 工業應用的自然語言理解和結構化知識
工業應用的自然語言理解和結構化知識
5月19日-20日,2018全球人工智能技術大會(GAITC)在北京國家會議中心隆重舉辦,全球業界頂尖領袖在此匯聚,圍繞AI熱點,分享AI領域最新洞見,引領年度行業發展風向標。
深知無限人工智能研究院首席科學家漢斯?烏思克爾特院士(Prof. Dr. Hans Uszkoreit)擔任本次大會主席。
以下內容為漢斯?烏思克爾特院士演講摘要:
?工業4.0智能工廠的3個層級:
智慧工廠
智慧運營服務
智能支持服務
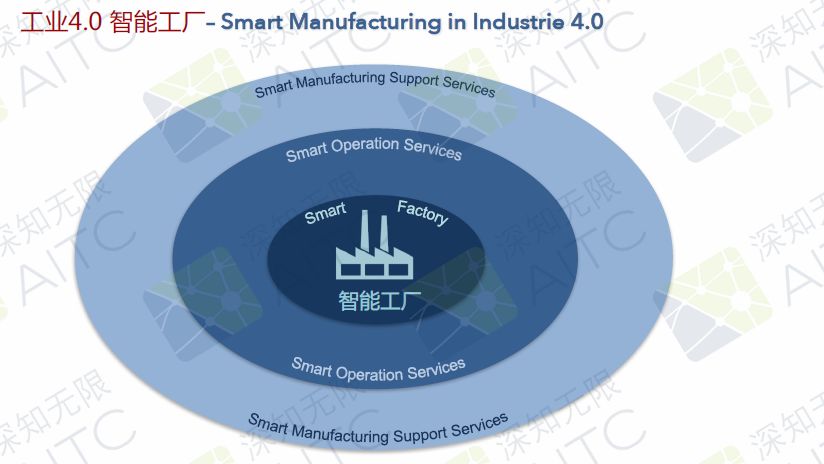
?智能工廠核心點
第一,網絡物理系統,包括傳感器、行動體、處理器,都和物聯網相連。通過數據的輸入,我們可以進行很多的學習,并對圖片進行很多的翻譯和理解,還可以進行相關的推理,進行快速的迭代和自動化。
第二,在工業4.0中,還有很重要的一點:Digital Twin技術--具有歷史/記憶的產品(或部件)的數字模型。Digital Twin主要是來自于語義產品記憶,在這個理念中,我們認為所有的部件都應該在自己的機器上有一個Digital Twin。一開始建立的模型并不是非常好,它們是使用一些結構化的語言以及模型,同時,人們也可以將自己的語言輸入到Digital Twin之中。通過Digital Twin,我們的機器可以為人所用,也可以被機器自己使用。
第三,柔性產品驅動的生產配置。比如我們的產品會告訴我們的機器它下一步需要做什么樣的步驟,比如去年到哪一個生產點進行怎么樣的加工。所以我希望我們整個的系統是柔性并且非常靈活的,而不是非常僵硬的。
第四,智能自動化機器人以及人機協同。
第五,基于AI的流程優化 - 預測資源利用率。我們可以使用預測性的資源,不光是預測性的維護,而且可以預測我們的能源使用、物料使用,可以預測所有和生產相關的資源。
這些都是通過我們與現實生產得到的學習結論。在DFKI,我們和很多工廠進行了合作,希望可以把我們的技術和想法放到這些工廠里進行實踐。
?智能運營服務
智能工廠的外層是智能運營服務,現在已經有了智能出行、智能物流、智能大樓、智能產品、智能電網,這些就是智能工廠外層的一些設施,他們會和生產密切相關。對于運行服務而言,它的重點和智能工廠或者智能手工生產是相當的。
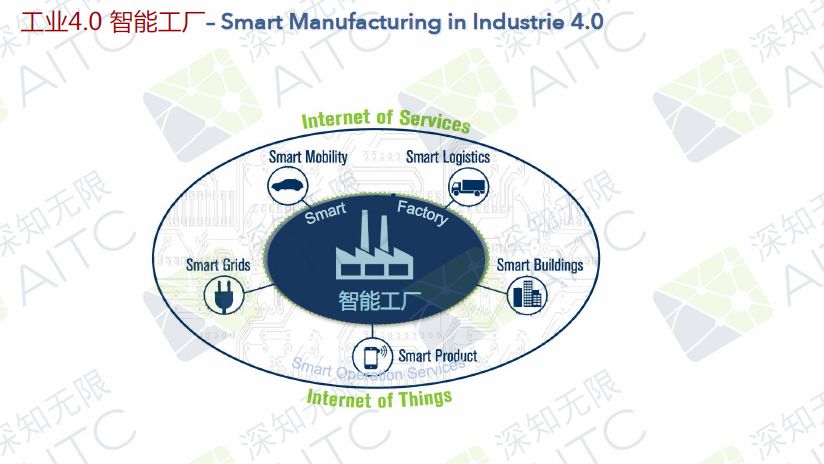
?智能支持服務
智能工廠的第三層——智能支持服務,我認為對于工廠而言,最重要的東西并不在工廠之內,很多在工廠工作的人覺得工廠或者產品是最重要的,但其實并非如此。產品的最終消費者是最重要的,以及供應商等,如果我的供應商對我停止供應,工廠會停產,還有投資人、監管者、技術提供商、服務合作伙伴等等都非常重要。
同時,語言也是至關重要的。我們需要從所有工廠以外的地方獲取很多的數據,并把這些數據應用于我們的工廠,比如進行產品研發、產品升級、生產計劃,比如我們希望看消費者需要的功能有哪些,消費者的理想定價是怎樣的,還需要看我們從供應商那里可以得到什么,因為如果沒有供應商,我們無法進行生產。
在這里有很多非結構性數據,智能工廠的第三層到第一層是相互貫穿的,一方面我們需要翻譯很多的數據、語言,理解很多來自于不同行動體或者合作伙伴的數據,另一方面我們也會把數據發給合作伙伴(如供應商),需要發給他們很多數據告訴他們我們所需要的規格是什么樣的,所以整個的結構非常復雜。通過這樣的合作可以獲得智能產品管理、智能客戶關系管理、智能產品經理、智能投資者管理、智能監管者管理、智能市場調查等等。
如何從外部獲得數據?有很多數據都來自于合作伙伴的數字內容,包括投資人、政府等等。我們在外部的數據,需要使用媒體、社交媒體、開放知識、開放數據。
例如:
①去年,大眾因為供應商出現了一些問題,他們并沒有及時獲得警告,而大眾花費了14個月來尋找替代供應商。
②我們之前在一個項目上可以和西門子合作,他們當時有19萬多的直接供應商,還有數百萬的間接供應商。我們希望能夠用我們的技術幫助他們,例如系統找出一些早期的預警信號。
知識圖譜
我們是整個開放數據庫,我們希望做一個橋梁連接公有和私有的知識庫,希望能夠在整個知識領域中,包括不同的百科網站(如維基百科)或者其他的知識管理項目中,把它們和工廠的私有知識庫連接起來,這樣就能以知識圖譜的方式構建這個大橋。比如說Google、必應、百度等不同類型的知識圖譜。為了把內部和外部的知識庫聯系在一起,通常會構建一個公司內部的知識圖譜,這樣才會有更多的可能。
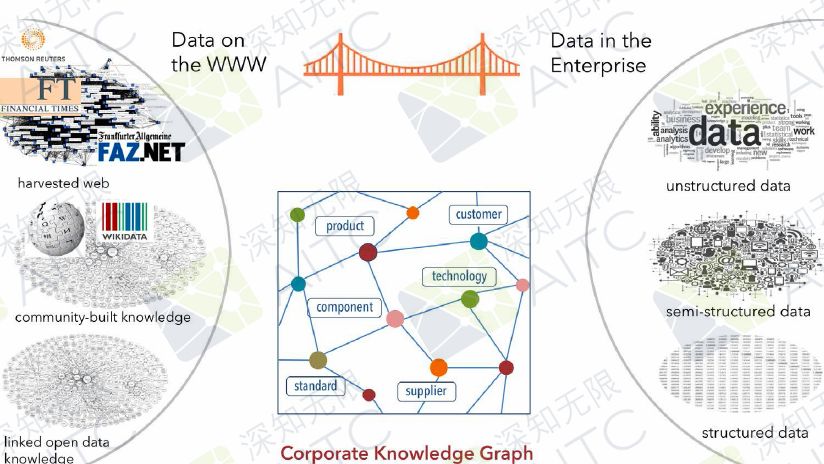
維基百科非常龐大,是一個巨大的數據庫。但維基百科所有的印刷版,公開發行的只有這么多,這也是我們為什么想真正實現線上瀏覽或者查詢。因為如果完全都做打印版的,對于語音學家或者知識領域的專家來說,很難實現突破。如果我們想做一些搜索和檢索會非常困難,并且有些知識是沒有辦法轉化為知識圖譜的。
我從Google的系統中截取了一個關于藝術領域的例子。由Google的知識圖譜所提供,并不是來自于某一個單一的文檔,而是一個結合。
針對大數據的NLP技術
?自然語言理解存在的2個問題
語言模糊性
同樣的句子,在一些語境下可能會有不同理解,比如某一個詞語、某一個句子可以有不同的解讀。比如“放”這個詞,如果去字典上查有很多不同的理解,或者時光如梭的英文也有不同的理解。人們對于解讀同一件事情的方式是千千萬萬的,大家都有不同的解讀,所以對于語言的解讀和翻譯非常困難。
我們在2008年做過一個研究,微軟買入了Powerset這個公司,其實可以用不同的詞語,比如說買入、收購或者其他的詞語,它可能只是用了非常模糊的詞,但我們知道他們是全資收購了,甚至是吞并。不同的詞語可以表達出相同的意思。對人們來說,他們可以想出不同類型的詞語,比如社交媒體上的人或者記者可能會根據自己的內容表達選擇一個最佳的詞語,但對于機器學習來說比較困難。
我們需要打造出一套基于統計學的機器學習、神經元學習,而且整個的潛力和挑戰都是前所未有的。如果我們學習了這些詞組,比如A收購B,我們需要讓機器理解,他究竟是獲得了某一個東西,還是真的收購了某一家公司。所以我們必須從這些句子中提取相應的信息。比如說它的價格、涉及到的公司,我們需要提取出正確關鍵的詞組。而且我們需要高亮出最關鍵的信息,還有一些簡單的信息,簡單的信息可以忽略不計,因為它可能會有變化。所以我們在分析語料時,我們會用綠色標注出最重要的信息是我們想讓機器去學習的。


超級學習技術
我們還會根據神經原的組成部分進行具體的語義解析,我們會提取信息做語義的篩選。因為可能一句話里,他說微軟投資了Powerset這家公司,他用了投資這個詞,但我們還要對整個信息做一些篩選和解讀。這樣才能把非結構化的信息真正的結構化。
我們之前也發表了很多的文獻和相應的專利,我們也在很多行業的應用上有所推廣,目前也在中國有一些合作的項目。我們還在不斷地更新、改進,現在也可以識別中文。同時我們也希望能夠覆蓋更多的語言。
-
人工智能
+關注
關注
1792文章
47375瀏覽量
238877 -
工業4.0
+關注
關注
48文章
2015瀏覽量
118678 -
自然語言
+關注
關注
1文章
288瀏覽量
13359
原文標題:2018GAITC演講實錄 | 漢斯?烏思克爾特:工業應用的自然語言理解和結構化知識
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學會】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論