 Watson是如何讀題的
Watson是如何讀題的
與人或大部分其他問答系統相似,Watson在處理問題的第一步是對問題進行仔細地分析,以了解提問者的意圖,并找到正確的方式去解決它。這也是非常關鍵的一步,后面的很多分析與計算都以此為基礎,這里主要用到了Watson的語法解析與語義分析能力,包括:深層的語法解析、實體識別、指代消解、關系抽取模塊。利用大量的規則與在此基礎上訓練的分類器,去檢測問題中以下幾個關鍵元素:
1)問題焦點(focus):問題中指代答案的部分;
2)答案的詞匯類型(lexical answer types):問題中指示被問到實體的類型的關鍵詞;
3)問題所屬的寬泛類型;
4)問題中需要特殊處理的部分。
下面會對這些元素逐一舉例介紹。
關鍵元素
焦點(focus)
問題中指代答案的部分,一般為代詞,如下列問題:POETS & POETRY: He was a bank clerk in the Yukon before he published "Songs of a Sourdough" in 1907.
中的He。這樣的詞在答案中可能有好幾個,但找到一個就夠了,其它的可通過指代消解的方式得到。找到”focus“以后,可以通過與包含答案的文章段落進行對齊,從而找到答案。
答案的詞匯類型(lexical answer types)
LAT指的是問題所問的是什么類型的實體,一般focus的中心詞即為LAT,如上例中的”he“與”clerk“,很多問題還提供了額外信息作為LAT,如上面問題的“poet”。(Jeopardy! 比賽中都給出了問題的種類)。得到LAT后可以用來檢驗算法給出的候選答案的類型是否正確。這樣不僅利用了問句本身的信息,還利用了比賽中關于問題種類的信息。
先預定義若干種問題,每種問題有不同的解決方法或處理流程。對問題進行分類,判斷它屬于某一種或幾種類型,再調用相應的處理流程。上面的問題屬于比較常見的仿真陳述(Factoid)問題。
問題片段(QSections)
問題中需要特殊處理的片段。QSections的一個典型應用是識別問題中關于答案的各種不同的約束(如答案是3個字,是地名),然后將問題分解為若干個字問題進行解答。
問題的基本分析
句法解析與語義分析
Watson的句法解析與語義分析模塊主要包含部分:包含謂詞論元結構構(PAS)造器的槽語法解析模塊ESG、命名實體識別模塊、指代消解模塊、關系抽取模塊。
ESG模塊是用來將問句解析為一個包含句子表層結構與深層邏輯結構的樹。每個節點上附有:1)一個詞項(由一個或若干個單詞組成)和與之對應的包涵邏輯參數的謂詞;2)特征列表,部分是關于句法形態的,部分是語義相關的;3)該節點的左右修飾語以及修飾語所填充的槽。1)中的謂詞與邏輯參數正是句子的深層結構之所在,邏輯參數為樹中其它節點,可能再句子上離當前節點比較遠
在上面的例子中可以識別出謂詞邏輯publish(e1, he, ‘‘Songs of a Sourdough’’) 與 in(e2, e1, 1907),后者說明了前者也就是這個pubilish事件發生在1907年。并且還可以抽取出authorOf(focus, ‘‘Songs of a Sourdough’’) 與 temporalLink(publish(. . .), 1907這樣的三元組關系。
針對Jeopardy!問題所做調整
1)Jeopardy!問題的單詞全都是大寫,對人來說沒什么,然而單對用計算機進行語法分析來說,大小寫是非常重要的信息,所以先用一個在其它數據集上訓練的分類器來對單詞的大小寫進行預測與改寫。
2)Jeopardy!問題的語言習慣與日常領域有著較大差異,例如日常問句一般以“Wh-”開頭,但在Jeopardy!中卻喜歡用this/these、he/she、it等。此外Jeopardy!中名詞短語出現的頻次非常高。因此在解析Jeopardy!的問句時需要調整解析模型的參數,如增加名詞短語的先驗或轉移概率。
3)問題的focus往往是個代詞,所以在進行分析時先識別出focus再將focus排除在外進行指代消解。
關系抽取做的調整
為了應對Jeopardy!特殊的語言風格,對原本用于普通文本的關系抽取模塊做了調整。這樣一方面能檢測出在Jeopardy!的問題中經常出現的對后面的處理特別有用的一些關系,如focus的別名、時間關系、地理位置關系等,具體例子如下表。

另一方面,用來匹配這些關系等模式,也已可以用來識別出問句的一些特定特征,這些特征可以用于訓練問題的分類器或其他處理。那么這些規則時如何實現的呢?下面將開始介紹。
規則的Prolog實現
Watson的問題分析流程是通過由一系列組件組成的UIMA Pipeline實現的,而大部分的分析流程都是一些基于句子的PAS結構與一些外部數據庫(如WordNet)的規則實現的。這就需要一門語言,一方面能夠基于句法解析的結果很方便的實現這些規則,另一方面又能很容易地集成到UIMA框架中,Prolog作為一種邏輯式編程語言,是一個很好的選擇。它可以很方面地將UIMA中的CAS數據結構轉換成fact對象。
例如對于以下是基于句法與語義分析的結果轉換成的fact:
lemma(1, ‘‘he’’)partOfSpeech(1,pronoun)lemma(2, ‘‘publish’’)partOfSpeech(2,verb)lemma(3,‘‘Songs of a Sourdough’’)partOfSpeech(3,noun)subject(2,1)object(2,3)
其中括號里面的數字是PAS節點的唯一標識。有了這些fact,Prolog系統可以利用一些規則去識別問題的focus、LAT與其他關系(relation)。例如將如下規則:
authorOf(Author, Composition) :- createVerb(Verb), subject(Verb, Author), author(Author), object(Verb, Composition), composition(Composition).-
createVerb(Verb) :- partOfSpeech(Verb, verb), lemma(Verb, VerbLemma), [‘‘write’’, ‘‘publish’’, . . .].
應用到各個節點上,可以識別出關系authorOf(1,3)。使用Prolog無論在系統運行速度還是規則的可擴展性上表現都是非常優秀的。在關系抽取、focus檢測、LAT檢測、問題分類與Qsection檢測等任務上都有各自的規則集,這些規則使用了超過6000條的Prolog語句,整個問題分析的UIMA Pipeline如下。

focus與LAT檢測
基本方法
匹配focus的基本規則按照優先級排序如下所示,其中斜體詞表示focus,黑體詞表示中心詞:
1)帶有限定詞“this”或“these”的名詞短語: THEATRE: A new play based onthisSir Arthur Conan Doyle canineclassicopened on the London stage in 2007.
2)“This”或“these”本身作為名詞短語: In April 1988, Northwest became the first U.S. air carrier to banthison all domestic flights.
3)當整個問句是一個名詞短語時,將整個問句都標記為focus:AMERICAN LIT:Numberof poems Emily Dickinson gave permission to publish during her lifetime.
4)代詞“he/she/his/her/him/hers”中的一個:OUT WEST:Shejoined Buffalo Bill Cody’s Wild West Show after meeting him at the Cotton Expo in New Orleans.
5)代詞“it/they/them/its/their”中的一個:ME "FIRST"!:Itforbids Congress from interfering with a citizen’s freedom of religion, speech, assembly, or petition.
6)代詞“one”:12-LETTER WORDS: Leavenworth, established in 1895, is a federalone.
當這些規則都不滿足時,問題可能就沒有focus。這種規則對句法解析有很高的要求,例如解析器需要能夠準確的將限定詞與中心詞關聯起來(兩者并不是都是毗鄰的),并且能準確地區分名詞短語與動詞短語也很重要,所以特地對ESG解析模塊進行了調整。
檢測LAT的方法一般是采用focus的中心詞,并加上下面幾條例外:
1)如果focus是一個組合, 采用這個組合部分: HENRY VIII: Henry destroyed the Canterbury Cathedral Tomb ofthissaintandchancellorof Henry II.
2)如果存在“ of X”這種模式,并且是“one/name/type/kind”中的任何一個,那么采用X作為LAT:HERE, PIGGY, PIGGY, PIGGY: Many a mom has compared her kid’s messy room tothis kind of hogenclosure.
3)如果存在“ for X”這種模式,且是“name/word/term”中的任何一個,那么采用X作為LAT:COMPANY NAME ORIGINS: James Church chosethis name for hisproductbecause the symbols of the god Vulcan represented power.
4)如果沒有檢測到focus,且category是一個名詞短語,那么采用category的中心詞作為LAT:HEAVY METALBANDS: "Seek & Destroy", "Nothing Else Matters", "Enter Sandman".
提升方法
上面介紹的基本方法已經可以取得相對中肯的精度,但錯誤也是并不少見,經常會漏過一些有用的LAT。下面就是一些基本方法失敗的案例來講述提升方法或補充方法:
1) PAIRS: An April 1997 auction of Clyde Barrow’s belongings raised money to fund moving his grave next tohers.
2) FATHER TIME (400): On Dec. 13, 1961, Father Time caught up withthis 101-year-old artistwith a relative inhernickname.
3) CRIME: Cutpurse is an old-time word for this typeof crowd-workingcriminal.
4) THE FUNNIES: “Marmaduke’’ isthis breed ofdog.
5) ISLAND HOPPING: Although most Indonesians are Muslims,thisis the predominantreligionon Bali.
6) I FORGET: Mythicalriversof Hades include the Styx andthis onefrom which the dead drank to forget their lives.
7) FAMOUS AMERICANS: Although he made no campaign speeches,hewas electedpresidentin 1868 by a wide electoral margin.
例1)中第一個代詞his并非focus,因為它指代實體“Clyde Barrow”,所以在應用基本方法找到多個代詞作為候選focus時,應該選擇不指代任何實體的代詞。找到focus后可以利用前指代消解模塊幫我們找到指示答案性別的LAT。
例3)與4)中focus表達了一種子類關系,我們將這個子類從介詞短語中剝離出來作為LAT。
在檢測LAT時,還有一個困難是決定LAT是一個還是多個詞。大部分情況下我們認為LAT是一個詞,但在“this vice president”這種情形如果采用“president”作為LAT是錯誤的。因此,如果多個單詞(修飾詞+中心詞)不是其中心詞的一個子類型或者修飾語改變了中心詞的意思并且這種意思并不常見,這時采用多個詞作為LAT。
從問題的category中獲取LAT
通過觀察得知,一般情況下,如果category中的詞滿足以下三個條件則很可能是一個LAT:
1)涉及到實體的類型;
2)這個實體的類型與問句中的LAT(如果有的話)一致;
3)這種類型在問題中沒有任何提及(mention)或實例。
例如問題:
BRITISHMONARCHS:Shehad extensive hair loss by the age of 31. 的category中的“MONARCHS”(君主)表示實體的類型,并且與問句中的LAT(she)一致,所以它也是一個LAT。
估計LAT的置信度
利用人工標注的LAT數據,基于如下幾種特征來訓練一個邏輯回歸模型來對線上檢測到的LAT進行打分,作為其置信度:
1)被激活的focus與LAT規則;
2)從句法分析與NER的結果中構建的特征;
3)該單詞作為LAT的先驗概率。
統計糾偏
先離線統計出各種category的問題中category中的各個詞作為LAT的頻率,并且以這個頻率作為其置信度(不用上面的邏輯回歸模型進行打分)。過濾掉過低置信度的詞,并且根據前面的規則是否檢測到LAT分別統計這兩種情形下的置信度。這樣有可能召回前面規則漏掉的LAT。
效果評估
用基本方法與采用了這里展示的幾種提升方法的Watson分別在手工標注的9128個問題上的進行評估,得到的結果如下:
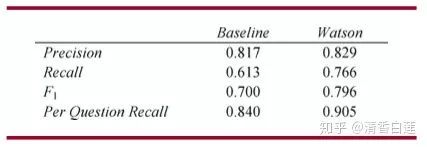
可見提升方法還是有顯著效果的,尤其是在召回率(Recall)上。
問題分類與Qsection檢測
Jeopardy! 的問題有很多種類,統一用一種方法來處理效果并不理想,并且問題的部分片段可能有著特殊作用,如果能做針對性的處理對提升準確性也是有益的。所以對問題進行分來并檢測出這些特殊的片段是問題分析中重要的一步。
問題分類
Watson默認的回答問題的方式是針對仿真陳述問題(Factoid Question)的,然而有些問題根本無法使用這種方式去回答,還有部分問題雖然不是不能用默認的方式去回答,但經過分類處理,做針對性的分析也會更好地解答。通過對3500個Jeopardy!的問題進行人工聚類,得到的問題分類與占比如下表所示。

檢測問題類型的方式主要是通過正則表達式、句法規則等模式匹配的技術,所以一個問題可能匹配上多種類型。當然這些類型中部分之間存在互斥,所以匹配完成之后,如果匹配上的類型中有互斥的,要去掉互斥對中置信度較低的哪個類型。
上表所示的問題類型(QClass)中PUZZLE、BOND、FITB (Fill-in-the blank)、BOND與MULTIPLE-CHOICE的表示方式相對固定,所以用正則表達式去匹配。對于其他的QClass,由于沒有固定的表達方式,所以通過基于PAS結構的句法規則去匹配,具體如下:
ETYMOLOGY:包含“From for , ...,”或其它類似模式;
VERB:focus通常是“do”的賓語或者是包含不定式的定義式問題(如“This 7-letter word means to presage or forebode”);
TRANSLATION:包含模式“ is for “或或者問題是只是一個沒有focus的短語并且其category確定了一門語言。
NUMBER與DATE:如果LAT中包含數字或日期的實例;
DEFINITION:關鍵短語“is the word for”與“Bmeans”以及經常出現的category如“CROSSWORD CLUES”;
CATEGORY-RELATION:問句僅僅是一個實體或一串實體(沒有檢測到focus);
ABBREVIATION:并不是包含縮寫的問題都是ABBREVIATION類問題,這里的識別方法與識別LAT類似。先制定一些規則,包括正則表達式與句法規則。然后以這些規則以及當前category是ABBREVIATION類型問題的先驗概率作為特征訓練一個邏輯回歸模型來判斷當前問題是否是ABBREVIATION類型。如果是再用專門的方法求出全稱,這種方法詳見參考文獻[2],后面也會專門介紹。
檢測Qsection
QSection是指問句(偶爾在category中)中對問題的解釋有著特殊功能的連續區域。與問題分類類似,QSection的檢測也是通過正則表達式與PAS結構上的句法規則實現的。其中比較重要的QSection有:
1)LexicalConstraint:對答案的詞匯方面做限制的短語,如”this 4-letter word“ ,這對答案的選擇有重要作用;
2)Abbreviation:被識別為縮寫的詞項,并與其可能的全稱進行關聯。對于QClass為ABBREVIATION的問題,有一個abbreviation的全稱即為答案,需要被識別出來做更加精準的分析來確定答案;
3)SubQuestionSpan:當原問題可以被分解若干個片段,每一個片段可以單獨對答案產生影響,這些單獨的片段即為SubQuestionSpan。這種通過對原始問題進行分解的求解方式后面會做專門介紹;
4)McAnswer:多選問題中表示答案的選擇的字符串(經常3個);
5)FITB:與focus毗鄰的字符串(如focus的補充成分)。
效果評估
基于3500個人工分類的問題對分類方法進行評測,得到的結果如下表所示:
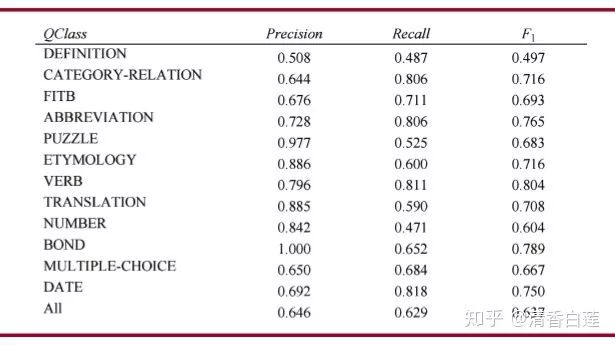
DEFINITION識別起來比較困難,然而實際上這種問題直接中默認的Factoid方式進行回答,問題不是特別大。PUZZLE的召回率較低時由于其類型的長尾分布,導致規則覆蓋不夠。
將Watson的問題分類與特殊片段的檢測功能移除與完整狀態進行評測對比如下,可見這種處理能讓Watson多答對2.9%(有focus與LAT檢測功能)的問題。

結論
通過上面的評測結果可知,與只有基本的focus、LAT檢測功能的Basline問題分析流程相比,集成了本文介紹的全部focus檢測、LAT檢測、問題分類與QSection檢測模塊功能的分析流程可以使Watson多答對5.9%的問題。這個Gap對能否戰勝人類選手是非常重要的。
-
IBM
+關注
關注
3文章
1755瀏覽量
74680 -
Watson
+關注
關注
0文章
17瀏覽量
9503
原文標題:IBM Watson揭秘:問題分析-Watson是如何讀題的
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
工業級讀碼器用固定焦距還是變焦好?

工業讀碼器解決方案在自動化流水線上掃描條碼的應用

二維碼識讀設備有哪些類型


工業讀碼器 流水線讀碼報警案例,掃碼OK亮綠燈,掃碼NG亮紅燈!如果您有讀碼器的需求和應用,歡迎聯系深圳遠景達

工業讀碼器 S180超快的解析速度,更適合動態讀碼場景,如果您有相關工業讀碼器的需求和應用,歡迎聯系深圳遠景達

R3000讀碼器,結構緊湊,支持多通訊協議!#流水線讀碼器 如果您有讀碼器的需求和應用,歡迎聯系深圳遠景達。
生產線用條碼讀碼器介紹

掃碼模組的識讀模式及應用場景

固定讀碼器怎么選型 工業二維碼讀碼器推薦

揭秘RFID標簽漏讀真相,如何減少RFID標簽漏讀問題


內核(linux-3.12)的文件系統預讀設計和實現
基于相機技術的工業級多碼讀碼器——DC200讀碼器






 工商網監
工商網監
評論