 如何借助分布式GPU環境來提升神經網絡訓練系統的浮點計算能力
如何借助分布式GPU環境來提升神經網絡訓練系統的浮點計算能力
前言
在大型數據集上進行訓練的現代神經網絡架構,可以跨廣泛的多種領域獲取可觀的結果,涵蓋從圖像識別、自然語言處理,到欺詐檢測和推薦系統等各個方面。但訓練這些神經網絡模型需要大量浮點計算能力。雖然,近年來 GPU 硬件算力和訓練方法上均取得了重大進步,但在單一機器上,網絡訓練所需要的時間仍然長得不切實際,因此需要借助分布式GPU環境來提升神經網絡訓練系統的浮點計算能力。
TensorFlow分布式訓練
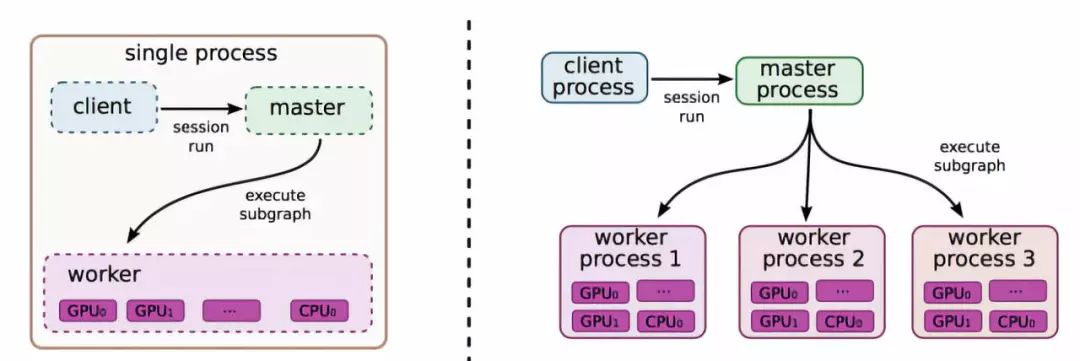
TensorFlow 采用了數據流范式, 使用節點和邊的有向圖來表示計算。TensorFlow 需要用戶靜態聲明這種符號計算圖,并對該圖使用復寫和分區(rewrite & partitioning)將其分配到機器上進行分布式執行。
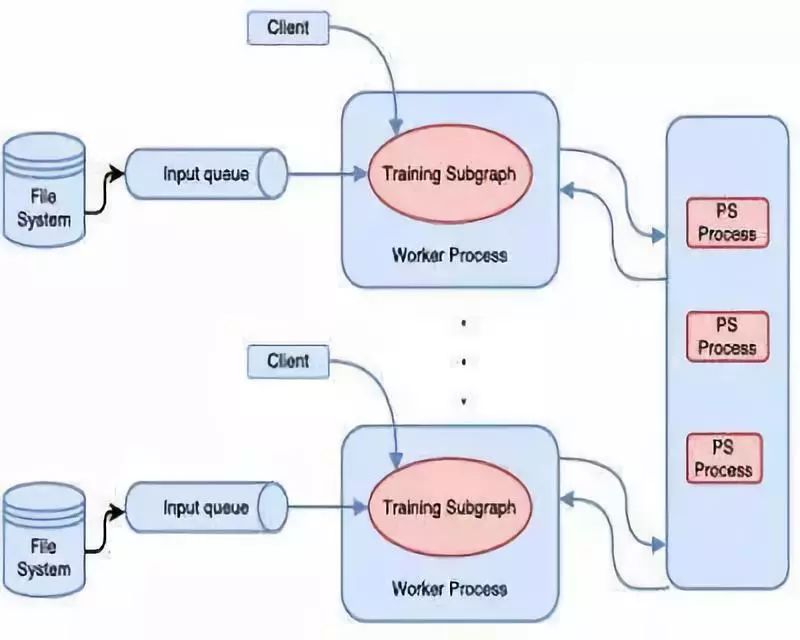
TensorFlow 中的分布式機器學習訓練使用了如圖所示的參數服務器方法 。
Cluster、Job、Task
關于TensorFlow的分布式訓練,主要概念包括Cluster、Job、Task,其關聯關系如下:
TensorFlow分布式Cluster由多個Task組成,每個Task對應一個tf.train.Server實例,作為Cluster的一個單獨節點;
多個相同作用的Task可以被劃分為一個Job,在分布式深度學習框架中,我們一般把Job劃分為Parameter Server和Worker,Parameter Job是管理參數的存儲和更新工作,而Worker Job運行OPs,作為計算節點只執行計算密集型的Graph計算;
Cluster中的Task會相對進行通信,以便進行狀態同步、參數更新等操作,如果參數的數量過大,一臺機器處理不了,這就要需要多個Task。
TensorFlow分布式計算模式
In-graph 模式
In-graph模式,將模型計算圖的不同部分放在不同的機器上執行。把計算從單機多GPU擴展到了多機多GPU, 不過數據分發還是在一個節點。這樣配置簡單, 多機多GPU的計算節點只需進行join操作, 對外提供一個網絡接口來接受任務。訓練數據的分發依然在一個節點上, 把訓練數據分發到不同的機器上, 將會影響并發訓練速度。在大數據訓練的情況下, 不推薦使用這種模式。
Between-graph 模式
Between-graph模式下,數據并行,每臺機器使用完全相同的計算圖。訓練的參數保存在參數服務器,數據不用分發,而是分布在各個計算節點自行計算, 把要更新的參數通知參數服務器進行更新。這種模式不需要再練數據的分發, 數據量在TB級時可以節省大量時間,目前主流的分布式訓練模式以 Between-graph為主。
參數更新方式
同步更新
各個用于并行計算的節點,計算完各自的batch 后,求取梯度值,把梯度值統一送到PS參數服務機器中,并等待PS更新模型參數。PS參數服務器在收集到一定數量計算節點的梯度后,求取梯度平均值,更新PS參數服務器上的參數,同時將參數推送到各個worker節點。
異步更新
PS參數服務器只要收到一臺機器的梯度值,就直接進行參數更新,無需等待其它機器。這種迭代方法比較不穩定,因為當A機器計算完更新了PS參數服務器中的參數,可能B機器還是在用上一次迭代的舊版參數值。
分布式訓練步驟
命令行參數解析,獲取集群的信息ps_hosts和worker_hosts,以及當前節點的角色信息job_name和task_index
創建當前Task結點的Server
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
如果當前節點是Parameter Server,則調用server.join()無休止等待;如果是Worker,則執行下一步
if FLAGS.job_name == "ps": server.join()
構建要訓練的模型
# build tensorflow graph model
創建tf.train.Supervisor來管理模型的訓練過程
# Create a "supervisor", which oversees the training process.sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0), logdir="/tmp/train_logs")# The supervisor takes care of session initialization and restoring from a checkpoint.sess = sv.prepare_or_wait_for_session(server.target)# Loop until the supervisor shuts downwhile not sv.should_stop() # train model
UAITrain分布式訓練部署
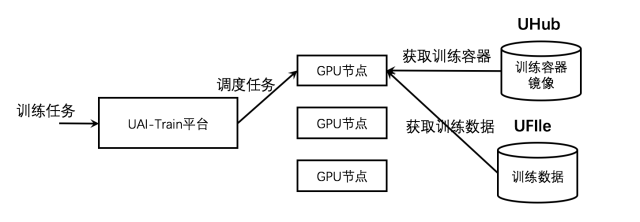
UCloud AI 訓練服務(UCloud AI Train)是面向AI訓練任務的大規模分布式計算平臺,基于高性能GPU計算節點提供一站式托管AI訓練任務服務。用戶在提交AI訓練任務后,無需擔心計算節點調度、訓練環境準備、數據上傳下載以及容災等問題。
目前,UAI--Train平臺支持TensorFlow 和 MXNet 框架的分布式訓練。需要將PS代碼和Worker代碼實現在同一個代碼入口中,執行過程中,PS 和 Worker 將使用相同的Docker容器鏡像和相同的python代碼入口進行執行,系統將自動生成PS和Worker的env環境參數。TensorFlow 分布式訓練采用PS-Worker的分布式格式,并提供python的接口運行分布式訓練。
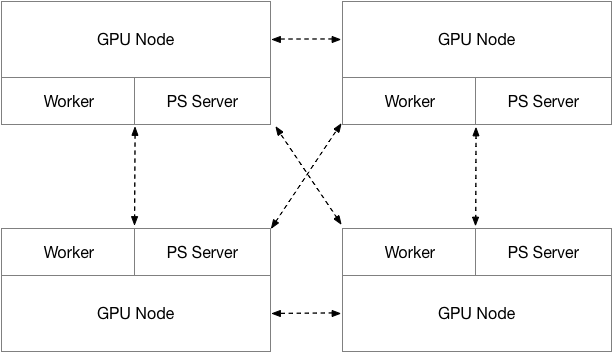
UAI--Train分布式訓練采用Parameter Server和Worker Server混合部署的方法,所有計算節點均由GPU物理云主機組成。PS 僅使用CPU進行計算,Worker Server則同時使用GPU和CPU進行計算,PS 和 Worker的比例為1:1。
數據存儲
分布式訓練所使用的輸入數據可以來自不同的數據源,目前UAI--Train僅支持UFS作為數據的存儲。
Input 數據存儲
指定一個UFS網盤作為Input數據源,UAI--Train平臺在訓練執行過程中會將對應的UFS數據映射到訓練執行的Worker容器的 /data/data 目錄下,系統會自動將數據映射到執行的容器中,如 ip:/xxx/data/imagenet/tf → /data/data/。
Output 數據存儲
指定一個UFS網盤作為output數據源,UAI--Train平臺在訓練執行過程中會將對應的UFS數據映射到訓練執行的每一個PS容器和Worker容器的 /data/output 目錄下,并以共享的方式訪問同一份數據。同時,在訓練過程可以通過其云主機實時訪問訓練保存的模型checkpoint。
案例:通過CIFAR-10進行圖像識別
CIFAR-10是機器學習中常見的圖像識別數據集,該數據集共有60000張彩色圖像。這些圖像,分為10個類,每類6000張圖,有50000張用于訓練,另外10000用于測試。
http://groups.csail.mit.edu/vision/TinyImages/
調整訓練代碼
為了在UAI平臺上進行訓練,首先下載源代碼,并對cifar10_main.py做如下修改:
添加相關參數:--data_dir, --output_dir, --work_dir, --log_dir, --num_gpus,UAITrain平臺將會自動生成這些參數;
在代碼中增加UAI參數:使用data_dir配置輸入文件夾、使用output_dir配置輸出文件夾。
具體案例代碼可以在https://github.com/ucloud/uai-sdk/tree/master/examples/tensorflow/train/cifar獲取
在UAI--Train平臺執行訓練
據https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10_estimator 的說明生成CIFAR-10的tfrecords;
使用UAI-SDK提供的tf_tools.py 生成CIFAR-10樣例的Docker鏡像;
確保Docker鏡像已經上傳至UHub,在UAI--Train平臺上執行。
/data/cifar10_main.py --train-batch-size=16
在UAI平臺上的分布式訓練
CIFAR-10樣例代碼使用tf.estimator.Estimator API,只需一個分布式環境和分布式環境配置便可直接進行分布式訓練,該配置需要適用于tf.estimator.Estimator API的標準,即定義一個TF_CONFIG 配置。
TF_CONFIG = {
"cluster":{
"master":["ip0:2222"],
"ps":["ip0:2223","ip1:2223"],
"worker":["ip1:2222"]},
"task":{"type":"worker","index":0},
"environment":"cloud"
}
UAITrain平臺的分布式訓練功能可以自動生成TensorFlow分布式訓練的GPU集群環境,同時為每個訓練節點自動生成TF_CONFIG。因此,在UAITrain平臺上執行CIFAR-10的分布式訓練和單機訓練一樣,僅需要指定input/output的UFS地址并執行如下指令即可:
/data/cifar10_main.py --train-batch-size=16
總結
UAI--Train TensorFlow的分布式訓練環境實現基于TensorFlow 的分布式訓練系統實現,采用默認的grpc協議進行數據交換。PS和Worker采用混合部署的方式部署,PS使用純CPU計算,Worker使用GPU+CPU計算。
在UAI--Train平臺中可以非常方便的開展分布式計算,提高效率、壓縮訓練時間。最后通過CIFAR-10 案例解析在UAITrain平臺上訓練所需做出的修改,并在UAITrain平臺上進行分布式UAI--Train平臺訓練。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100714 -
網絡訓練
+關注
關注
0文章
3瀏覽量
1497
原文標題:基于UAI-Train平臺的分布式訓練
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從AlexNet到MobileNet,帶你入門深度神經網絡
ETPU-Z2全可編程神經網絡開發平臺
嵌入式神經網絡有哪些挑戰
用S3C2440訓練神經網絡算法
基于BP神經網絡的PID控制
如何進行高效的時序圖神經網絡的訓練
Gaudi Training系統介紹
基于BP神經網絡的分布式傳感器網絡的可靠性分析
基于神經網絡的分布式電源在PSASP中應用





 工商網監
工商網監
評論