


一、圖數據中蘊藏著秘密
事物之間的關聯信息,人類已經積累了很多,但絕大多數人不知道如何利用它們。
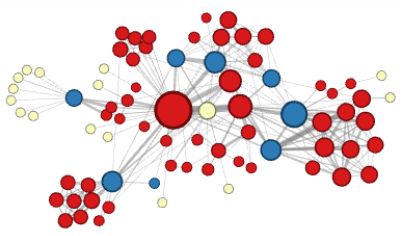
社交媒體中的互動和關系網絡圖中,蘊含著深意。像WordNet這樣的同義圖表能夠通過計算機視覺,幫助我們更好地理解和識別特定情形下研究對象之間的聯系。從家譜到分子結構,我們周圍世界中海量的信息都以圖的形式呈現。
盡管普遍存在,圖結構(Graph Structure)在機器學習的應用方面還是經常被忽視。比如“時尚潮流推薦問題”,其目標在于發現特定的能夠形成凝聚趨勢的一些衣服形式,也就是“風格”(style)。
通常的做法是從社交媒體抓取圖片并識別這些圖片中的衣服,然后用這些圖片的流行程度代表特定“風格”服裝的流行程度。用這種方式去了解流行樣式風格當然可行,這個模型能夠輕易地通過圖數據獲得優化。比如,我們可以分析用戶社交網絡中潮流趨勢,或者提取馬遜購物網站中的“相關聯產品”的集合目錄。
那么,為什么結構化的信息經常被忽視呢?因為多數情況下,從這些圖表中提取有效的特征實在是個巨大的挑戰。
在本文中,我們將探索一些從圖數據中提取有效特征的新技術。特別地,我們將重點討論那些利用隨機遍歷方法,來量化圖中節點之間的相似性。這些技術主要依靠自然語言處理群體的現有結果。
我將建議一些未來的研究途徑,特別是與時變圖形的學習特征有關。最后,我們將簡要討論圖卷積網絡 (GCNs) 的大家族,它提供了一個在圖結構數據上進行機器學習的端到端的解決方案,而無需單獨的中間特征提取步驟。
這些方法本身就構成了機器學習的一個子領域,但是研究人員和從業者可以從他們感興趣的特定范疇的結構中獲益。
二、基于圖的特征學習
2.1 圖摘要的計算
當我們在圖上進行機器學習的時候,我們通常需要計算一個圖摘要(graph summary),它會將圖中每一個頂點映射為一個實值特征向量,而該向量則編碼了這個頂點的相鄰頂點的信息,這樣做對于基于圖的機器學習是很有幫助的。
如果兩個頂點具有相似的鄰居(neighborhoods)(這里的“鄰居”一詞很寬泛,它通常用于捕捉某種局部概念,例如從某一頂點出發,經過1或2跳(hops)的頂點集合都可稱為該頂點的“鄰居”),我們要學習一個函數,將這兩個頂點映射到?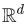 ?空間中的兩個相似的特征向量。
?空間中的兩個相似的特征向量。
然后圖中的的每一個頂點的特征向量就可以堆積為一個隱含的特征矩陣?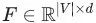 ?。有了頂點的向量化表征之后,我們就可以在其上運行標準的機器學習算法了。這是不是很棒啊!
?。有了頂點的向量化表征之后,我們就可以在其上運行標準的機器學習算法了。這是不是很棒啊!
DeepWalk(2014)和node2vec(2016)正是學習上述特征向量的兩個算法。下面我們就一起來看一下這兩個算法是怎么工作的吧。
2.2 DeepWalk:將隨機游走看做句子?
DeepWalk算法[1]背后關鍵的思想是,圖中的隨機游走(random walks)和句子很像。經驗發現,句子中的單詞和一個真實世界中圖上的隨機游走均服從冪律分布(power-law distribution)。也就是說,我們可以把這些隨機游走路徑想象成某種“語言”中的“句子”。
受這種相似性的啟發,DeepWalk使用原本被用于自然語言建模的優化技術來構建圖摘要。在標準的語言模型中,我們通常是給定某個詞的周邊詞,然后來估計該詞出現在一個句子中的概率。
另一方面,在DeepWalk算法中,則是給定某個頂點之前的頂點集合,來去估計該頂點出現在一個隨機游走過程中的概率。并且和語言模型一樣,我們還試圖去學習頂點?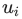 ?的特征向量?
?的特征向量?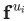 ?,以便估計這個概率。具體來說就是,給定某個分類器,去估計概率?
?,以便估計這個概率。具體來說就是,給定某個分類器,去估計概率?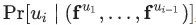 ?。我們的目的是,從向量空間?
?。我們的目的是,從向量空間?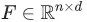 ?中,選擇特征向量,最大化如下目標:
?中,選擇特征向量,最大化如下目標:
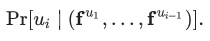 ?
?
然而遺憾的是,隨著隨機游走路徑長度的不斷增加,這個目標是很難處理的。因此DeepWalk論文作者使用給定當前頂點?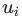 ?的向量表征?
?的向量表征?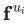 ?,來去預測其附近2w距離的鄰居頂點(注:w為窗口大小),從而重新界定了該問題。(從技術上來講,這是一個不同的優化問題,但是它可以作為之前目標的一個合理且與順序無關的替代目標[2])換句話說,我們要最大化目標概率:
?,來去預測其附近2w距離的鄰居頂點(注:w為窗口大小),從而重新界定了該問題。(從技術上來講,這是一個不同的優化問題,但是它可以作為之前目標的一個合理且與順序無關的替代目標[2])換句話說,我們要最大化目標概率:
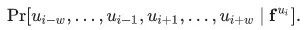 ?
?
但是,我們如何在整個隨機游走空間上最小化(譯者:最小化?不是最大化嗎?)該目標呢?其中一個策略如下(請注意, 論文作者另外假設了?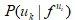 ?的條件獨立性):
?的條件獨立性):
抽樣一個頂點v,并生成一個隨機游走序列?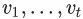 ?,其中?
?,其中?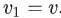 ?。
?。
對該序列中每一個頂點?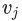 ?和每一個小于某一步長的?
?和每一個小于某一步長的?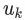 ?,在向量空間 F 上,應用梯度下降算法,最小化損失函數??
?,在向量空間 F 上,應用梯度下降算法,最小化損失函數??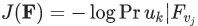 ?。
?。
這個算法雖然可行,但是也使得最后應用梯度下降算法的步驟變得尤為復雜,使得至少要更新?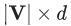 ?個參數。這對于數百萬級規模的圖來說,是一個非常嚴重的問題。
?個參數。這對于數百萬級規模的圖來說,是一個非常嚴重的問題。
為了解決這個問題,DeepWalk的作者使用“分層softmax (hierarchical softmax)”的方法(很抱歉,該方法不在本文介紹范圍內),將該優化問題拆解為一個二分類器的平衡樹(balanced tree of binary classifiers)。使用這些二分類器,可以將最后一步梯度下降算法的參數更新個數,從?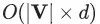 ?減少到?
?減少到? ?。
?。

Deepwalk算法示意圖
2.3 Node2vec:泛化到不同類型的鄰域
Grover and Leskovec (2016)[3]將Deepwalk算法拓展成為node2vec算法。與deepwalk算法不一樣,我們不再根據現有的結點運用一階隨機游走(first-order random walks)選擇下一個節點,node2vec不僅基于現有結點,還會使用現有結點前面的那一個結點,從而使用一系列二階隨機游走。
我們可以在隨機游走的每一步通過調節兩個參數值?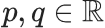 ?來確定具體的分布:大概來說,我們可以通過降低p值從而讓隨機游走偏向“探索”模式;同時,我們也可以通過提高q值讓隨機游走實現“廣度優先”(breadth-first)模式。
?來確定具體的分布:大概來說,我們可以通過降低p值從而讓隨機游走偏向“探索”模式;同時,我們也可以通過提高q值讓隨機游走實現“廣度優先”(breadth-first)模式。
這篇論文的關鍵想法是通過選擇不同模式的二階隨機游走,我們可以提取到網絡圖的不同特性。
為了證明它的必要性,作者們在文中給出了兩種在網絡圖上做機器學習通常使用的鄰域類型:(節點顏色代表類別)
在同質性假設下,由于高度連接的節點在網絡圖里位置相近,因此它們屬于同一個鄰域。
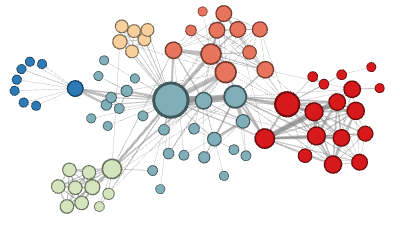
?
在結構性假設下,承擔著相似結構性功能的節點(比如說,網絡的所有中心節點)由于他們高階結構性顯著度,它們屬于同一個鄰域。
?
用兩個參數?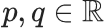 ?, 作者們提供了一種非常好用的方法在這兩種鄰域類型之間相互轉換。
?, 作者們提供了一種非常好用的方法在這兩種鄰域類型之間相互轉換。
就像Deepwalk一樣,node2vec的目標函數可以通過抽樣來實現最優化? ?,采用(p,q)隨機游走,然后通過梯度下降(gradient descent)來更新F,達到優化的目的。
?,采用(p,q)隨機游走,然后通過梯度下降(gradient descent)來更新F,達到優化的目的。
2.4 時變網絡(temporal networks)中的潛在特征
這些圖摘要技術很有用,但現實世界中很多圖是隨著時間變化的時變網絡。比如,社交網絡中一個人的朋友圈圖會隨著時間發生擴張或者收縮。我們可以使用node2vec,但是有兩個缺點:
每次隨著圖的改變而運行一個新的node2vec實例很耗算力
其次,難以保證多個node2vec的實例能產生相似的甚至是可比較的F矩陣
對于第一個問題,有一個解決方法--每次網絡改變后不立即運行node2vec,而是直到足夠多的邊發生改變使得原始嵌入的特征矩陣F質量下降再運行。
那么多少條邊發生改變才可以被認為發生了“顯著”的變化呢?這高度依賴于圖中特殊的邊和隨機游走中的(p, q)兩個參數。
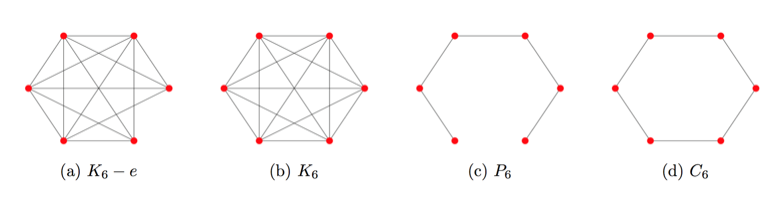
觀察下面這些圖:
?
注意到?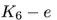 ?的領域和?
?的領域和?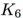 ?的鄰域很相似。然而,一條額外的邊把路徑圖?
?的鄰域很相似。然而,一條額外的邊把路徑圖?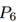 ?轉換成閉環?
?轉換成閉環?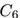 ?,顯著地改變了圖的隨機游走鄰域。類似這樣,連接網絡中的無連接或弱連接部分,起到橋梁作用的邊,相比其它邊更可能對鄰居產生顯著影響。
?,顯著地改變了圖的隨機游走鄰域。類似這樣,連接網絡中的無連接或弱連接部分,起到橋梁作用的邊,相比其它邊更可能對鄰居產生顯著影響。
幸運的是,很多現實世界中的圖,比如社交網絡,更傾向于?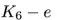 ?這種類型。網絡是高度連接的,增加和刪除節點的某條邊不會對DeepWalk中使用的一階隨機游走的嵌入產生顯著影響。需要注意的是,一階和二階的隨機游走差別很大,因此這里的討論內容對于擴展到node2vec可能并不是必要的。
?這種類型。網絡是高度連接的,增加和刪除節點的某條邊不會對DeepWalk中使用的一階隨機游走的嵌入產生顯著影響。需要注意的是,一階和二階的隨機游走差別很大,因此這里的討論內容對于擴展到node2vec可能并不是必要的。
在某種程度上,第二個問題可以通過連接從多個node2vec實例得出的特征,然后訓練一個自動編碼器,把這些綜合特征映射成壓縮的表示。
如何實現時變網絡上的可擴展特征學習呢?對于時變網絡,一些工具可以用于圖嵌入的增量更新,比如Abraham et al.(2016)[4]提出的動態頻譜稀釋器。
這方面仍然有大量工作需要做,即使是最好的稀釋器也因為速度太慢而難以實際應用于現實世界中的圖,即使存在亞對數算法,算法的常量因子也非常大。我相信,結合動態圖分割技術和更新圖摘要矩陣F對于時變圖的特征摘要來說或許是一個可行的方法。
另一個可選的方法是泛化node2vec算法到時變網絡,通過添加一個額外的參數λ,影響隨機游走經過“時變邊界”的概率。有些預測任務中可能有“時變位置”的概念,其中有著相似時間戳的圖的快照是相關的,而其他的或許有更久的依賴關系。
接下來我們開始介紹圖卷積網絡,一種最近提出的網絡圖上機器學習的方法。
三、圖卷積
Node2vec和DeepWalk的方法都是先生成“語料”然后用于后續的機器學習技術。相比之下,圖卷積(GCN)則是展示了一種端到端的方法進行結構化學習。
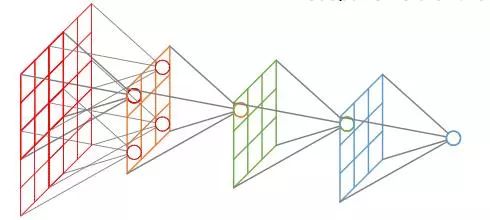
圖卷積
GCN嘗試將傳統的卷積神經網絡推廣到可變的、無序的結構中。由于圖沒有明確定義的順序,因此節點的排序不應該對GCN產生影響。很顯然,CNN并沒有這個特性,因為隨機交換圖像像素矩陣的行和列,再輸入給CNN必然會改變計算的輸出(通常,用于視覺問題的CNN,在識別圖像中的邊緣或其他局部結構時,其輸入在不同的行列置換下,計算結果并不是一成不變的)。
此外,CNN對像素鄰域的形狀并不是不可知的,換句話說,并沒有明顯的方式可以訓練一個CNN同時接受在正方形和六邊形網格上定義的圖像,即一個內在像素分別具有八個和六個直接鄰居。因此,為了解釋一般圖的動態結構,必須對CNN的激活函數(activation function)進行合理的松弛(relaxations)。
很多作者提出了不同的GCN松弛(relaxations)方法。其中一篇文章[5]定義了一種和CNN類似的方法,該方法優化了稀疏過濾器,而過濾器在多個尺度上對圖進行聚類操作。這篇文章還提出了CNN的譜近似方法,CNN中多個譜過濾器作用在對應最大特征值的特征向量上。
另外一篇文章[6]提出了一種和CNN更新具有相同的時間復雜度的GCN更新方案,即對譜過濾器只進行低度的多項式近似。還有一篇文章[7]通過使用多個線性譜過濾器簡化了GCN的公式,這些過濾器可以共同捕捉高階特征。
這些圖卷積網絡公式本身就很有趣,需要更多篇幅來詳細描述。GCN作為之前章節描述的圖處理方法的合理替代方案已經顯示出了前景。GCN的完全可微分的特征也使得其稀疏過濾器能夠成為端到端學習算法的一部分。雖然node2vec的偏置超參數(p, q)允許發現更多個性化的特征,但是GCN的權重矩陣也可以根據提供的訓練數據進行調整。
結構化學習已經被應用到生物化學領域,文章[8]提供了一種端到端的和全微分的神經網絡來預測基于稀疏原子結構的蛋白質-配體親和力。另一篇論文[9]用GCN解決了藥物發現問題,并引入了一個虛擬的“超級節點”,該虛擬的“超級節點”通過有向邊連接到候選藥物圖中的每個節點,以便得到圖特征。
GCN也已經成功應用在知識圖[10]的鏈接預測和實體分類等方面。最近出現的結構化學習的成功和快速的研究在未來幾年還會有更多。
也許我們很快就會看到利用關系結構如知識圖的GCN網絡來提高計算機視覺中物體檢測的性能,也或許,通過結構化學習方法能夠加速蛋白質折疊模擬,從而大大降低原子度低的三維蛋白質的維度等等。這些應用幾乎可以肯定將會出現(如果尚未發布的話),這當然使得結構化學習成為一個令人興奮的領域。
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103818 -
機器學習
+關注
關注
66文章
8507瀏覽量
134731
原文標題:前沿綜述:關系數據紛繁復雜,如何捕捉其中結構?
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
神經網絡專家系統在電機故障診斷中的應用
BP神經網絡的網絡結構設計原則
BP神經網絡與卷積神經網絡的比較
BP神經網絡與深度學習的關系
BP神經網絡在圖像識別中的應用
深度學習入門:簡單神經網絡的構建與實現
人工神經網絡的原理和多種神經網絡架構方法






 工商網監
工商網監

評論