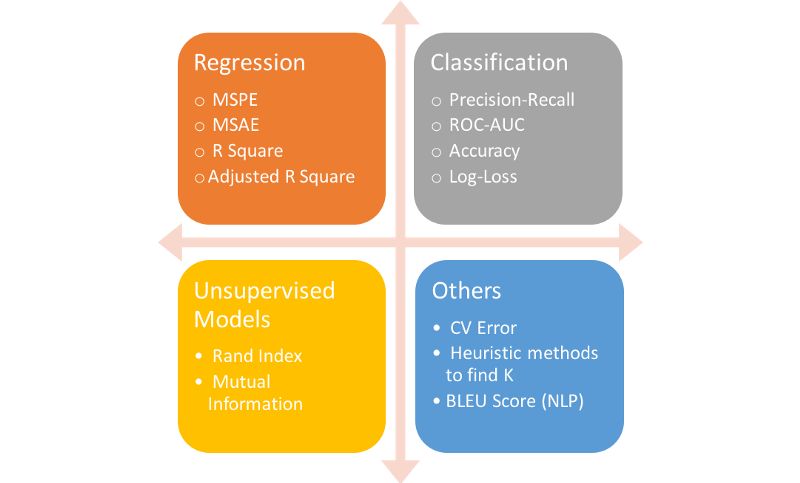
圖 各種機器學習模型常用的度量標準
回歸度量指標
大多數的博客更多都關注模型的精度、召回率、AUC(Area under curve,ROC曲線下區域面積)等分類指標。這里想稍稍改變一下,讓我們來探索各種更多的指標,包括在回歸問題中使用的指標。MAE和RMSE是關于連續變量的兩個最普遍的度量標準。
首先,我們看看最流行RMSE,全稱是Root Mean SquareError,即均方根誤差,它表示預測值和觀測值之間差異(稱為殘差)的樣本標準偏差。在數學上,它是用如下這個公式計算的:
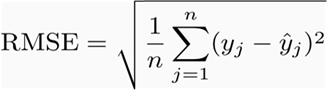
其次是MAE,全稱是Mean Absolute Error,即平均絕對誤差,它表示預測值和觀測值之間絕對誤差的平均值。MAE是一種線性分數,所有個體差異在平均值上的權重都相等,比如,10和0之間的絕對誤差是5和0之間絕對誤差的兩倍。但這對于RMSE而言不一樣,后續將進一步詳細討論。在數學上,MAE是用如下這個公式計算的:
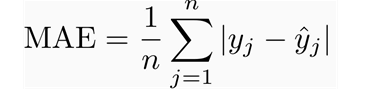
那么你應該選擇哪一個?為什么這樣選擇呢?
首先,理解和解釋MAE很容易,因為它就是對殘差直接計算平均,而RMSE相比MAE,會對高的差異懲罰更多。讓我們通過兩個例子來理解一下:
案例1:真實值= [2,4,6,8],預測值= [4,6,8,10]
案例2:真實值= [2,4,6,8],預測值= [4,6,8,12]
案例1的MAE = 2.0,RMSE = 2.0
案例2的MAE = 2.5,RMSE = 2.65
從上述例子中,我們可以發現RMSE比MAE更加多地懲罰了最后一項預測值。通常,RMSE要大于或等于MAE。等于MAE的唯一情況是所有殘差都*相等或都為零*,如案例1中所有的預測值與真實值之間的殘差皆為2,那么MAE和RMSE值就相等。
> 盡管RMSE更復雜且偏向更高的誤差,它仍然是許多模型的默認度量標準,因為用RMSE來定義損失函數是*平滑可微*的,且更容易進行數學運算。
雖然這聽起來不太令人滿意,但這的確是是它非常受歡迎的原因。下面我將從數學角度解釋上述邏輯。首先,讓我們建立一個簡單的單變量線性模型:y = mx + b,在這個問題中,我們要找到最佳“m”和“b”,數據(x,y)是已知的。如果我們用RMSE來定義損失函數(J):那么我們可以很容易地求得J對m和b的偏導,并以此來更新m和b(這是梯度下降的工作方式,這里就不過多解釋它)
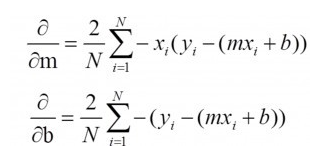
上述等式很容易就可以求解,但對MAE并不適用。然而,如果你需要一種度量標準能從直觀解釋的角度來比較兩個模型,那么我認為MAE會是更好的選擇。值得注意的是,RMSE和MAE的單位與y值相同,但R Square不是這樣的。此外,RMSE和MAE的范圍都是從0到無窮大。
>這里需要提及MAE和RMSE之間的一大重要區別,最小化一組數字的平方誤差會得到其平均值,而最小化絕對誤差則會得到其中值, 這也是為什么MAE比RMSE對離群點更有效的原因。
R Squared, R2 校正 RSquared
R2 和校正R2,常常用于說明選擇的自變量對解釋因變量解釋擬合有多好。
在數學上,R_Squared由下式給出:
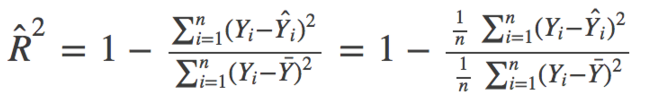
>其中,分子是MSE(殘差平方的平均值),分母是Y值的方差。MSE越高,R_squared則越小,表明模型越差。
跟R2一樣,校正R2也顯示了自變量對因變量的解釋程度,回歸問題中體現于曲線的擬合優度,但是可以根據模型中的自變量個數進行調整。 它由以下公式給出:
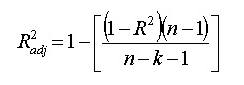
其中n表示觀測值的總數,k表示預測值的數量,校正后的R2總是小于或等于R2。
為什么你應該越過R2選擇校正R2?
標準的R2在使用中往往會存在一些問題,但使用校正R2就能很好地解決。因為校正R2會考慮在模型中增加附加項,使得性能改善。如果你添加有用的項,R2會增加,而如果添加了不太有用的預測變量,R2將減少。 但是,即使模型沒有實際改進,R2也隨著變量數量的增加而增加。下面我們用一個例子來更好地理解這一點。

這里,案例1是一個很簡單的情況,我們有5個觀察值(x,y)。 在案例2中,讓一個變量是變量1的兩倍(也就是說它與變量1完全相關)。在案例3中,我們對變量2做了輕微的干擾,使其不再與變量1完全相關。
因此,如果我們為每個案例都用簡單普通的最小二乘(OLS)模型來擬合,那么從邏輯上講,我們為案例1、案例2和案例3提供的信息是相同的,那我們的度量值相對這些模型也不會有所提高。然而,實際上R2 對于模型2和3會給出更高的值,這顯然是不正確的。但是,用校正R2就可以解決這個問題,實際上對于案例2和3都是減少的。讓我們給這些變量(x ,y)賦上一些值,并查看Python中獲得的結果。
注意:模型1和模型2的預測值將相同,因此R2也將相同,因為它僅取決于預測值和實際值。

從上表可以看出,從案例1到案例3,盡管我們沒有增加的任何附加信息,但R2仍在增加,而校正后的R2顯示了正確的趨勢(懲罰模型2擁有更多的變量)
對比校正R2與RMSE
對于前面的例子,我們將看到案例1和案例2得到的RMSE結果與R2是類似的。在這種情況下,校正R2要比RMSE更好,因為它只對預測值與實際值進行比較。而且,RMSE的絕對值實際上并不能說明模型有多糟糕,它只能用于比較兩個模型,但校正R2就很容易做到這一點。 例如,如果一個模型的現在R2為0.05,那么這個模型肯定很差。
但是,如果你只關心預測精度,那么RMSE是最佳選擇。它計算簡單,容易區分,一般是大多數模型的默認度量。
常見誤區:我經常看到網上說R2的范圍在0到1之間,實際上并不是這樣。R2的最大值是1,但最小值可以是負無窮大。即使y的真實值為正數,模型對所有觀測值的預測結果也會有高負值的情況。在這種情況下,R2將小于0。這雖然是一個不太可能的情況,但可能性依然存在。
有趣的指標
這里有一個有趣的指標,如果你對NLP感興趣,Andrew Ng在深度學習課程中介紹了它。BLEU(Bilingual Evaluation Understudy,雙語評估研究)
它主要用于衡量機器翻譯相對于人類翻譯的質量,它使用了精確度量的修改形式。
計算BLEU分數的步驟:
1. 把句子轉換成單個詞、兩個詞、三個詞和四個詞
2. 分別計算大小為1至4的n語法的精度
3. 取所有這些精度值的加權平均的指數
4.將其與簡短的懲罰項相乘(稍后將解釋)
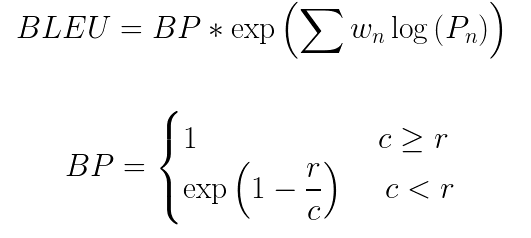
這里BP是簡短的懲罰項,r和c分別是參考翻譯和候選翻譯中的詞的數量,w 表示權重,P表示精度值
例:
參考:The cat is sitting on the mat
機器翻譯1:On the mat is a cat
機器翻譯2:There is cat sitting cat
我們來比較一下上面兩個翻譯的BLEU得分。
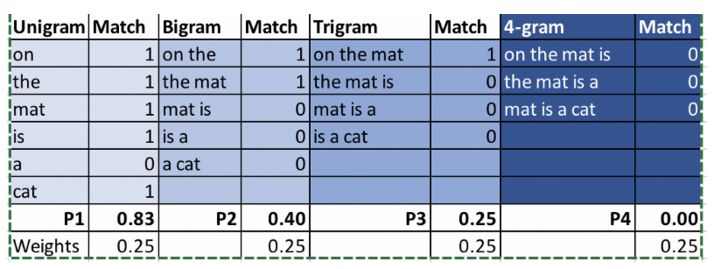
最終結果:BLEU(MT1)= 0.454,BLEU(MT2)= 0.59
為什么要引入簡潔的懲罰項?
引入的懲罰項會懲罰那些短于參考翻譯的候選翻譯。例如,如果上述候選翻譯的參考翻譯是“The cat”,那么它對于單個詞和兩個詞將具有很高的精度,因為兩個單詞都以相同的順序出現在參考翻譯中。但是,長度太短的話,實際上并不能很好的反映參考翻譯的含義。有了這個簡短的懲罰,候選翻譯必須在長度、相同單詞和單詞順序方面與參考翻譯相匹配才能獲得高分。
希望通過這篇文章的介紹,我們能理解不同度量間的差異,并能為機器學習選擇合適的模型度量,評價建模效果的好壞,并指導模型的優化。
-
機器學習
+關注
關注
66文章
8408瀏覽量
132572 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14880 -
度量
+關注
關注
0文章
8瀏覽量
2669
原文標題:確認過眼神,如何為模型選擇合適的度量標準?
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
CS的有效性可以改編?
ATPG有效性是什么意思
高階微擾法的有效性研究

如何檢查Oracle數據庫備份文件是否有效?備份文件有效性檢測系統設計資料概述
什么是欺詐證明和有效性證明
PLC冗余系統的可行性和有效性分析
基于內法向量與二次誤差度量的孔洞修補算法

Oracle數據庫備份文件有效性檢測設計方案






 工商網監
工商網監
評論