 TCN應該成為我們未來項目的優先選項
TCN應該成為我們未來項目的優先選項
我們一開始認為,時序問題(如語言、語音等等)天生就是 RNN 的地盤。然而現在這一觀點要成為過去式了。時間卷積網絡(Temporal Convolutional Nets, TCNs)作為 CNN 家族中的一員健將,擁有許多新特性,如今已經在諸多主要應用領域中擊敗了 RNN。看起來 RNN 可能要成為歷史了。
也就是從 2014、15 年起,我們基于深度神經網絡的應用就已經在文本和語音識別領域達到 95% 的準確率,可以用來開發新一代的聊天機器人、個人助理和即時翻譯系統等。
卷積神經網絡(Convolutional Neural Nets, CNNs)是圖像和視頻識別領域公認的主力軍,而循環神經網絡(Recurrent Neural Nets, RNNs)在自然語言處理領域的地位與其是相似的。
但二者的一個主要不同是,CNN 可以識別靜態圖像(或以幀分割的視頻)中的特征,而 RNN 在文本和語音方面表現出色,因為這類問題屬于序列或時間依賴問題。也就是說,待預測的后一個字符或單詞依賴于前面的(從左到右)字符或單詞,因此引入時間的概念,進而考慮到序列。
實際上,RNN 在所有的序列問題上都有良好表現,包括語音 / 文本識別、機器翻譯、手寫體識別、序列數據分析(預測),甚至不同配置下的自動編碼生成等等。
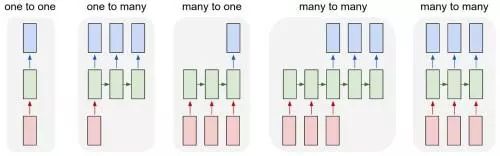
在很短的一段時期里,RNN 的改進版本大行其道,其中包括 LSTM(long short term memory,長短期記憶網絡)和 GRU(gated recurring units,門循環單元)。這二者都改進了 RNN 的記憶范圍,令數據可以將距離其很遠的文本信息利用起來。
解決“才怪”問題
當 RNN 從左到右按順序讀取字符時,上下文就成了一個重要問題。比如,對一條評論進行情感分析時,剛開始的幾句話可能是正面的(例如,食物好,氣氛好)但以負面評論結束(如服務差,價格高),最后整條評論實際上是負面的。這其實在邏輯上等同于“才怪”的玩笑:“這個領帶看著不錯……才怪!”
這個問題的解決方案是使用兩個 LSTM 編碼器,同時從兩個方向讀取文本(即雙向編碼器)。這相當于在現在掌握了(文本的)未來信息。這很大程度上解決了問題。精度確實提高了。
Facebook 和 Google 遭遇的一個問題
早些年,當 Facebook 和 Google 發布各自的自動語言翻譯系統時,他們意識到了一個問題——翻譯耗時太長了。
這實際上是 RNN 在內部設計上存在的一個問題。由于網絡一次只讀取、解析輸入文本中的一個單詞(或字符),深度神經網絡必須等前一個單詞處理完,才能進行下一個單詞的處理。
這意味著 RNN 不能像 CNN 那樣進行大規模并行處理(massive parallel processing,MPP),特別是在 RNN/LSTM 對文本進行雙向處理時。
這也意味著 RNN 極度地計算密集,因為在整個任務運行完成之前,必須保存所有的中間結果。
2017 年初,Google 和 Facebook 針對該問題提出了相似的解決方案——在機器翻譯系統中使用 CNN,以便將大規模并行處理的優勢發揮出來。在 CNN 中,計算不依賴于之前時間的信息,因此每個計算都是獨立的,可以并行起來。
Google 的解決方案叫做 ByteNet,而 Facebook 的稱為 FairSeq(這是用 Facebook 內部的人工智能研究團隊 FAIR 來命名的)。FairSeq 的代碼已發布至 GitHub。
Facebook 稱他們的 FairSeq 網絡的運行速度比基本的 RNN 快 9 倍。
基本工作原理
CNN 在處理圖像時,將圖像看作一個二維的“塊”(高度和寬度);遷移到文本處理上,就可以將文本看作一個一維對象(高度 1 個單位,長度 n 個單位)。
但 RNN 不能直接預定義對象長度,而 CNN 需要長度信息。因此,要使用 CNN,我們必須不斷增加層數,直到整個感受野都被覆蓋為止。這種做法會讓 CNN 非常深,但是得益于大規模并行處理的優勢,無論網絡多深,都可以進行并行處理,節省大量時間。
特殊結構:選通 + 跳躍 = 注意力
當然,具體的解決方案不會像上面所說的那樣簡單。Google 和 Facebook 還向網絡中添加了一個特殊結構:“注意力(Attention)”函數。
最初的注意力函數是去年由 Google Brain 和多倫多大學的研究者們提出的,命名為變換器(Transformer)。
原論文鏈接:
https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf。
當時,Facebook 和 Google 使用的函數幾乎一模一樣,因此該函數備受關注,被稱為“注意力”函數。該函數有兩個獨特的特征。
第一個特征被 Facebook 稱為“多跳躍”。和傳統 RNN 方法的每個句子只“看”一次不同,多跳躍讓系統可以“瞥”一個句子“好多眼”。這種行為和人工翻譯更相似。
每“一瞥”可能會關注某個名詞或動詞,而這些詞并不一定是一個序列,因此在每一次迭代中可以更深入地理解其含義。每“瞥”之間可能是獨立的,也可能依賴于前面的“瞥”,然后去關注相關的形容詞、副詞或助動詞等。
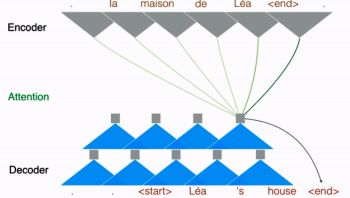
上圖是 Facebook 給出的一個法英翻譯的例子,展示了第一次迭代的過程。該次迭代編碼了每一個法語單詞,然后用“多跳躍”的方法選擇最合適的英文翻譯。
第二個特征是選通(即門控制),用來控制各隱藏層之間的信息流。在上下文理解過程中,門通過對 CNN 的尺度控制,來判斷哪些信息能更好地預測下一個單詞。
不只是機器翻譯——時間卷積網絡(TCN)
至 2017 年中旬,Facebook 和 Google 已經通過使用 CNN 和注意力函數,完全解決了機器翻譯的時間效率問題。而更重要的一個問題是,這種技術大有用武之地,不能將其埋沒在加速機器翻譯的小小任務中。我們能否將其推廣到所有適用于 RNN 的問題?答案是,當然可以。
2017 年,相關的研究發表了很多;其中有些幾乎是和 Facebook、Google 同時發表的。其中一個敘述比較全面的論文是 Shaojie Bai、J. Zico Kolter 和 Vladlen Koltun 發表的“An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling”。
原文鏈接:https://arxiv.org/pdf/1803.01271.pdf。
有些同仁將這種新架構命名為時間卷積網絡。當然隨著工業上的應用,這個名稱有可能會被更改。
上述論文所做的工作是在 11 個不同的、非語言翻譯類的工業標準 RNN 問題上,將 TCN 與 RNN、LSTM、GRU 進行了直接比較。
研究的結論是:TCN 在其中的 9 個問題中,不僅速度更快,且精度更高;在 1 個問題中與 GRU 打了平手(下表中的粗體文字代表精度最高項。圖片截取自原論文)。
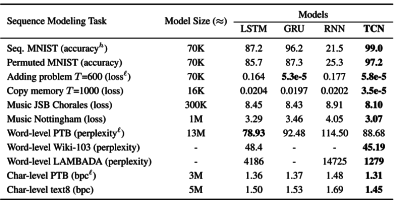
TCN 優缺點
Shaojie Bai、J. Zico Kolter 和 Vladlen Koltun 還給出了下面這一實用的列表,列舉了 TCN 的優缺點。
速度很重要。更快的網絡能使反饋環更短。由于在 TCN 中可以進行大規模并行處理,網絡訓練和驗證的時間都會變短。
TCN 為改變感受野大小提供了更多靈活性,主要是通過堆疊更多的卷積層、使用更大的膨脹系數及增大濾波器大小。這些操作可以更好地控制模型的記憶長短。
TCN 的反向傳播路徑和序列的時間方向不同。這避免了 RNN 中經常出現的梯度爆炸或梯度消失問題。
訓練時需要的內存更少,尤其是對于長輸入序列。
然而,作者指出,TCN 在遷移學習方面可能沒有 CNN 的適應能力那么強。這是因為在不同的領域,模型預測所需要的歷史信息量可能是不同的。因此,在將一個模型從一個對記憶信息需求量少的問題遷移到一個需要更長記憶的問題上時,TCN 可能會表現得很差,因為其感受野不夠大。
進一步考慮TCN 已經被應用在很多重要領域,也獲得了極大成功,甚至幾乎可以解決一切序列問題。因此,我們需要重新考慮我們之前的看法。序列問題不再是 RNN 的專屬領域,而 TCN 應該成為我們未來項目的優先選項。
-
神經網絡
+關注
關注
42文章
4773瀏覽量
100877 -
cnn
+關注
關注
3文章
352瀏覽量
22242
原文標題:時間卷積網絡(TCN)在 NLP 多領域發光,RNN 或將沒落
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
電子元器件篩選方案的設計原則及篩選項目
基于Arduino的灌溉項目的問題解析
APP會成為區塊鏈的未來嗎?
如何指定優先級
有歷史才有未來,DigiPCBA的項目歷史
TCN75A/TCN75中文資料,pdf (數字溫度傳感器)
探究TCN列車網絡的未來發展
關于MPLAB Harmony中項目恢復和備份選項的具體介紹
存儲優先架構存在優勢 或是AI芯片的未來
區塊鏈項目的治理問題探討
為什么使用CubeMx配置NVIC時不見子優先級選項





 工商網監
工商網監
評論