


【導(dǎo)讀】互聯(lián)網(wǎng)公司每天都面臨著處理大規(guī)模機器學(xué)習(xí)應(yīng)用程序的問題,因此我們需要一個可以處理這種超大規(guī)模的日常任務(wù)的分布式系統(tǒng)。最近,以集成樹為構(gòu)建模塊的深度森林(Deep Forest)算法被提出,并在各個領(lǐng)域取得了極具競爭力的效果。然而,這種算法的性能還未在超大規(guī)模的任務(wù)中得到測試。近日,基于螞蟻金服的參數(shù)服務(wù)器系統(tǒng)“鯤鵬”及其人工智能平臺“PAI”,螞蟻金服和南京大學(xué)周志華教授的研究團(tuán)隊合作開發(fā)了一種分布式的深度森林算法,同時提供了一個易于使用的圖形用戶界面(GUI)。
為了滿足現(xiàn)實世界的任務(wù)需求,周志華團(tuán)隊等對原始的深度森林模型進(jìn)行了諸多改進(jìn)。針對超大規(guī)模的任務(wù),如套現(xiàn)欺詐(cash-out fraud)行為的自動檢測 (擁有超過1億的訓(xùn)練樣本),研究人員測試了深度森林模型的性能。實驗結(jié)果表明,在不同的評估標(biāo)準(zhǔn)下,只需微調(diào)模型的參數(shù),深度森林模型便能在大規(guī)模任務(wù)處理上取得當(dāng)前最佳的性能,從而有效地阻止大量套現(xiàn)欺詐行為的發(fā)生。即使和目前已經(jīng)部署的其他最佳模型相比,深度森林模型依然能夠顯著減少經(jīng)濟(jì)損失。
以下是論文內(nèi)容:
▌簡介
對于螞蟻金融這樣的金融公司,套現(xiàn)欺詐行為是常見危害之一。買家通過螞蟻金融發(fā)行的螞蟻信用服務(wù)與賣家進(jìn)行交易支付,并從賣家處獲得現(xiàn)金。如果沒有合適的欺詐檢測手段,那么每天詐騙者就能夠從套現(xiàn)欺詐中獲取的大量現(xiàn)金,這對網(wǎng)絡(luò)信用構(gòu)成了一個嚴(yán)重的威脅。目前,基于機器學(xué)習(xí)的檢測方法,如邏輯回歸 (LR) 和多元加性回歸樹 (MART),能夠在一定程度上預(yù)防這種欺詐行為,但是我們需要更有效的方法,因為任何微小的改進(jìn)都將顯著地降低經(jīng)濟(jì)損失。另一方面,隨著數(shù)據(jù)驅(qū)動的機器學(xué)習(xí)模型有效性的日益提高,數(shù)據(jù)科學(xué)家經(jīng)常與產(chǎn)品部門密切合作,為這些任務(wù)設(shè)計并部署有效的統(tǒng)計模型。對數(shù)據(jù)科學(xué)家和機器學(xué)習(xí)工程師來說,希望通過一個理想的高性能平臺來處理大規(guī)模的學(xué)習(xí)任務(wù) (經(jīng)常有數(shù)百萬或數(shù)十億的訓(xùn)練樣本)。此外,這個平臺的搭建過程要簡單,并能運行不同的任務(wù)以提高生產(chǎn)力。
基于樹結(jié)構(gòu)的模型,如隨機森林和多重加權(quán)回歸樹模型,仍然是各種任務(wù)的主要方法之一。由于這種模型的優(yōu)越性能,在 Kaggle 比賽或數(shù)據(jù)科學(xué)項目中大部分的獲勝者也都使用集成的多元加性回歸樹模型 (ensemble MART) 或其變體結(jié)構(gòu)。由于金融數(shù)據(jù)的稀疏性和高維性,我們需要將其視為離散建模或混合建模問題,因此,諸如深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的模型并不適用于螞蟻金融這種公司的日常工作。
最近,周志華研究團(tuán)隊提出了一種深度森林算法,這是一種新的深層結(jié)構(gòu),無需進(jìn)行微分求解,特別適合樹結(jié)構(gòu)。相比于其他非深度神經(jīng)網(wǎng)絡(luò)模型,深度森林算法能夠?qū)崿F(xiàn)最佳性能;而相較于當(dāng)前最佳的深度神經(jīng)網(wǎng)絡(luò)模型,它能實現(xiàn)極具競爭力的結(jié)果。此外,深度森林模型的層數(shù)及其模型復(fù)雜性能夠自適應(yīng)于具體的數(shù)據(jù),其超參數(shù)的數(shù)量還比深度神經(jīng)網(wǎng)絡(luò)模型要少得多,可視為是一些現(xiàn)成分類器的優(yōu)秀替代品。
在現(xiàn)實世界中,許多任務(wù)都包含離散特征,當(dāng)使用深度神經(jīng)網(wǎng)絡(luò)進(jìn)行建模時,處理這些離散特征將會變得一個棘手的問題,因為我們需要將離散信息進(jìn)行顯式或隱式地連續(xù)轉(zhuǎn)換,但這樣的轉(zhuǎn)換過程通常會導(dǎo)致額外的偏差或信息的丟失。而基于樹結(jié)構(gòu)的深度森林模型能夠很好地處理這種數(shù)據(jù)類型問題。這項工作中,我們在分布式學(xué)習(xí)系統(tǒng)“鯤鵬”上實施并部署了深度森林模型,這是分布式深度森林模型在參數(shù)服務(wù)器上的第一個工業(yè)實踐,能夠處理數(shù)百萬的高維數(shù)據(jù)。
此外,在螞蟻金服的人工智能平臺上,我們還設(shè)計了一個基于 Web 的圖形用戶界面,允許數(shù)據(jù)科學(xué)家通過簡單地拖動和點擊就能自如地使用深度森林模型,而無需任何的編碼過程。這將方便數(shù)據(jù)科學(xué)家的工作,使得構(gòu)建和評估模型的過程變得非常有效且方便。
我們在這項工作中的主要貢獻(xiàn)可以總結(jié)如下:
-
基于現(xiàn)有的分布式系統(tǒng)“鯤鵬”,我們實現(xiàn)并部署了第一個分布式深度森林模型,并在我們的人工智能平臺 PAI 上為其搭建了一個易于使用的圖形界面。
-
我們對原始的深度森林模型進(jìn)行了許多改進(jìn),包括 MART 作為基礎(chǔ)學(xué)習(xí)者的效率和有效性,諸如基于成本的類別不平衡數(shù)據(jù)的處理方法,基于 MART 的高維數(shù)據(jù)特征選擇和不同級聯(lián)水平的評估指標(biāo)的自動確定等任務(wù)。
-
我們在套現(xiàn)欺詐行為的自動檢測任務(wù)上驗證了深度森林模型的性能。結(jié)果表明,在不同的評估指標(biāo)下,深度森林模型的性能都明顯優(yōu)于現(xiàn)有的所有方法。更重要的是,深度森林模型強大的魯棒性也在實驗中得到了驗證。
▌系統(tǒng)介紹
鯤鵬系統(tǒng)
鯤鵬是一款基于參數(shù)服務(wù)器的分布式學(xué)習(xí)系統(tǒng),該系統(tǒng)主要用于處理工業(yè)界出現(xiàn)的大規(guī)模任務(wù)。作為生產(chǎn)級別的分布式參數(shù)服務(wù)器,Kunpeng 系統(tǒng)具有如下幾大優(yōu)點:(1) 強大的故障轉(zhuǎn)移機制,保證大規(guī)模工作的高成功率; (2) 適用于稀疏數(shù)據(jù)和通用通信的高效接口; (3) 用戶友好型的 C ++ 和 Python 系統(tǒng)開發(fā)工具(SDKs)。其結(jié)構(gòu)簡圖如下圖1所示:
?
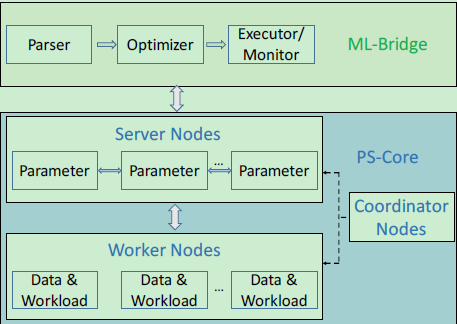
圖1:鯤鵬結(jié)構(gòu)簡圖,包括 ML-Bridge,PS-Core 部分。用戶可以在 ML-Bridge 上自如地操作。
分布式 MART
多元加權(quán)回歸樹模型 (MART),也稱為梯度提升決策樹模型 (GBDT) 或梯度增強機模型 (GBM),是一種在學(xué)術(shù)和工業(yè)領(lǐng)域廣泛使用的機器學(xué)習(xí)算法。得益于其高效而優(yōu)秀的模型可解釋性,在這項工作中我們在分布式系統(tǒng)中部署 MART,并將其作為分布式深度森林模型的基本組成部分。此外,我們還結(jié)合了其他的樹結(jié)構(gòu)模型進(jìn)一步開發(fā)深度森林模型的分布式版本。
深度森林模型結(jié)構(gòu)
深度森林模型是最近提出的一種以集成樹為構(gòu)建模塊的深度學(xué)習(xí)框架。 其原始版本由 ne-grained 模塊和級聯(lián)模塊 (cascading module) 構(gòu)成。在這項工作中,我們棄用了 ne-grained 模塊,并建立了多層的級聯(lián)模塊,每層由幾個基礎(chǔ)的隨機森林或完全隨機森林模塊構(gòu)成,其結(jié)構(gòu)如下圖2所示。 對于每個基礎(chǔ)模塊而言,輸入是由前一層產(chǎn)生的類向量和原始的輸入數(shù)據(jù)組合而成的,然后再將每個基礎(chǔ)模塊的輸出組合得到最終的輸出。此外,對每一層進(jìn)行 K 倍驗證,當(dāng)驗證集的準(zhǔn)確率不在提高時,級聯(lián)過程也隨之自動終止。
?
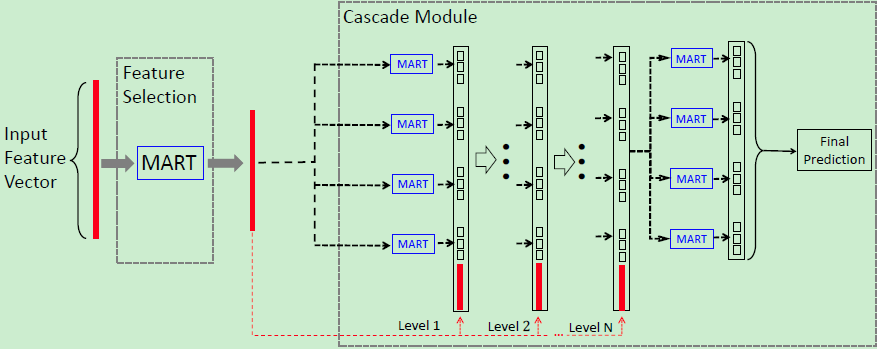
圖2:深度森林模型結(jié)構(gòu)
對于一般的工作部署策略,模型訓(xùn)練模塊需要在所有數(shù)據(jù)準(zhǔn)備工作完成后才能開始工作,而模型測試模塊也必須在所有模型都訓(xùn)練成功后才能開始預(yù)測,這樣顯著地降低了系統(tǒng)的工作效率。因此,在分布式系統(tǒng)上,我們采用有向無環(huán)圖 (DAG) 來提高系統(tǒng)工作的效率。有向無環(huán)圖,顧名思義就是一個沒有定向循環(huán)的有向圖,其結(jié)構(gòu)如下圖3所示。
?
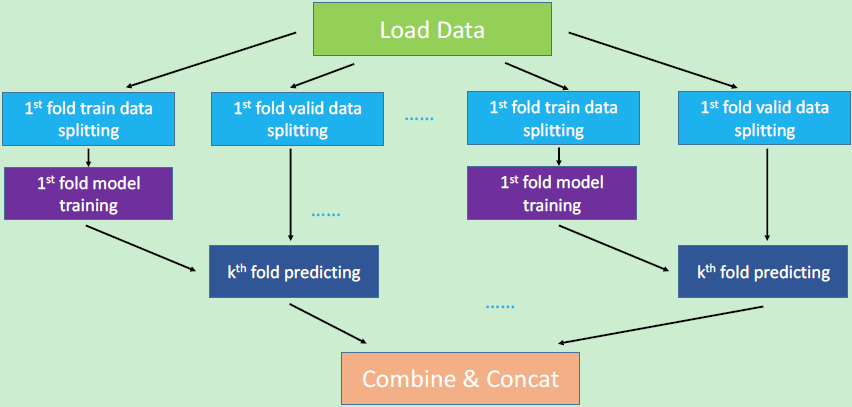
圖3:有向無環(huán)圖的工作調(diào)度,每個長方形代表一個進(jìn)程,只有彼此相關(guān)的進(jìn)程才能互相連接。
我們將圖中的一個節(jié)點視為一個進(jìn)程,并且只連接彼此相關(guān)的進(jìn)程。兩個相關(guān)節(jié)點的先決條件是一個節(jié)點的輸出作為另一節(jié)點的輸入。只有當(dāng)一個節(jié)點的所有先決條件都滿足時,另一節(jié)點才會被執(zhí)行。每個節(jié)點都是分開執(zhí)行的,這意味著一個節(jié)點發(fā)生故障時并不會影響隨后的其他節(jié)點。如此,系統(tǒng)的等待時間將顯著地、縮短,因為每個節(jié)點只需要等待相應(yīng)節(jié)點的執(zhí)行完畢。更重要的是,這樣的系統(tǒng)設(shè)計為故障轉(zhuǎn)移提供了更好的解決方案。例如,當(dāng)一個節(jié)點因為某些原因?qū)е卤罎ⅲ敲粗灰驗樗那疤釛l件滿足了,我們就可以從這個節(jié)點開始重新運行,而不需要從頭開始運行整個算法。
圖形用戶界面(GUI)
如何有效地構(gòu)建并評估模型性能,對于生產(chǎn)力的提高是至關(guān)重要的。為了解決這個問題,我們在螞蟻金服的人工智能平臺 PAI 上開發(fā)了一個圖形用戶接口 (GUI)。
下圖4展示了深度森林模型的 GUI 界面,其中箭頭表示數(shù)據(jù)流之間的序列相關(guān)性,圖中每個節(jié)點代表一個操作,包括加載數(shù)據(jù),構(gòu)建模型,模型預(yù)測等。例如,一個深度森林模型的所有細(xì)節(jié)都被封裝成一個單一節(jié)點,我們只需要指定使用哪個基礎(chǔ)模塊,模塊中每層的數(shù)量及其他一些基礎(chǔ)配置。這里默認(rèn)的基礎(chǔ)模塊是前面提到的 MART。 因此,用戶只需要點擊幾下鼠標(biāo)就能在幾分鐘內(nèi)快速創(chuàng)建深度森林模型,并在模型訓(xùn)練結(jié)束后得到評估結(jié)果。
?
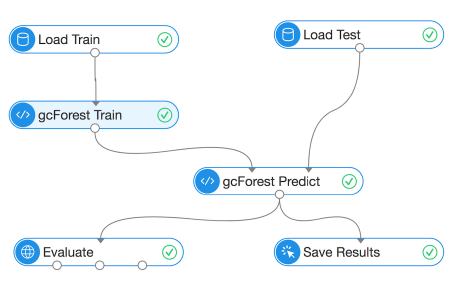
圖4:PAI 平臺上深度森林模型的 GUI 界面,每個節(jié)點代表一個操作。
▌實驗應(yīng)用
數(shù)據(jù)準(zhǔn)備
我們在現(xiàn)金支付欺詐的自動檢測任務(wù)上驗證深度森林模型的性能。對于這個檢測任務(wù),我們需要做的事檢測出欺詐行為的潛在風(fēng)險,以避免不必要的經(jīng)濟(jì)損失。我們將這個任務(wù)視為二元分類問題,并收集四個方面的原始信息,包括描述身份信息的賣家特征和買家特征,描述交易信息的交易特征和歷史交易特征。如此,每當(dāng)一次交易發(fā)生時,我們就能收集到超過 5000 維的數(shù)據(jù)特征,其中包含了數(shù)值和分類特征。
為了構(gòu)建模型的訓(xùn)練和測試數(shù)據(jù)集,我們對連續(xù)幾個月在 O2O 交易中使用螞蟻信用支付的用戶數(shù)據(jù)進(jìn)行采樣來得到訓(xùn)練數(shù)據(jù),并將往后幾個月中相同場景下的數(shù)據(jù)作為測試數(shù)據(jù)。
數(shù)據(jù)集的詳細(xì)信息如下表1所示,這是一個大規(guī)模的且類別不均衡任務(wù)。正如我們前面提到的,收集到的原始數(shù)據(jù)維度高達(dá) 5000 維,這其中可能包含一些不相關(guān)的特征屬性,如果直接使用的話,整個訓(xùn)練過程將非常耗時,同時也將降低模型部署的效率。因此,我們使用 MART 模型來計算并選擇我們所需的特征。
具體來說,首先我們用所有維度的特征來訓(xùn)練 MART 模型,然后計算出特征的重要性分?jǐn)?shù),以此選擇相對重要的特征。實驗結(jié)果表明,使用前 300 個特征重要性分?jǐn)?shù)較高的特征,我們的模型能夠達(dá)到相當(dāng)有競爭力的性能,且在驗證過程中進(jìn)一步證明了特征的冗余性。因此,我們以特征重要性分?jǐn)?shù)來過濾原始特征,并保留前300個特征作為我們模型訓(xùn)練所需。
?
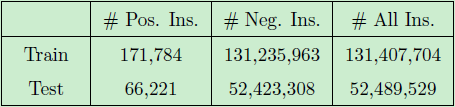
表1:訓(xùn)練集和測試集的數(shù)據(jù)樣本量
▌實驗結(jié)果分析
我們在不同的評估標(biāo)準(zhǔn)下測試分布式深度森林模型的性能,并討論具體的分析結(jié)果。
通用評估標(biāo)準(zhǔn)
在通用的評估標(biāo)準(zhǔn)下,包括 AUC 分?jǐn)?shù),F(xiàn)1 分?jǐn)?shù)和 KS 分?jǐn)?shù),我們對比評估了 Logistic 回歸模型 ( LR),深度神經(jīng)網(wǎng)絡(luò) (DNN),多元加權(quán)回歸樹模型 (MART) 及我們的深度森林模型 (gcForest) 的性能,結(jié)果如下表2所示:
?
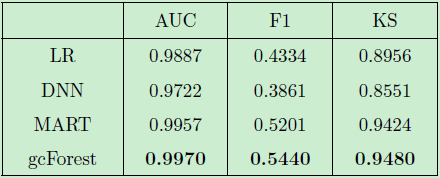
表2:通用評估標(biāo)準(zhǔn)下的實驗對比結(jié)果
特定評估標(biāo)準(zhǔn) (Recall)
對于正樣本的回召率 ,我們對比評估了四種方法的性能,其結(jié)果如表3所示:
?
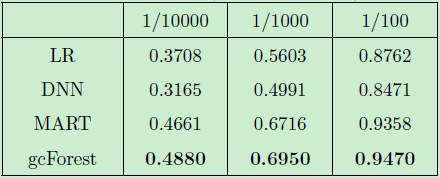
表3:特定評估標(biāo)準(zhǔn)下的實驗對比結(jié)果。
PR 曲線
為了更直觀地對比四種方法的檢測性能,我們繪制了 PR (Precision-Recall) 曲線,如圖5所示。我們能夠清楚地看到,深度森林模型的 PR 曲線包含了其他所有方法,這意味著深度森林模型的檢測性能要比其他方法的性能好得多,這進(jìn)一步驗證了深林模型的有效性。
?
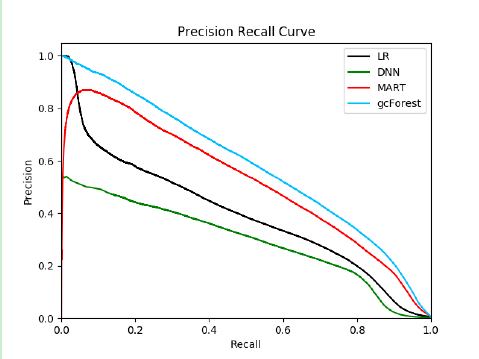
圖5:LR, DNN, MART 和 gcForest 模型的 PR 曲線
經(jīng)濟(jì)效益
在不同的評估標(biāo)準(zhǔn)下,我們已經(jīng)逐一分析了實驗結(jié)果并驗證了深度森林模型用于處理大規(guī)模任務(wù)的有效性。在套現(xiàn)欺詐行為的檢測任務(wù)上,與之前最好的 MART 模型相比 (由 600 個樹結(jié)構(gòu)構(gòu)成的 MART 模型),深度森林模型 (以 MART 模型為基礎(chǔ)模塊,每個 MART 模塊只需 200 個樹結(jié)構(gòu)) 能夠以更簡單的結(jié)構(gòu)帶來更顯著的經(jīng)濟(jì)效益,大大降低了經(jīng)濟(jì)損失。
模型魯棒性分析
針對上述的評估標(biāo)準(zhǔn),我們對不同的方法分別進(jìn)行了魯棒性分析,其結(jié)果如表4,表5 及圖6所示,分別對應(yīng)通用評價標(biāo)準(zhǔn),特定評價標(biāo)準(zhǔn) (Recall) 及 PR 曲線的魯棒性分析結(jié)果。其中 gcForest-d 代表默認(rèn)設(shè)置下的深度森林模型,而 gcForest-t 代表微調(diào)后的深度森林模型。
?
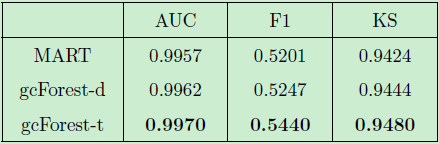
表4:通用標(biāo)準(zhǔn)下的實驗對比結(jié)果 (魯棒性分析)
?
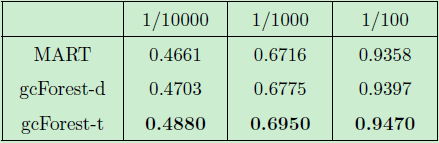
表5:特定標(biāo)準(zhǔn)下的實驗對比結(jié)果 (魯棒性分析)
?
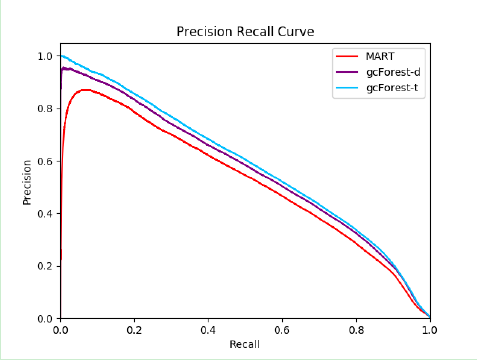
圖6:默認(rèn)設(shè)置下的 gcForest-d,微調(diào)后的 gcForest-t 及 MART 模型的 PR 曲線
我們可以看到,默認(rèn)設(shè)置下的 gcForest-d 模型的性能已經(jīng)遠(yuǎn)遠(yuǎn)優(yōu)于精調(diào)后的 MART 模型,而微調(diào)后的 gcForest-t 模型則能夠取得更好的性能。
-
人工智能
+關(guān)注
關(guān)注
1803文章
48371瀏覽量
244362 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8476瀏覽量
133777 -
螞蟻金服
+關(guān)注
關(guān)注
0文章
44瀏覽量
7531
原文標(biāo)題:周志華團(tuán)隊和螞蟻金服合作:用分布式深度森林算法檢測套現(xiàn)欺詐
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
使用VirtualLab Fusion中分布式計算的AR波導(dǎo)測試圖像模擬
分布式云化數(shù)據(jù)庫有哪些類型
基于ptp的分布式系統(tǒng)設(shè)計
HarmonyOS Next 應(yīng)用元服務(wù)開發(fā)-分布式數(shù)據(jù)對象遷移數(shù)據(jù)權(quán)限與基礎(chǔ)數(shù)據(jù)
特力康輸電線路分布式故障定位監(jiān)測裝置:提升電網(wǎng)可靠性的關(guān)鍵

分布式通信的原理和實現(xiàn)高效分布式通信背后的技術(shù)NVLink的演進(jìn)

淺談屋頂分布式光伏發(fā)電技術(shù)的設(shè)計與應(yīng)用
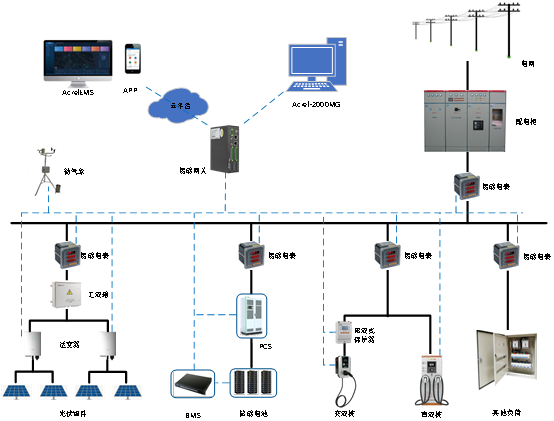
解決電網(wǎng)逆流難題,實現(xiàn)分布式光伏發(fā)電全部自發(fā)自用

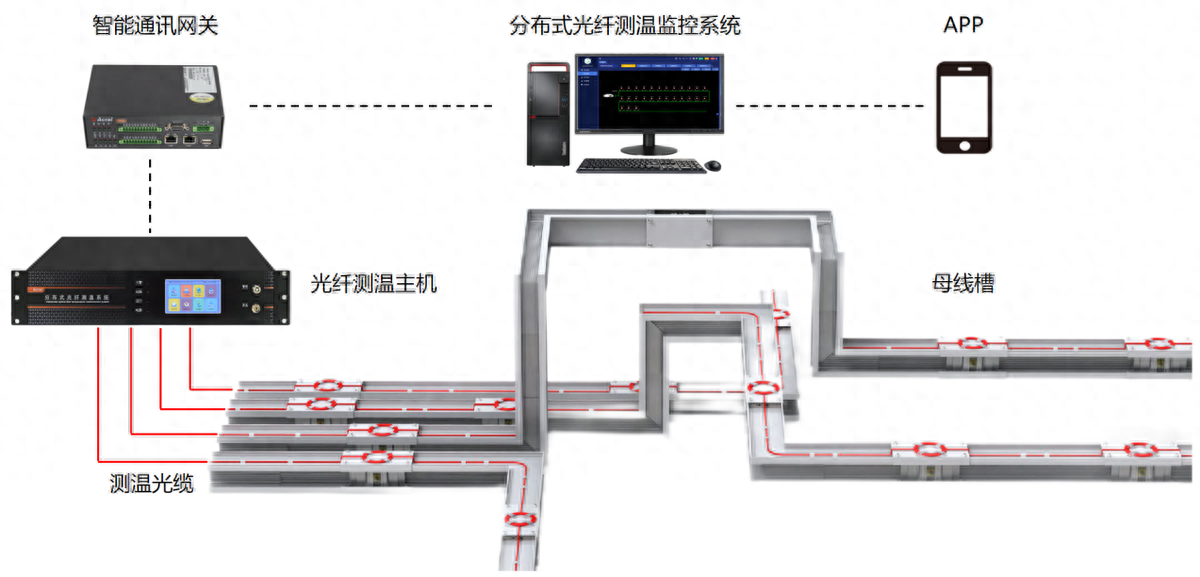
分布式光纖測溫是什么?應(yīng)用領(lǐng)域是?
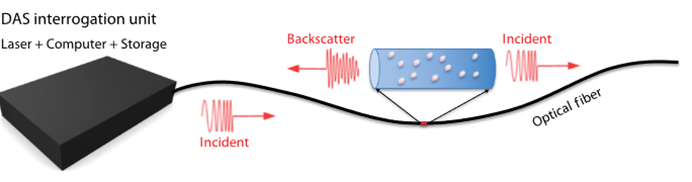
分布式光纖聲波傳感技術(shù)的工作原理
分布式輸電線路故障定位中的分布式是指什么






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論